分布式理论(六)Raft协议
拜占庭将军问题:在已知有成员不可靠的情况下,其余忠诚的将军需要在不受叛徒或间谍的影响下达成一致的协议。Raft算法是解决其问题的方案之一。
Raft算法 - 易于理解的一致性算法。
什么是Raft算法?
Raft算法是一种用于管理复制日志的一致性算法,其功能与 Paxos算法相同类似,但其算法结构和 Paxos算法不同,在设计Raft算法时设计者就将易于理解作为其目标之一,这使得Raft算法更易于构建实际的系统,大幅度减少了工程化的工作量,也方便开发者此基础上进行扩展。
管理复制日志:一致性算法是从复制状态机的背景下提出的,复制状态机通常都是基于复制日志实现的,这个日志可以理解为一个比喻,相当于一个指令。保证复制日志相同即一致性算法的工作。
Leader选举
Raft 通过选举一个leader,然后给予他全部的管理复制日志的责任来实现一致性。
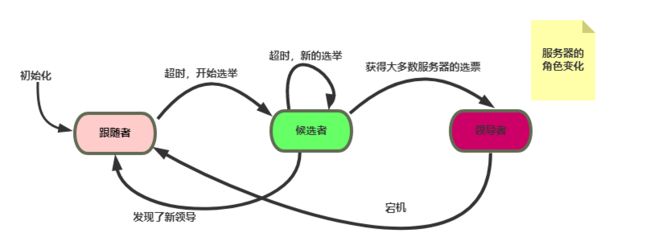
1. 三种状态:领导者、跟随者、候选者;
每个server即在这三个身份之间进行切换,通过选举影响身份变换。
每个状态的职责
| 状态 | 职责 |
| 领导者 Leader |
处理所有客户端的请求(写入请求、只读请求),定期向跟随者发送心跳消息。 |
| 跟随者 Follower |
不会发送任何请求,只是简单地响应来自 Leader或者 Candidate的请求,不处理客户端请求。 |
| 候选者 Candidate |
由 Follower节点转换而来的。长时间没有收到领导者发送的心跳消息时,会选举产生新的领导者。 |
三个状态之间的转换即选举过程,具体的选举过程之后讲解,状态转换图如下:

2. 任期(term)
由于机器的物理时间是不可靠的,因此需要一个逻辑时间,称之为任期。实际上任期就是一个全局的、连续递增的整数,在Raft协议中每进行一次选举,任期加一,在每个节点中都会记录当前的任期值。每一个任期都是从一次选举开始的,在选举时,会出现一个或者多个 Candidate节点尝试成为 Leader节点,如果其中一个 Candidate节点赢得选举,则该节点就会切换为 Leader状态并成为该任期的 Leader节点,直到该任期结束。
任期包含有两个阶段:选举阶段和正常运行阶段。若选举失败了,会进行加时赛,即连续有 2 个选举过程。
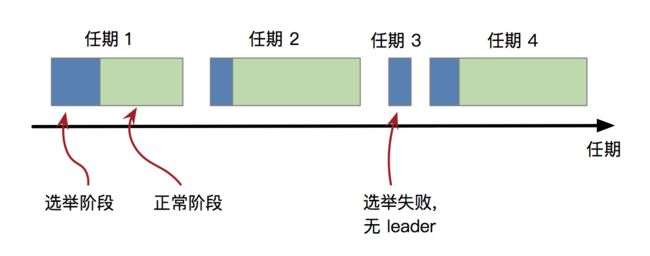
有关任期的几个特点:
- 节点有可能观察不到任何一次选举或者任期。
- 任期充当逻辑时钟,服务器节点可以通过任期号查明过期的领导者或过期的信息。
- 每个节点存储当前任期号,单调递增。
- 服务器之间的每次通信,都会交换当前任期号。
交换任期号的目的:
- 如果一个服务器的当前任期号比其他人小,则更新自己。
- 如果一个候选人或者领导人发现自己的任期号过期了,立刻将自己变成跟随者状态。
- 如果一个节点收到一个过期的任期号的请求,直接拒绝。
3. 选举的过程
控制选举发生的两个时间控制:选举超时时间以及心跳超时时间。
选举超时时间
每个 Follower节点在接收不到领导者的心跳消息之后,并不会立即发起新一轮选举,而是需要等待一段时间之后才切换成 Candidate状态发起新一轮选举。这段等待时长就是这里所说的选举超时时间election timeout,该时间一般置为150ms~300ms之间的随机数。
心跳超时时间
领导者节点向集群中其他跟随者节点发送心跳消息的时间间隔。
选举过程如图:当集群初始化时,所有节点都处于 Follower的状态,此时的集群中没有 Leader节点。当Follower节点一段时间(选举计时器超时)内收不到 Leader节点的心跳消息,则认为 Leader节点出现故障导致其任期过期, Follower节点会转换成 Candidate状态,发起新一轮的选举。
在选举过程中,发起选举的节点首先会递增自己的任期值并将自己的选票投给自己,并会向集群中其他节点发送选举请求以获取其选票,其他节点均未投出新发起任期的选票时,会在接收到发起选举的节点的选举请求后会将选票投给该节点,同时递增自身记录的Term值,并将选举自己的定时器重置,防止一个任期中同时出现多个 Candidate节点,导致选举失败。
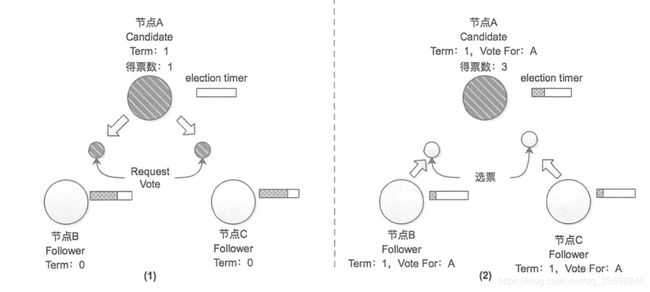
