scriptOJ--你能做对下面这道题吗?
scriptOJ 是首个 Web 前端开发评测系统,上面有很多前端题目,也涉及到算法,是前端er 的 OJ 系统,没用过的小伙伴可以尝试下。
很早就听说这个网站了,不过开局第一题一直写不出来,今天又看了一下总算是搞定了,在我的解法中用到了比较多的有关正则方面的知识,在这里总结一下。
下面就是进入首页会看到的第一题(好像定期会更换):
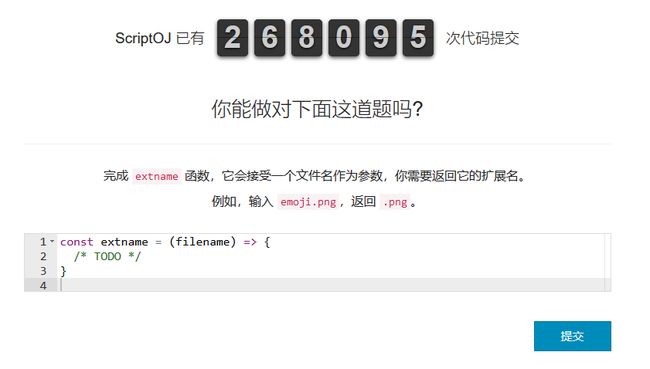
下面是我的解法:
const extname = (filename) => {
let re = /\.[a-zA-Z]+/ig;
if (re.test(filename)) { // 第一次匹配
if (RegExp.leftContext == '') { // 第一次匹配左边没有字符(只有后缀名)
return '';
}
let a = filename.match(re); // match会将匹配到的所有字符储存在一个数组中并返回
return a[a.length - 1]; // 返回最后一次匹配到的字符串
} else {
return ''; // 没有匹配到任何后缀名,直接返回空字符串
}
}
用于测试的数据大概有这么几种:
var str1 = 'test.ms.hello.jpg'; // 有很多 . 分割的字符串,但只有最后一个才是后缀名
var str2 = '.png'; // 只有后缀名,要求返回一个空字符串
var str3 = 'hello'; // 没有后缀名,要求返回一个空字符串
全面总结一下解题中与正则相关的知识:
- RegExp构造函数的属性
input:用于匹配的字符串lastMatch:最近一次匹配到的字符串lastParen:最近一次匹配到的捕获组leftContext:input中lastMatch之前的字符串rightContext:input中lastMatch之后的字符串multiline:匹配是否用于多行模式
举例:
var str= "this has been a short summer";
var re= /(.)hort/g;
if (re.test(str)) {
console.log(RegExp.input); // this has been a short summer
console.log(RegExp.lastMatch); // short
console.log(RegExp.lastParen); // s
console.log(RegExp.leftContext); // this has been a
console.log(RegExp.rightContext); // summer
console.log(RegExp.multiline); //false
}
解题中用到了:leftContext属性,通过判断第一次匹配之前是否有字符串,来判断是不是只有后缀名这种情况。
- RegExp实例的方法
test()exec()
用法:re.test(str); re.exec(str)
re表示正则表达式的实例,str表示用于匹配的字符串
test() 方法返回boolean类型的值,匹配到返回true,未匹配到返回false
exec() 方法没有匹配到时返回null,匹配到时返回一个数组。该数组额外具有两个属性:index和input。index指匹配项在字符串中的位置,input指用于匹配的字符串。
exec方法返回的数组中第一项就是匹配到的字符串 :
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/ig;
var a = re.exec(str);
console.log(a[0]); // .ms
当不使用全局模式时,多次调用 exec() 得到的结果都是只返回第一次匹配的结果 :
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/i;
var a = re.exec(str);
console.log(a[0]); // .ms
a = re.exec(str);
console.log(a[0]); // .ms
a = re.exec(str);
console.log(a[0]); // .ms
但是,当使用全局模式时,多次调用 exec() 时,每次调用exec() 都会返回字符串中下一个匹配项 :
// 匹配项的改变与后面讲到的lastIndex属性相关联
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/ig;
var a = re.exec(str);
console.log(a[0]); // .ms
a = re.exec(str);
console.log(a[0]); // .hello
a = re.exec(str);
console.log(a[0]); // .jpg
- RegExp实例属性
globalignoreCasemultilinelastIndexsource
global,ignoreCase,multiline就是表达式是否设置了g,i,m 标志
lastIndex:表示开始搜索下一个匹配项的字符位置,从0算起。
source:正则表达式的字符串表示。
比如:
var re = /\.[a-zA-Z]+/ig;
console.log(re.global); // true
console.log(re.ignoreCase); // true
console.log(re.multiline); // false
console.log(re.lastIndex); // 0
console.log(re.source); // \.[a-zA-Z]+
在全局模式下,当每次执行test(),exec()方法后,lastIndex都会增加。而在非全局模式下则始终保持不变。
比如:
// 全局模式下
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/ig;
console.log(re.lastIndex); // 0
re.test(str);
console.log(re.lastIndex); // 7
re.test(str);
console.log(re.lastIndex); // 13
re.test(str);
console.log(re.lastIndex); // 17
// 非全局模式下
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/i;
console.log(re.lastIndex); // 0
re.test(str);
console.log(re.lastIndex); // 0
re.test(str);
console.log(re.lastIndex); // 0
re.test(str);
console.log(re.lastIndex); // 0
- String的 match() 方法
基本用法:
// 非全局模式下
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/i;
var a = str.match(re);
console.log(a); // .ms
// 全局模式下
var str = 'test.ms.hello.jpg';
var re = /\.[a-zA-Z]+/ig;
var a = str.match(re);
console.log(a); // Array(3) [ ".ms", ".hello", ".jpg" ]
比较match()和exec():
相同点:
非全局模式下,两者的返回值只有一个匹配项。
不同点:
1、exec是RegExp的方法,match是String的方法
2、全局模式下,match一次返回所有匹配项。exec仍然返回一个匹配项,但每次调用都会返回后面的匹配项。
以上 ?