图像分类(ResNet模型)
图像分类(ResNet模型)
模型完成图像分类:

3-d张量 —》 字符串
- 复杂运算 outputs=resnet18(img_tensor)
- 取输出向量最大值的标号 _,predicted=torch.max(outputs.data,1)
- 类别名与标签的转换 label_name={“ants”:0,“bees”:1}

图像分类由模型与人类配合完成:
- 模型:将数据映射到特征
- 人类:定义特征的物理意义,解决实际问题

图像分类步骤:
- 获取数据与标签
- 选择模型、损失函数、优化器
- 训练代码
- inference
获取数据与模型
数据变换,如RGB–》4D-Tensor
前向传播
输出保存预测结果
注意事项:
确保model处于eval状态而非training
设置torch.no_grad(),减少内存消耗
数据预处理保持一致,RGB or BGR
传统经典的卷积神经网络:
- alexnet (2012 先驱)
- vgg
- googlenet
- inception
- resnet
- densenet
轻量化经典卷积神经网络
- mobilenet
- shufflenetv2
- squeezenet
神经网络自动搜索结构
- mnasnet
ResNet基本结构

Resnet18:(18由18个带有权值的网络层决定)
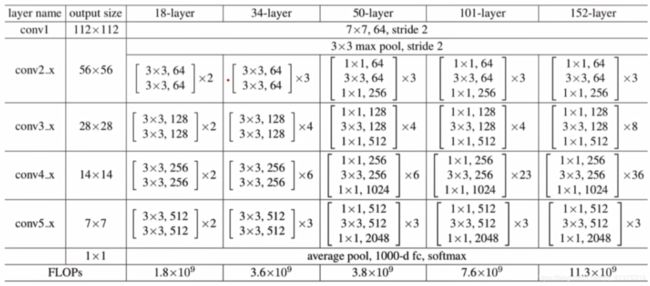
一层有两个基础块,一块有两个层,4*2*2=16
1层conv1
1层fc
共18层
def resnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
# [2, 2, 2, 2] 对应了基础块
def resnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# -*- coding: utf-8 -*-
"""
# @file name : resnet_inference.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2019-11-16
# @brief : inference demo
"""
import os
import time
import torch.nn as nn
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
# config
vis = True
# vis = False
vis_row = 4
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
classes = ["ants", "bees"]
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def get_img_name(img_dir, format="jpg"):
"""
获取文件夹下format格式的文件名
:param img_dir: str
:param format: str
:return: list
"""
file_names = os.listdir(img_dir)
img_names = list(filter(lambda x: x.endswith(format), file_names))
if len(img_names) < 1:
raise ValueError("{}下找不到{}格式数据".format(img_dir, format))
return img_names
def get_model(m_path, vis_model=False):
resnet18 = models.resnet18()
num_ftrs = resnet18.fc.in_features
resnet18.fc = nn.Linear(num_ftrs, 2)
checkpoint = torch.load(m_path)
resnet18.load_state_dict(checkpoint['model_state_dict'])
if vis_model:
from torchsummary import summary
summary(resnet18, input_size=(3, 224, 224), device="cpu")
return resnet18
if __name__ == "__main__":
img_dir = os.path.join("." ,"bees")
model_path = "./checkpoint_14_epoch.pkl"
time_total = 0
img_list, img_pred = list(), list()
# 1. data
img_names = get_img_name(img_dir)
num_img = len(img_names)
# 2. model
resnet18 = get_model(model_path, True)
resnet18.to(device) # 放入 cpu或gpu
resnet18.eval() # 模型处于静止、非训练状态
with torch.no_grad(): # 下面所有操作不保存梯度,减少内存消耗
for idx, img_name in enumerate(img_names):
path_img = os.path.join(img_dir, img_name)
# step 1/4 : path --> img
img_rgb = Image.open(path_img).convert('RGB')
# step 2/4 : img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # 变成4d张量

img_tensor.unsqueeze_(0) # 变成4d张量以后 :在开始多加了一维

img_tensor = img_tensor.to(device)
# step 3/4 : tensor --> vector
time_tic = time.time()
outputs = resnet18(img_tensor)
time_toc = time.time()
# step 4/4 : visualization
_, pred_int = torch.max(outputs.data, 1)
pred_str = classes[int(pred_int)]
if vis:
img_list.append(img_rgb)
img_pred.append(pred_str)
if (idx+1) % (vis_row*vis_row) == 0 or num_img == idx+1:
for i in range(len(img_list)):
plt.subplot(vis_row, vis_row, i+1).imshow(img_list[i])
plt.title("predict:{}".format(img_pred[i]))
plt.show()
plt.close()
img_list, img_pred = list(), list()
time_s = time_toc-time_tic
time_total += time_s
print('{:d}/{:d}: {} {:.3f}s '.format(idx + 1, num_img, img_name, time_s))
print("\ndevice:{} total time:{:.1f}s mean:{:.3f}s".
format(device, time_total, time_total/num_img))
if torch.cuda.is_available():
print("GPU name:{}".format(torch.cuda.get_device_name()))
实验结果:
