PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space(17)论文综述
- 为什么要做这个研究(理论走向和目前缺陷) ?
pointnet没有考虑提取数据的局部信息。对于比较精细的结构效果就比较差。 - 他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
为考虑局部结构的提取,用球查询方法进行点集分区[找质心点->找邻域->pointnet处理邻域];为了提高模型对点集不同密度的泛化能力,用了同一质心取不同大小的球邻域(multi-scale,计算量大)->连接特征和同一大小邻域内取不同的小邻域提取特征->聚合再提取特征->连接特征两种方案;为提高对不同数据集密度不一致的泛化能力,提出随机dropout策略;为解决语义分割问题,提出一种插值到原输入->提取特征方案; - 发现了什么(总结结果,补充和理论的关系)?
总的各方面效果都比pointnet有提升,但是否计算量过大?
注:metric space度量空间,在数学中就是指集合,且集合中的任意两个元素之间的内积都有明确定义。本文中的度量空间就是指点集,这个集合中任意两个元素间的内积就是两个点的对应元素相乘(经典的内积选取)。
摘要:度量空间(三维空间)的自身特点使得点云数据存在局部结构,PointNet并不能捕捉局部结构,这就就会限制pointnet对比较精细的场景的识别能力或者复杂场景的泛化能力。本文介绍了一个层级的神经网络,这个网络递归的将pointnet应用于输入点集的嵌入分区。通过利用点与点之间的距离关系,可以随着上下文尺度的增加学习局部特征。现实世界的点云数据,通常在采样时在从获得的点云密度就是不均匀的,但是训练时对训练数据的点云密度密度却是均匀的,这就会导致在实际场景中准确率下降的问题,故提出一个新的集合学习层来自适应地混合来自不同层的特征。本文提出pointnet++。
1 引言
距离度量(多近的范围算局部)能够定义可能呈现出不同特性的局部邻域。例如,点云中的不同邻域可能就呈现出不同的密度。这种密度的不同可能是由于扫描角度影响、径向密度变化以及运动等
pointnet只是先对每个点提取特征,最后在对特征融合一下,所以它并不捕获由于度量空间引起的局部结构。但是局部结构已经在卷积神经网络(cnn)中被证明很重要,cnn中低层感受也小,高层感受野大。这种能够层级地提取局部信息的能力的模型具有更好的泛化能力。
提除pointNet++用于层级地处理在度量空间里的点(就是取一邻域里的所有点类似cnn一样层层提取信息),思想很简单,首先根据距离将点云划分为一个个有重叠的区域,然后从小区域里提取信息,然后把各个邻近小区域里提取的信息整合成大的单元,再次处理提取更高层级的信息,迭代这个过程,直到提取的是整个点云的信息。
做到这样一个过程,PointNet++需要解决两个问题,怎样将点云划分为小区域,以及怎样提取小区域的信息(即如何构建局部特征学习器)。
本文中的局部特征学习器用的就是pointnet.
