YOLO-v4训练自己的数据集
Yolo-v4训练自己的数据集
文章目录
- Yolo-v4训练自己的数据集
- 如何在MS COCOs数据集上评估YOLOv4的AP?
- 训练好的模型
- AlexeyAB改进项
- 如何配置darknet
- 如何训练yolov4(训练你的自定义数据集):
- 如何多GPU训练?
- 如何批量测试?
论文传送门:https://arxiv.org/abs/2004.10934
参考文献: YoLov3训练自己的数据集(小白手册)
源项目README
github代码传送门:https://github.com/AlexeyAB/darknet

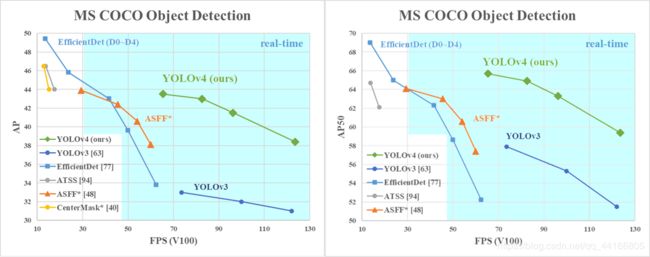
如何在MS COCOs数据集上评估YOLOv4的AP?
-
从MS COCO服务器下载并解压test-dev2017数据集:http://images.cocodataset.org/zips/test2017.zip
-
下载用于检测的图像列表,并将路径替换为您的: https://raw.githubusercontent.com/AlexeyAB/darknet/master/scripts/testdev2017.txt
-
下载yolov4.weights文件:https://drive.google.com/open?id=1cewMfusmPjYWbrnuJRuKhPMwRe_b9PaT
提供CSDN下载通道:https://download.csdn.net/download/qq_44166805/12378170
网盘下载通道:链接:https://pan.baidu.com/s/17XA84GBmSV7Thib1KCvQcA
提取码:l656有积分的朋友可以选择CSDN来资助一下~
-
文件
cfg/coco.data应为:
classes= 80
train = /trainvalno5k.txt
valid = /testdev2017.txt
names = data/coco.names
backup = backup
eval=coco
-
在可执行文件darknet所在文件夹里创建result文件夹
-
运行
./darknet detector valid cfg/coco.data cfg/yolov4.cfg yolov4.weights -
将文件重命名为’ /results/coco_results.json”到“detections_test-dev2017_yolov4_results。将其压缩为:detections_test-dev2017_yolov4_results.zip
训练好的模型
- yolov4.cfg - 245 MB: yolov4.weights paper Yolo v4
width=608 height=608in cfg: 65.7% [email protected] (43.5% [email protected]:0.95) - 34® FPS / 62(V) FPS - 128.5 BFlopswidth=512 height=512in cfg: 64.9% [email protected] (43.0% [email protected]:0.95) - 45® FPS / 83(V) FPS - 91.1 BFlopswidth=416 height=416in cfg: 62.8% [email protected] (41.2% [email protected]:0.95) - 55® FPS / 96(V) FPS - 60.1 BFlopswidth=320 height=320in cfg: 60% [email protected] ( 38% [email protected]:0.95) - 63® FPS / 123(V) FPS - 35.5 BFlops
AlexeyAB改进项
-
提供window支持
-
相较于原版pjreddie版本darknet提升了训练速度
-
添加了二值化网络,XNOR(bit) ,速度快,准确率稍低https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny_xnor.cfg
-
提升7%通过将卷积层和BN层合并一个。
-
多GPU训练提升
-
修补了[reorg]层
-
添加了mAP, IOU,Precision-Recall计算
darknet detector map... -
可以在训练过程中画loss图像
-
添加了根据自己数据集的anchor生成
-
提升视频检测,网络摄像头,opencv相关问题
-
提出了一个INT8的网络,提升了检测速度,但是准确率稍有下降https://github.com/AlexeyAB/yolo2_light
-
还有很多可以去看项目中的readme哦~
如何配置darknet
-
安装opencv以及NVIDIA显卡驱动and对应版本的CUDA(网上教程很多,不再赘述~)
-
下载安装darknet
git clone https://github.com/AlexeyAB/darknet cd darknet打开Makefile
GPU=1 #需要GPU加速设为1, CUDNN=0 CUDNN_HALF=0 OPENCV=1 #设为1 AVX=0 OPENMP=0 LIBSO=0 ZED_CAMERA=0 # ZED SDK 3.0 and above ZED_CAMERA_v2_8=0 # ZED SDK 2.X # 设置GPU=1 and CUDNN=1 开启GPU加速 # set CUDNN_HALF=1 to further speedup 3 x times (Mixed-precision on Tensor Cores) GPU: Volta, Xavier, Turing and higher # 设置AVX=1和OPENMP=1 实现CPU加速 (如果报错设置 AVX=0)设置完成后重新编译
make clean make -j8 #根据自己电脑决定线程,量力而行- 测试安装是否成功(需要下载yolov4.weights)
./darknet detector test ./cfg/coco.data ./cfg/yolov4.cfg ./yolov4.weights data/dog.jpg -i 0 -thresh 0.25
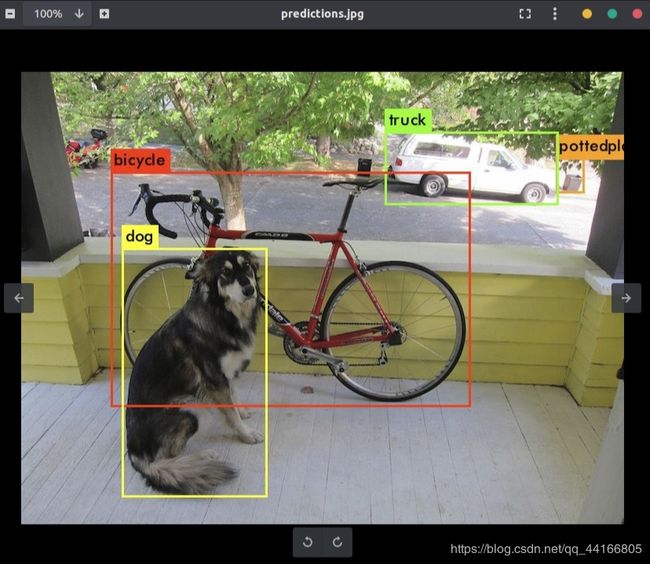
安装成功
如何训练yolov4(训练你的自定义数据集):
-
创建
yolo-obj.cfg文件,仿照yolov4-custom.cfg的样子 (也可以直接复制一份) ,并执行如下操作(记得去掉注释)
-
把第三行batch改为
batch=64 -
把subdivisions那一行改为
subdivisions=16 -
将max_batch更改为(数据集标签种类数(classes)*2000 但不小于4000 )
-
将第20的steps改为max_batch的0.8倍和0.9倍
-
把位于8-9行设为
width=416 height=416或者其他32的倍数: -
将
classes=80改为你的类别数 (有三个地方,969行,1056行,1143行) -
改正[
filters=255] 为 filters=(classes + 5)x3 (位置为查找yolo,每个yolo前的[convolutional]里,注意只修改最接近yolo的那个filters需要修改,一共应该有三处)贴出来修改后的cfg文件,仔细看注释哦
[net] # Testing batch=64 #显存不够的图像可以改为16,32等 subdivisions=16 #这里需要改 # Training batch=64 # 显存不够的图像可以改为16,32等 subdivisions=16 # 这里需要改 width=416 #可以改为32的倍数 height=416 #可以改为32的倍数 channels=3 momentum=0.949 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 learning_rate=0.001 burn_in=1000 max_batches = 4000 #改为classses*2000,但不小于4000 policy=steps steps=3200,3600 #改为max_batch的0.8倍和0.9倍 scales=.1,.1 #cutmix=1 mosaic=1 #:104x104 54:52x52 85:26x26 104:13x13 for 416 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=mish # Downsample [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [route] layers = -2 [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=32 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [route] layers = -1,-7 [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish # Downsample [convolutional] batch_normalize=1 filters=128 size=3 stride=2 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [route] layers = -2 [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=mish [route] layers = -1,-10 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish # Downsample [convolutional] batch_normalize=1 filters=256 size=3 stride=2 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [route] layers = -2 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=mish [route] layers = -1,-28 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish # Downsample [convolutional] batch_normalize=1 filters=512 