在发起选举的节点收到了集群中超过半数的选票后,在新的这个任期中,该集群的 Leader节点就是该节点,其他节点将切换成 Follower状态。
选举的特殊情况:
- 有两个或两个以上的选举计时器同时过期
这些节点会同时由 Follower状态切换成 Candidate状态,然后同时触发新一轮选举,在该轮选举中,每个Candidate节点获取的选票都不到半数,无法选举出 Leader节点,在这种情况下,这个任期会以选举失败结束,随着时间的流逝,当任意节点的选举计时器到期之后,会再次发起新一轮的选举。而election timeout是在一个时间区间内取的随机数,所以在配置合理的时候,该情况多次出现的概率并不大。(对应上图中的任期3 - 任期4)
- 领导者宕机后的选举
领导者宕机后,其他节点在新的任期中选举出新的领导者节点,当之前的领导者节点恢复时,收到新的领导者节点发送的心跳包,此时接收的消息的任期号大于本身记录的任期号,则该节点更新自身记录的任期号,同时会切换为 Follower状态并重置选举计时器。当某个节点接收到的消息所携带的任期号大于当前节点本身记录的任期号,那么该节点会更新自身记录的任期号,同时会切换为 Follower状态并重置选举计时器,这是Raft算法中所有节点都要遵守的一条准则。
- 网络分区的Leader选举
如果网络分区时, Leader节点划分到节点较多的分区中,如图2-23所示,此时节点较少的分区中,会有节点的选举计时器超时,切换成 Candidate状态并发起新一轮的选举。但是由于该分区中节点数不足半数,所以无法选举出新的 Leader节点。待一段时间之后,该分区中又会出现某个节点的选举计时器超时,会再次发起新一轮的选举,循环往复,从而导致不断发起选举,Term号不断增长。
在Raft协议中对这种情况有一个优化,当某个节点要发起选举之前,需要先进入一个叫作PreVote的状态,在该状态下,节点会先尝试连接集群中的其他节点,如果能够成功连接到半数以上的节点,才能真正发起新一轮的选举。
日志复制
Leader节点除了向 Follower节点发送心跳消息,还会处理客户端的请求,并将客户端的更新操作以消息( Append entries消息)的形式发送到集群中所有的 Follower节点。当 Follower节点记录收到的这些消息之后,会向 Leader节点返回相应的响应消息。当 Leader节点在收到半数以上的 Follower节点响应消息之后,会对客户端的请求进行应答。最后, Leader会提交客户端的更新操作,该过程会发送 Append Entries消息到 Follower节点,通知 Follower节点该操作已经提交,同时 Leader节点和 Follower节点也就可以将该操作应用到自己的状态机中。
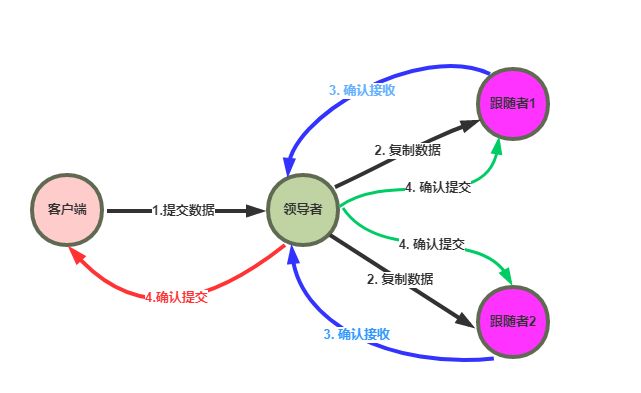
完成日志复制的数据结构
集群中各个节点都会维护一个本地Log用于记录更新操作,除此之外,每个节点还会维护 commitIndex和 lastApplied两个值,它们是本地Log的索引值。当节点中的 commitIndex值大于lastApplied值时,会将 lastApplied加1,并将 lastApplied对应的日志应用到其状态机中。
| 索引值 |
表示意义 |
| commitIndex |
表示的是当前节点已知的、最大的、已提交的日志索引值 |
| lastApplied |
表示的是当前节点最后一条被应用到状态机中的日志索引值 |
在 Leader节点中不仅需要知道自己的上述信息,还需要了解集群中其他 Follower节点的这些信息,例如, Leader节点需要了解每个 Follower节点的日志复制到哪个位置,从而决定下次发送 Append Entries消息中包含哪些日志记录。为此, Leader节点会维护 nextIndex[]和matchIndex[]两个数组,这两个数组中记录的都是日志索引值。
| 数组 |
表示意义 |
| nextIndex数组 |
表示记录了需要发送给每个 Follower节点的下一条日志的索引值 |
| matchIndex数组 |
表示记录了已经复制给每个Follower节点的最大的日志索引值 |
复制日志操作:
Leader节点与某一个 Follower节点复制日志时, Follower节点中最后一条日志的索引值大于等于Leader节点消息中该Follower节点对应的nextIndex值,那么通过 Append entries消息发送从 nextIndex开始的所有日志。之后,Leader节点会检测该 Follower节点返回的相应响应,如果成功则更新相应该 Follower节点对应的nextIndex值和 matchIndex值;如果因为日志不一致而失败,则减少 nextIndex值重试。直到节点返回追加成功的响应,之后进入正常追加消息记录的流程(Follower节点自身与消息中的index进行比较)。
当Leader节点并未发生过切换,所以Leader节点始终准确地知道节点C对应nextlndex值和matchlndex值。若下图在节点C故障恢复后(日志缺失),Leader节点A宕机后重启,并且导致节点B成为新任期(Term=2)的Leader节点,则此时节点B并不知道旧Leader节点中记录的nextlndex[]和matchlndex[]信息,所以新Leader节点会重置nextlndex[]和matchlndex[],其中会将nextlndex[]全部重置为其自身Log的最后一条己提交日志的Index值,而matchlndex[]全部重置为0。(为此才会导致:上述所说的日志不一致而失败,则减少 nextIndex值重试)


对于选举Leader的补充
保证了己提交的日志记录不会丢失,Follower节点还需要比较该Candidate节点的日志记录与自身的日志记录,拒绝那些日志没有自己新的Candidate节点发来的投票请求,确保将选票投给包含了全部己提交日志记录的Candidate节点。
Candidate节点为了成为Leader节点,必然会在选举过程中向集群中半数以上的节点发送选举请求,因为己提交的日志记录必须存在集群中半数以上的节点中,这也就意味着每一条己提交的日志记录肯定在这些接收到节点中的至少存在一份。也就是说,记录全部己提交日志的节点和接收到Candidate节点的选举请求的节点必然存在交集。

在比较两个节点的日志新旧时,Raft协议通过比较两节点日志中的最后一条日志记录的索引值和任期号,以决定谁的日志比较新:首先会比较最后一条日志记录的任期号,如果最后的日志记录的任期号不同,那么任期号大的日志记录比较新;如果最后一条日志记录的任期号相同,那么日志索引较大的比价新。
客户端与集群的交互过程以及日志复制
集群中只有Leader节点可以处理客户端发来的请求,当Follower节点收到客户端的请求时,也必须将Leader节点信息告知客户端,然后由Leader节点处理其请求,具体步骤如下:
(1)当客户端初次连接到集群时,会随机挑选一个服务器节点进行通信。
(2)如果客户端第一次挑选的节点不是Leader节点,那么该节点会拒绝客户端的请求,并且将它所知道的Leader节点的信息返回给客户端。
(3)当客户端连接到Leader节点之后,即可发送消息进行交互。
(4)如果在交互过程中Leader节点宕机,那么客户端的请求会超时,客户端会再次随机挑选集群中的节点,并从步骤1重新开始执行。
【注意】出现网络分区之后,若leader节点无法将请求发送到集群中超过半数的节点上,该请求相应的日志记录也就无法提交,从而导致无法给客户端返回相应的响应,客户端发往leader节点的请求将会超时。
分区网络恢复之后,由于之前的网络分区,节点的本地Log中可能存在未提交的日志记录,此时节点会回滚未提交的日志记录,并重新复制新Leader节点的日志,来保证整个集群的日志一致。
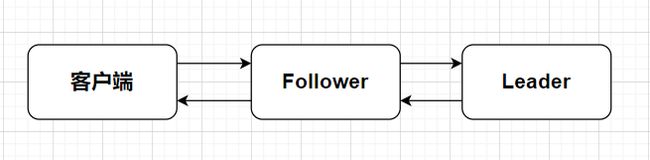
在Raft协议的论文中,还给出了另一种proxy的方案:假设客户端连接到集群中的某个Follower节点,该Follower节点会将客户端发送的所有请求转发给Leader节点进行处理,当Leader节点响应Follower节点之后,再由Follower节点响应客户端。当出现请求超时的情况时,客户端同样需要随机选择新的节点进行连接。
参考:
《etcd技术内幕》第二章 - Raft协议
Raft 基础:https://www.cnblogs.com/stateis0/p/9993170.html
分布式理论(六)—— Raft 算法:https://www.cnblogs.com/stateis0/p/9062131.html