划分小区域用的是最远点采样算法(FPS)。
在cnn中,代表着对局部区域提取信息的就是卷积核,卷积核越大代表着感受野越大。有论文证明使用更小的卷积核能够提高CNN的性能。但是在对点云数据提取信息时,对越小的提取区域提取信息最后的效果反倒越差,这是因为小邻域包含的点很少,这就可能不足以让pointnet捕获形状。
本文的有一个重要贡献就是,pointnet++利用了多尺度的邻域,而不是单单一个小尺度或者大尺度邻域进行提取,这就同时满足了模型的鲁棒性和捕获细节的要求。在训练时,除了对输入数据进行随机舍弃(dropout), 模型还会自适应的调节在不同尺度捕获的特征进行融合时的权重。
2 问题描述
X = (M, d) 代表离散的度量空间(内部的点之间有明确距离定义的点云集合),其中M就是点集,d就是距离度量。所要做的是就是找一个函数f,这个函数f实际就是模型,f用来对输入的点集进行分类(整体分类为某个类别),或者对其中的所有的点进行分类(语义分割)。
3 方法
PointNet++可看做是PointNet的拓展,即在pointNet的基础上改用了层级结构。
3.1 回顾pointNet:通用的集合函拟合器
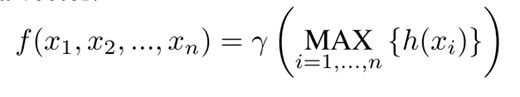
f是待拟合的集合函数,r和h是多层感知机(这一点在pointnet论文中没有明说,只说r是一个但变量函数,具体是啥却没说)。
pointnet不能很好的捕获在不同尺度大小下的局部语义信息。
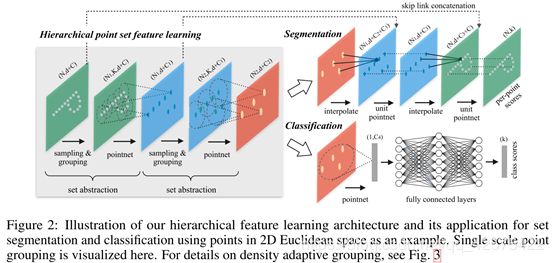
3.2层级的点集特征学习
pointnet网络结构
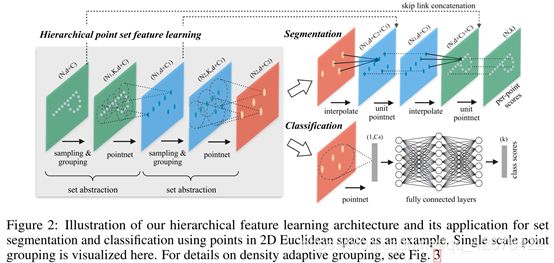
网络的层级结构就是指一层一层的数据特征提取层,即迭代使用pointnet。
每一层(level)都是先一个点集中抽象出新的集合,这个集合的参数元素更少。
每层(level)有三个关键层(layer):
采样层:从输入点集中挑选一部分点局部区域的质心。
组合层:根据采样层采集到的质心点,围绕每个质心点都找一个邻域。
pointNet层:用一个pointNet对组合成找出的各个邻域进行特征提取,每个邻域提取的结构就是特征向量。
每个level把N*(d + C)大小的矩阵作为输入,N代表个点,d代表每个点的坐标三个维度,C代表每个点的其它维度如颜色。输出的是N’× (d +C’)大小的矩阵,N’是代表子采样的点,d代表子采样的点的坐标维度,C’是提取出的新的局部特征的维度。
下面详细介绍每个level里的三个关键layer:
采样层:输入的是一个点集{x1, x2, …, xn},然后迭代运用最远点采样算法(FPS)来选择一个子集{xi1, xi2 , …, xim},这个集合里的每个点距离(在度量距离上计算)这个集合里剩下的点组成的集合都是最远的。在给定要抽取出的质心点的数目时,相比随机采样,这种方法有更能覆盖整个数据集的数据分布。与CNN对比,cnn进行卷积运算时是对所有的区域都运算,并不考虑数据的分布,因为输入的本来就是均匀的规则的数据,但是对于点云由于输入的数据是不规则的,不同位置密度有大有小,故要进行根据数据分布进行采样。
组合层:组合层的输入是整个输入点集N*(d+C)以及采样层从中挑选出来的质心点集N’*d,这个质心点集共N’个,是个事先确定的数值,d是三个坐标维度。组合层的输出大小为N’K(d+C),N’代表根据质心点集确定的局部区域数目,K代表每个局部区域(邻域)里的点的数目,不同邻域里的K是不同的,但是下一层的pointnet能够从不同数目的点集中提取出一个固定长度的特征向量,所以无影响,C还是最初的输入的每个点的其它维度如颜色。
根据质心点查找出质心的邻域内的其它点用的方法是球查询,就跟查找出在某个固定半径里的所有点,这个点的数目取一个上限值K,如果这个半径里的点的数目不足K就取所有查到的点,如果超过K查到第K个时不再往下查,这就造成每个邻域里的点的数目有可能不一样。还有其的查询方法KNN,但是没有球性查询通用。
pointNet层:这一层的输入组合层的输出N’K(d+C),经过pointNet后输出为N’ × (d +C’),代表对每个邻域各自都输入到pointNet中,得到一个d+C’维度的向量,合起来的大小就是N’ × (d +C’)。
在pointNet层中,先把各个邻域内的点的坐标以质心点作为原点进行变换坐标系。其他点的坐标都变为相对于质心点的坐标。
![]()
j代表第j个邻域, 代表第j个邻域里的质心坐标, 代表第j个邻域里的第i个点原始坐标以及经过质心变换后的坐标。
3.3在不一样的采样密度下的特征学习
一个点云在不同位置密度是不一样的,这就导致如果实在密度比较大的点云数据集中进行训练,训练出来的层不适用于密度比较小的区域,因此,针对稀疏点云训练的模型可能无法识别细粒度的局部结构。
说白了就是如果在密度比较大区域和密度比较小的区域应用同一种采样方式(同一种的表现就是采样出的点的数目一样),就可能存在问题。比如如果是比较精细的目标或者是比较小的目标,我们就希望采样区域更小些,每个区域采样的点更多些,但是如果是比较大或者很规则变化不多的目标,我们就希望采样区域更大些,每个区域采样的点的数目更少写,这样就能较好的提取反映局部结构的特征。
为此提出两种解决办法:
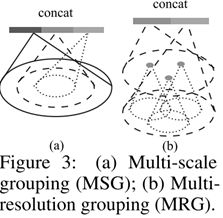
a)多尺度组合(multi-scale grouping 简称MSG)
如下图中的a,对不同大小的同心球区域进行采样提取特征,然后把每个球提取到的特征连接起来。
为了使得网络能够学习到一种优化策略来组合多尺度的特征,需要对输入点集进行随机dropout,dropout的比例为theta,theta的随机从范围[0,p]取值,其中p在实际中取的是0.95,之所以不是1是为了避免存在theta取成了1,这就出现了把所有的点都丢弃就没有点了。
这里有个疑问,是直接对整个输入点集进行dropout,还是对每个输入点集进行划分各个不同大小的同心球邻域后,对每个同心球邻域进行随机地dropout,倾向于前者,因为后者实操起来感觉会很麻烦,而且每个level都要进行这样的dropout就更麻烦了。
这样应用dropout做之后,就使得模型训练时的输入的不同点云数据有不同的稀疏度。但在测试时是不用dropout操作的。
b)多分辨率组合(multi-resolution grouping 简称MRG)
MSG方法计算代价很高,因为在同一个质心点,它会在多个比较大的同心球上运用pointnet,而且在比较前面的level是,质心点的数目又很多,也导致计算量很大。
故提出MRG组合方法,如上图b),这种方法计算量会小很多,而且也能够根据点的分布特性自适应的组合信息。图表达的很明白,不细说了。
这样做的好处就是,在局部区域的密度比较小时,连接向量中的左半部分就不太可信,因为本来大区域里有效信息就不多,先在大区域里更小的区域抽取信息,这个信息可想而知抽取不到什么有用的东西,然后把小区域抽取的无用信息聚合起来再抽取一遍,很有问题(是否真的有问题不太好说),此时连接向量中的右半部分就更可信,因为它是在更大的范围内抽取的信息。所以右侧的向量的权重此时应该更高一些。
另一方面,当局部区域的密度很高时,左半部分向量提供了更多的细节信息,因为它是从小区域内抽取出细节特征,又将细节特征聚合再次抽取抽象特征。
3.4 为了做语义分割采用的点特征推广(Point Feature Propagation for Set Segmentation)
简单来说就是如何应用提取的高层语义信息对原来输入的每个点进行分类。
如下图,把集合抽象层的输出(点比较少)插值到这个集合抽象层的输入(点比较多)上,然后把插值后的数据进行一个类似于cnn中的1*1的卷积的操作,对每个点提取到一个新的维度的向量(包含原始的点的坐标)。然后重复这个插值,提取特征的操作,回到了对最初输入的每个点云数据都进行了特征提取,然后就可以对这个点进行分类了。
插值公式如下:

所谓的插值,实际就是在集合抽象层的输出中找出离原始输入的每一个点(表示为x)最近的几个点(表示为xi,实际是k=3个),根据找出的点离这个点距离设置权重(wi),最后计算出C个值连接到原来输入的每个点的特征后面,注意不是数据相加,而是连接,原来的集合抽象层的输入点的特征还在那。f(j)(x)代表在这个点x后面连接的第j个元素的值。所以实际上对于每一个点都要计算C个要连接的元素,这个C的大小取决于这个集合抽象层输出元素的特征向量是多少维的(不包含坐标d的三个维度),比如说下图中第二个集合抽象层的输入C1维的,输出是C2维的,输出插值到输入数据后就变成了C1+C2维了,多了C2个维度。
4 实验
在2D的手写数字数据集MNIST, 3D刚体数据集ModelNet40, 3D非刚体数据集SHREC15(包含各种姿态的动物),真实3D场景数据集上ScanNet做了实验.
目标分类一准确率评估,语义场景标签以平均体素分类准确率评估。
4.1 在欧氏度量空间内做点集分类
在2D数据集MNIST上做实验时,是在图片上随机采集点(实际采集512个),作为2D点云数据。
所有的点都进行了归一化(坐标系变换,值归一)到一个单位球内。
下图中名词解释:
PointNet(vanilla)代表不加变换矩阵操作的原始pointNet网络
PointNet代表加了变换矩阵的操作。
with normal代表输入的点云数据中除有坐标维度还有坐标点处的法线维度。
DP代表用了dropout操作。
SSG代表只用的一个scale的对比试验。
MSG代表用了multi-scale的实验。
MRG代表用multi-resolution的实验。
下图右边的曲线图代表各模型做分类任务时对稀疏数据的鲁棒性测试。

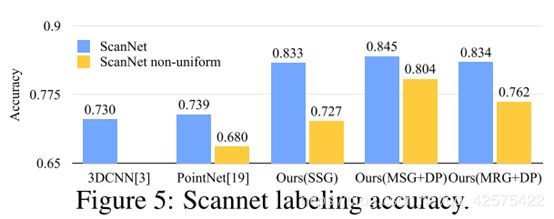
4.2 用于语义场景标注的点集分割
为做公平的比较,移除了输入点集的rgb信息,将预测出的点云标签转化为体素标签,转化方法见文中所提到的论文。
下图代表各模型做分割任务时对稀疏数据的鲁棒性测试,non-uniform就代表输入的点云数据密度不是一样的。
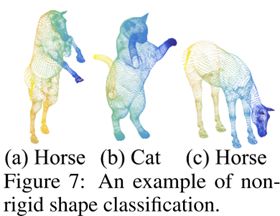
4.3 在非欧氏度量空间中做点集分类
非欧空间可以简单理解为曲面空间而非平面空间,如果是球面空间,在其上面的三角形内角和大于180度,球面上的两个点连线也不再是线段而是一条曲线。
本实验数据集SHREC15就是嵌入到3D空间中的3D曲面,以测地距离作为此非欧空间的度量。

4.4 特征可视化
5相关工作
层级结构的思想来源于CNN。但是CNN不能应用于非结构化的数据。
之前很多处理无序数据的模型都没有考虑距离度量,这就不能提取局部结构信息。并且对集合平移和归一化很敏感,本文额外考虑的度量空间解决了这些问题。
之前模型都没有考虑点集密度不一致的情况,本文考虑了多尺度方法应对密度不一样的问题。
6 结论
提取pointnet++,层级结构,点集分区处理,针对点集密度不一致问题提出多尺度和多分辨率解决方案。