size=3 stride=2 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [route] layers = -2 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=mish [route] layers = -1,-28 [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish # Downsample [convolutional] batch_normalize=1 filters=1024 size=3 stride=2 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [route] layers = -2 [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=mish [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=mish [route] layers = -1,-16 [convolutional] batch_normalize=1 filters=1024 size=1 stride=1 pad=1 activation=mish ########################## [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky ### SPP ### [maxpool] stride=1 size=5 [route] layers=-2 [maxpool] stride=1 size=9 [route] layers=-4 [maxpool] stride=1 size=13 [route] layers=-1,-3,-5,-6 ### End SPP ### [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = 85 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [route] layers = -1, -3 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = 54 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [route] layers = -1, -3 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky ########################## [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=21 #这里改为 filters=(classes + 5)x3 activation=linear [yolo] mask = 0,1,2 anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401 classes=2 #这里需要改成自己的classes num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 scale_x_y = 1.2 iou_thresh=0.213 cls_normalizer=1.0 iou_normalizer=0.07 iou_loss=ciou nms_kind=greedynms beta_nms=0.6 [route] layers = -4 [convolutional] batch_normalize=1 size=3 stride=2 pad=1 filters=256 activation=leaky [route] layers = -1, -16 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=21 #这里改为 filters=(classes + 5)x3 activation=linear [yolo] mask = 3,4,5 anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401 classes=2 #这里需要改成自己的classes数目 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 scale_x_y = 1.1 iou_thresh=0.213 cls_normalizer=1.0 iou_normalizer=0.07 iou_loss=ciou nms_kind=greedynms beta_nms=0.6 [route] layers = -4 [convolutional] batch_normalize=1 size=3 stride=2 pad=1 filters=512 activation=leaky [route] layers = -1, -37 [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=21 #这里改为 filters=(classes + 5)x3 activation=linear [yolo] mask = 6,7,8 anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401 classes=2 #这里需要改成自己的classes数目 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 scale_x_y = 1.05 iou_thresh=0.213 cls_normalizer=1.0 iou_normalizer=0.07 iou_loss=ciou nms_kind=greedynms beta_nms=0.6 -
-
处理数据集,
在scripts文件夹下创建文件夹VOCdevkit(因为scripts文件夹下有vov_label.py文件,它的作用下面会说,下面创建的文件也跟它有关),根据下图在VOCdevkit文件夹下创建文件,并放入相应的数据
VOCdevkit ——VOC2020 #文件夹的年份可以自己取,但是要与你其他文件年份一致,看下一步就明白了 ————Annotations #放入所有的xml文件 ————ImageSets ——————Main #放入train.txt,val.txt文件 ————JPEGImages #放入所有的图片文件 #Main中的文件分别表示test.txt是测试集,train.txt是训练集,val.txt是验证集,trainval.txt是训练和验证集,这里我只用了train和valid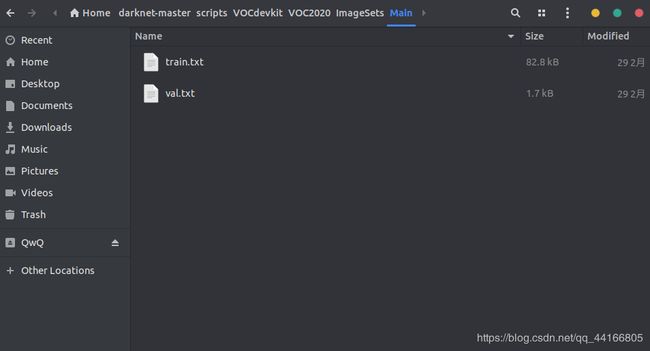
其中Main中的txt文件是要写文件名,比如train.txt里写的是用来训练的图片的文件名(不包含后缀,只是文件名哦!!!),这个文件可以找代码生成(下面的python代码可以用),代码的话看懂他的作用,特别的文件的路径之类的,根据自己的情况修改下,就可以用:
import os from os import listdir, getcwd from os.path import join if __name__=='__main__': source_folder='/home/linux/darknet-master/scripts/VOCdevkit/VOC2020/JPEGImages' dest='/home/linux/darknet-master/scripts/VOCdevkit/VOC2020/ImageSets/Main/train.txt' # train.txt文件路径 dest2 = '/home/linux/darknet-master/scripts/VOCdevkit/VOC2020/ImageSets/Main/val.txt' # val.txt文件路径 file_list=os.listdir(source_folder) train_file=open(dest,'a') val_file = open(dest2, 'a') file_num=0 for file_obj in file_list: file_path=os.path.join(source_folder,file_obj) file_name,file_extend=os.path.splitext(file_obj) file_num=file_num+1 if(file_num%50==0): #每隔50张选取一张验证集 val_file.write(file_name+'\n') else: train_file.write(file_name+'\n') train_file.close() val_file.close() -
修改voc_label.py,这个文件就是根据Main中txt里的文件名,生成相应的txt,里面存放的是它们的路径
sets=[('2020', 'train'), ('2020', 'val')] #这里要与Main中的txt文件一致 classes = ["hat", "person"] #你所标注的表签名,第一步中已经说过 os.system("cat 2020_train.txt 2020_val.txt> train.txt") #文件最后一句,意思是要将生成的文件合并,所以很据需要修改,这里的年份都是一致的,简单理解下代码应该会懂,不要盲目修改python voc_label.py #保存后运行
运行后会生成2020_train.txt、2020_val.txt、train.txt
-
复制data目录下的voc.name,改为***.name(例如safe.name),里面写标签的名字,例如
hat person -
复制cfg文件夹下的voc.data,重命名为***.data(例如:safe.data):
classes= 2 #classes为训练样本集的类别总数 train = scripts/train.txt #train的路径为训练样本集所在的路径,前面生成的 valid = scripts/test.txt #valid的路径为验证样本集所在的路径,前面生成的 names = data/safe.names #names的路径为***.names文件所在的路径 backup = backup/ #模型保存地点 -
下载预训练权重
for
yolov4.cfg,yolov4-custom.cfg(162 MB):yolov4.conv.137为方便国内读者下载,提供百度网盘:链接:https://pan.baidu.com/s/1rAzuhN6-mZwPOLyxF-7g3g
提取码:8b16有条件的可以用积分下载一下~(没积分的孩子在线卑微)
链接:https://download.csdn.net/download/qq_44166805/12378178
-
开始训练
./darknet detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map-map是输出MAP值,可以不加
-
断点继续训练
在每100次迭代之后,您可以停止,然后从这一点开始培训。例如,在2000次迭代之后,您可以停止训练,然后使用以下命令开始继续训练:
./darknet detector train data/obj.data yolo-obj.cfg backup/yolo-obj_2000.weight每1000次迭代保存一次,并自动保存当前最优模型。
-
模型检验
例如:检测mAP值
./darknet detector map data/obj.data yolo-obj.cfg backup/yolo-obj_7000.weights用模型检测图片:
./darknet detector test cfg/obj.data cfg/obj.cfg backup/obj.weights test.jpg -i 0 -thresh 0.25 -gpus 0,1,2,3用模型检测视频流:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -dont_show -ext_output -gpus 0,1,2,3服务器玩家可以在上述指令后加入
-dont_show -mjpeg_port 9090 #9090可以自己随意指定另一个然后利用端口监听就可以看到了(具体操作各个软件不一样),这里我用的xshell6的配置如下:
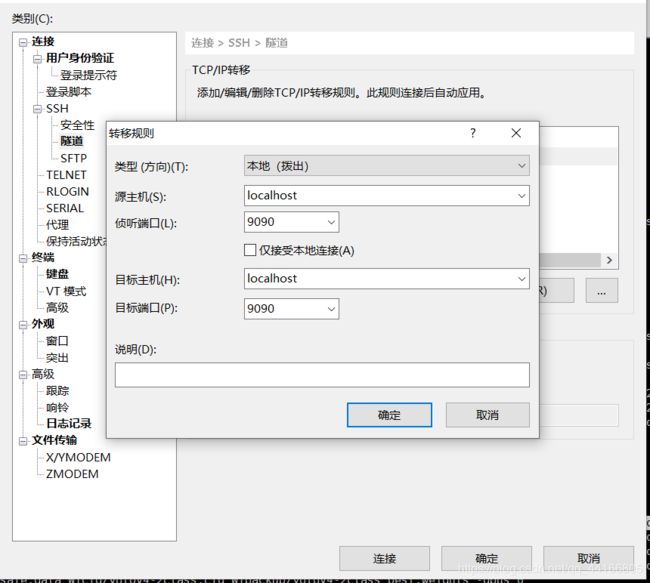
然后打开浏览器,输入127.0.0.1:9090就可以啦。
(Ps:训练时用nohup会很舒服)
如何多GPU训练?
-
先在1个GPU上进行1000次迭代训练:
./darknet detector train cfg/coco.data cfg/yolov4.cfg yolov4.conv.137 -
然后停止并使用刚刚训练的训练的模型
/backup/yolov4_1000.weights进行多GPU训练(这里用了四块):./darknet detector train cfg/coco.data cfg/yolov4.cfg /backup/yolov4_1000.weights -gpus 0,1,2,3对于小数据集降低学习率会更好,为4个gpu设置’learning_rate = 0.00025 (即learning_rate = 0.001 / gpu)。在这种情况下,还要在cfg文件中增加4倍的’burn_in = 和 max_batch = 。例如,使用’ burn_in = 4000 而不是’1000 。如果设置了’policy=steps ,那么steps= 也一样。
如何批量测试?
-
制作test.txt文件:
制作一个带绝对路径的批量测试文档,例如如下所示:
话不多说,上代码:import os from os import listdir, getcwd from os.path import join if __name__=='__main__': source_folder='/home/linux/darknet-master/testdata/JPEGImages/' #测试集所在位置 dest = '/home/linux/darknet-master/data/test.txt' # test.txt文档要保存的位置 file_list=os.listdir(source_folder) test_file= open(dest,'a') #追加写打开 file_num=0 for file_obj in file_list: file_path=os.path.join(source_folder,file_obj) file_name,file_extend=os.path.splitext(file_obj) file_num=file_num+1 test_file.write(source_folder+file_name+'.jpg'+'\n') test_file.close() -
运行darknet进行批量测试
如果你只是想批量测试data/test.txt并把结果保存至result.txt,可以用下面这个指令,当然,如果想看图片识别效果可以将-dont_show参数去掉./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output < data/test.txt > result.txtdarknet还提供了一种“假标定”方法来扩充数据集,处理图像列表data/new_train.txt ,并将每个图像的检测结果以Yolo训练标注格式保存为到
.txt (可以用来增加训练数据) : ./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25 -dont_show -save_labels < data/new_train.txt注:这种方法生成的txt可在你的训练集txt储存的地方找到