街景字符识别task4学习笔记
在baseline基础上尝试过多种可能提高模型预测精度的思路,其中只有两种获得了一定程度的提升:(1)增加数据扩增多样性,降低过拟合;(2)将全连接层改为卷积层。
1 增加数据扩增多样性
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([
transforms.Resize((64, 128)),#调整分辨率(h,w)
transforms.RandomCrop((60, 120)),#(h,w)
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(5),#在(-5,5)之间随机旋转
transforms.RandomAffine(30,translate=(0, 0.2)),#仿射变换
transforms.RandomGrayscale(0.5),#转灰度图
transforms.RandomPerspective(distortion_scale=0.5, p=0.5, interpolation=3),#透视变换
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#(mean,std)
])),
batch_size=40,
shuffle=True,
num_workers=10,
)
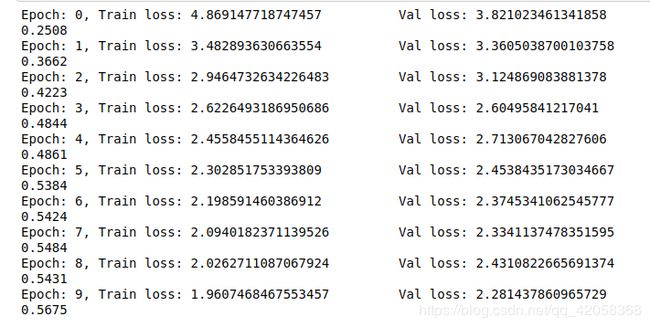
baseline算法在10个epoch后验证集精度为0.548,增加数据扩增方法后验证集精度为0.557,提高了一个百分点,训练结果如下。
2 将全连接层改为卷积层
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.cv1 = nn.Conv2d(512,11,kernel_size=1)
self.cv2 = nn.Conv2d(512,11,kernel_size=1)
self.cv3 = nn.Conv2d(512,11,kernel_size=1)
self.cv4 = nn.Conv2d(512,11,kernel_size=1)
self.cv5 = nn.Conv2d(512,11,kernel_size=1)
'''
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
'''
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
c1 = torch.squeeze(self.cv1(feat))
c2 = torch.squeeze(self.cv2(feat))
c3 = torch.squeeze(self.cv3(feat))
c4 = torch.squeeze(self.cv4(feat))
c5 = torch.squeeze(self.cv5(feat))
'''
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
'''
return c1, c2, c3, c4, c5
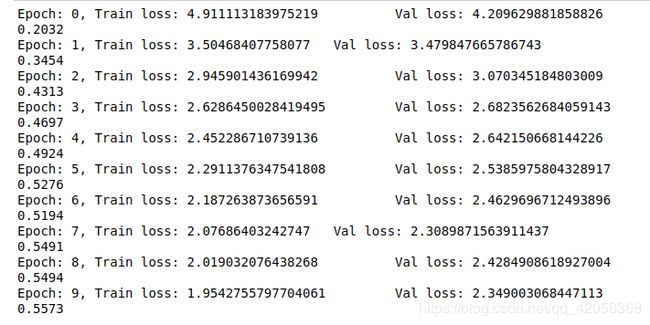
10个epoch后验证集精度又提高了一个百分点,为0.567,训练结果如下: