英伟达发布深度学习GPU训练系统DIGITS 5,自带图像分割与在线模型库
英伟达近日发布了 NVIDIA DIGIT 5。DIGIT 5 有许多新功能,本文将着重介绍下面两个:
1. 一个完全集成的分割工作流(segmentation workflow),允许创建图像分割数据库和将一个分割网络的输出可视化。
2.DIGITS 模型库(model store),一个公开的在线知识库,可下载网络描述和预先训练的模型。
这篇文章将探索图像分割的对象。将使用 DIGIT 5 来教一个神经网络识别和定位 SYNTHIA 数据库中合成图像里的汽车、路人、路标以及城市里的其它物体 :
图 1 展示了本文大概要做的内容

图 1:使用 DIGITS 5.0 的采样可视化交替展示了输入图像、FCN Alexnet 预测的一个 overlay,FCN-8 预测和 ground truth 的 overlay。
从图像分类到图像分割
假设你想要为自动驾驶汽车设计图像理解软件。偶然间你听说了 Alexnet、GoogleLeNet、VGG-16 以及其他图像分类神经网络架构,你或许会从这些网络开始做起。图像分类是计算机程序告诉你图像中的目标是狗的一种计算过程。
一个图像分类模型输出的是离散概率分布:经过训练的模型识别的每一个分类都有一个 0 到 1 之间的一个数字,也就是一个概率。图 2 说明了在 DIGITS 中使用 Alexnet 进行的猫的图像分类样例。效果非常好:要知道 Alexnet 已经用 1000 个类别的不同对象训练过了,包括动物、乐器、蔬菜、汽车和其他物品,得到的信度高达 99%,一台机器能够正确地将图像中的主体分类为猫科。

图 2:PASCAL VOC 数据库中 Alexnet 分类的一只猫的图像
但是如果你给一只猫和一只狗的图像分类,会发生什么?常识会让你相信该神经网络会给这两只动物分配相等的概率分布。让我们来试一下:图 3 显示了结果。预测中混合了猫和狗,但是 AlexNet 并没有像我期望的那样给出对半的概率。中间的那张图的前 5 个预测中事实上没有猫。这个结果挺让人失望,但是另一方面 Alexnet 用 120 万张图像构成的一个「小」世界训练过了,它在这个小世界中只看到一个对象,所以大家不能合理地期望它能很好的呈现多种对象。

图 3:PASCAL VOC 数据集中的猫和狗的图像的 Alexnet 分类
分类网络的另一个局限是它们无法区分图像中物体的位置。但是这可以理解,因为它们没有经过这样的训练,然而这确是计算机视觉里的主要障碍:如果一辆自动驾驶汽车不能确定道路的位置,它可能就无法开的很远!
图像分割为这些短板解决了一些问题。不单独为整张图像预测一个概率分布,而是将图像分成多个区块,每个区块有自己的概率分布。在最常见的使用中,图像被分解到像素水平,每个像素都可被分类:对于图像中的每个像素来说,神经网络被训练用来预测每个像素的分类。图像分割通常都会生成一个与输入图像尺寸相同的标签图像,其像素会根据它们的颜色来编码。图 4 展示了一张图像中四个不同类别分割的例子:桌子、椅子、沙发和盆栽。

图 4:PASCAL VOC 数据集中的图像分割例子(白色区域是未定义的像素如对象的轮廓和未分类的对象)
在图像进一步细化实例感知图像分割(Instance-aware Image Segmentation,IASI)中,神经网络学习识别图像中每一个对象的轮廓。这在实际应用中非常有用,它必须能识别图像中出现的类别,即便是在区别不明显的情况下,比如图 5:中间的图像是图像分割标签,而最右边的图像是 IAIS 标签图像(注意颜色编码是如何唯一确定出每一个人的)。这里就不深入将 IAIS 的问题,主要说一说实例分割(instance segmentation);但是建议大家可以查看一下 Facebook 的 SharkMask。

图 5:图像分割(中间)vs. 实例感知图像分割(右)。图像来源于 PASCAL VOC 数据集。
让我们看一看如何设计一个能分割一张图像的网络。
从卷积神经网络到全卷积网络(FCN)
上一节介绍中,区分了图像分类模型(为每张图像做概率分布预测)和图像分割模型(为每个像素预测概率分布)。总体上,这两种模型听上去差不多,你或许认为解决这两个问题的是同一个技术。毕竟,它只是增加了一个空间维度。本文将向你展示仅仅是一些小小的调整也足够将一个分类神经网络转换成一个语义分割神经网络,并将用到在论文《Fully Convolutional Networks for Semantic Segmentation》中首次提到的技术(我称之为 FCN)。
开始之前,先介绍一些术语:我会将 Alenet 这样典型的分类网络称为卷积神经网络,这有点不妥,因为卷积神经网络可用于除图像分类外的多种用途,但这是一种常用到的近似等同。
在一个卷积神经网络中,常见的做法是将网络分成两部分:在第一个部分特征提取器中,数据会经过若干卷基层来逐步提取更加复杂和抽象的特征。卷积层中通常会穿插非线性迁移函数(transfer function)和池化层(pooling layer)。每一个卷基层都可看作一组图像过滤器,可对特定模式触发高响应。例如,图 6 展示了 Alexnet 中第一个卷基层中过滤器的一个表征,和一张包含简单形状(假设 AlexNet 将这张图像归为一面墙钟)的虚拟图像的激活(输出)。这些过滤器对水平和垂直的边缘以及角落上触发了一个高响应。例如,看一下底部左边的过滤器,看上去很像黑白相间的条纹。再看看相对应的激活和对垂直线条的高响应。类似的,下一个过滤器会立即对斜条形生成一个高响应。网络里面的卷积层将能对多边形这类更加精巧的形状触发高响应,然后最终学习感知自然物体的纹理和各种成分。在一个卷基层中,通过在输入中将每个过滤器应用到一个 window(也叫 receptive field,感受野)来计算每一个输出,通过层滑动来滑动 window 直到处理完全部的输入。感受野与过滤器的尺寸相同。该过程见图 7。注意,输入 window 跨越了输入图像的所有通道。
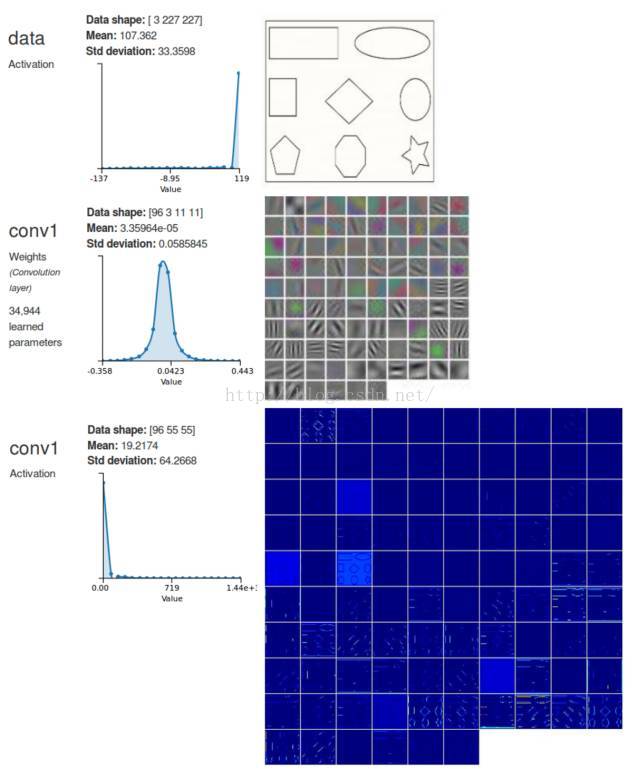
图 6:DIGITS 中呈现的是 AlexNet 卷积层 1。从顶端到底部:数据层(输入);卷积层 1 的过滤器的可视化;卷积层 1 的激活(输出)。
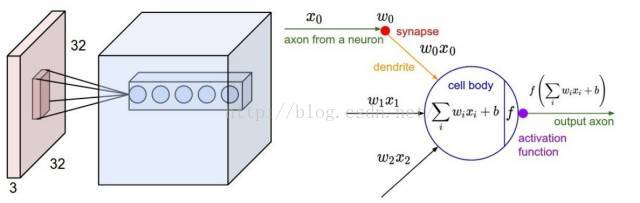
图 7:左边:一个红色的样本输入量,第一卷积层中的神经元的样本量。在输入量中该卷积层中的每一个神经元只单独与一个本地区域全深度相连(例如所有的颜色通道)。注意,沿着这个深度上有多个神经元(该样本中有 5 个),看的都是输入中的同一个区域。右边:这些神经元仍然要用带有一个非线性(non-linearity)输入计算它们权重的节点乘积,这样一来它们的连接性在空间上会被限制在本地中。来源斯坦福 CS231 课程。
在一个卷积神经网络的第二和最后一个部分中,分类器由有大量完全连接的层构成,其中第一层从特征提取器中接收它的输入。这些层会学习不同特征之间的复杂关系,来赋予网络一个对图像内容的高水平理解。例如,出现大眼睛和皮毛 可能会让网络倾向于一只猫。这个网络能如此精确的弄清这些特征有点不可思议,也是深层学习的纯粹美的另一个特质。这种无法解释的特性有时会受到批评,但它与人类大脑功能的方式 不同:你能解释你是怎么知道一张猫的图像不是一张狗的图像的吗?
全卷积网络(Fully Convolutional Networks,FCN),只由卷积层和上面提到的偶尔几个非参数层构成。消除全连接层如何能创建出一个看似更强大的模型呢?要回答这个问题,我们需要先思考另一个问题。
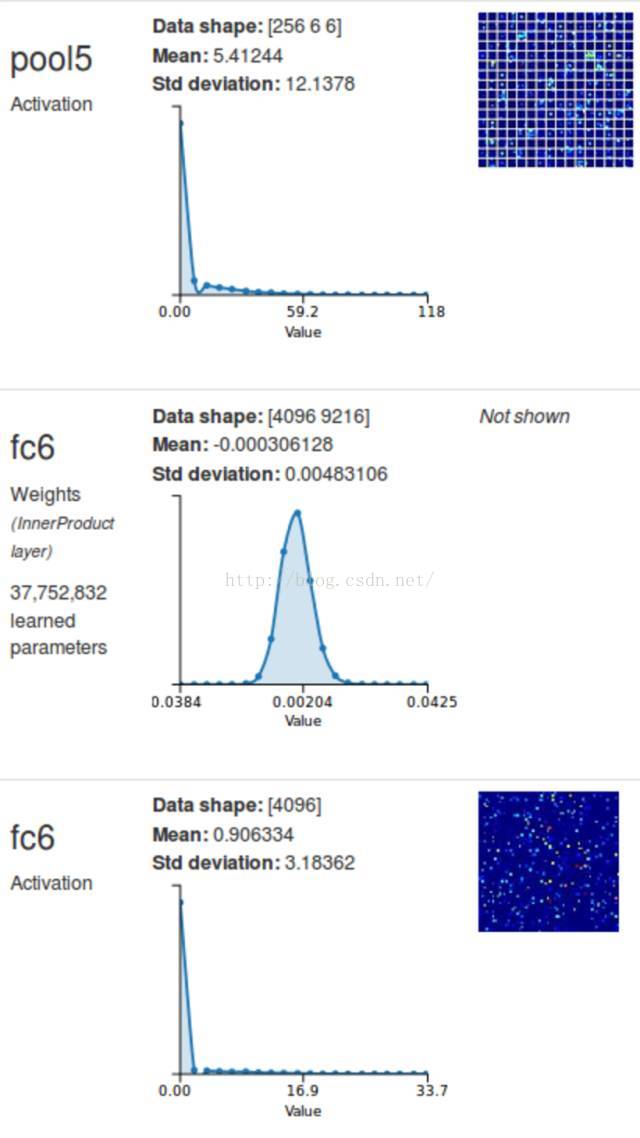
图 8:DIGITS 中的输入、权重和 Alexnet 第一个全连接层(fc6)的激活。
这个问题是:一个全连接层和一个卷积层之间有什么差别?这很简单:在一个全连接层中,每一个输出的神经元计算输入 值中的加权求和。相比之下,在卷积层中,每一个过滤器都计算感受野的加权求和。等等,这说的同一个事情吗?是的,但是,只有当层的输入与感受野具有相同的大小时才成立。如果输入比感受野大,那么卷积层就会滑动它的输入 window 并计算另一个加权求和。这个过程会一直重复到输入的图像从左到右,从上到下都扫一遍为止。最后,每个过滤器都会生成一个激活矩阵;每个这样的矩阵叫做一个特征图(feature map)
这就提供了一个思路:为了用一个相等的卷积层替换一个全连接层,只要将过滤器的尺寸设置成层输入的尺寸,并使用数量与全连接层中的神经元数量相同的过滤器。我们会在 Alexnet(fc6)的第一个全连接层中展示这个过程:相关层的 DIGITS 可视化见图 8。你能见到 fc6 从 pool5 中接收了它的输入,同时输入的形状是一个 256-channel 6×6 的图像。此外,fc6 上的激活是一个长度为 4096 的向量,这意味着 fc6 有 4096 个输出神经元。也就是说,如果我想用一个相等卷积层替换 fc6,我要做的就是将这个过滤器的大小设为 6×6,将输出特征图的数量设置为 4096。一个小小的题外话,你认为这一层有多少个可训练的参数?对于每个过滤器,感受野中每个数字都有一个偏项(bias term)加上一个权重。这个感受野的深度为 256,大小为 6×6,因此每一个过滤器都有 256×6×6+1=9217 个参数。因为有 4096 个过滤器,所以这一层的参数总数为 37752832。那正是 DIGITS 认为 fc6 会有的参数数量。
在实际中,取代该层很简单。如果你使用 Caffe,只需要用表 1 右边的定义取代左边的定义就行。

表 1:左:fc6 定义,右:对等的带有大小为 6 的核函数的 conv6,因为向 fc6 输入的是 6×6 的图像块。
了解了这些之后,你可以继续将所有的完全连接层转换成相应的卷积层。注意,不要用 DIGITS 计算这些层的输入的形状;你可以手动计算。听上去很有趣,但我保证要在 VGG-16 中做完所有的 16 层你会失去耐心,而且还没有暂存器来暂存记录。此外,作为一个深度学习爱好者,你应该适应让机器来为你干活。所以,就让 DIGITS 帮你做这些吧。
由此产生的 FCN 有与基础卷积神经网络数量相同的可学习的参数以及相同的表现和计算复杂性。由于输入相同,输出也就相同。你或许会惊讶:为什么这么麻烦滴转换模型?好吧,「卷积化」基础 CNN 引进了大量的灵活性。模型不再被限制在一个固定的输入尺寸(Alexnet 中是 224×224 个像素)上运行。它能像滑动 window 一样扫描整个输入来处理更大的图像,并且无需为整个输入单独输出一个概率分布,而是每 224×224 个 window 生成一个概率分布。网络输出的是一个带有 KxHxW 形状的张量,其中 K 是类别的数量,H 是垂直轴上滑动 window 的数量,W 是水平轴上滑动 window 的数量。
关于计算效率的一个提示:理论上你可以通过重复选择图像块并将它们馈送到 CNN 进行处理来实现 sliding window。但在实际中,计算效率会非常低:在你递增移动 window 时,只有一小部分新像素可被发现。如今,每个图像块都需要完全被 CNN 处理,即使在相邻图像块之间有很大的重叠。因此你可能要多次处理每个像素。在 FCN 中,因为这些计算都在网络内发生,只有小量的运算需要执行,因此处理速度有了量级增加。
总而言之,这给我们带来了新的里程碑:为分类网络增加了两个空间维度。在下一章节中,我讲演示如何进一步精调模型。
图像分割 FCN
在前面的章节中展示了如何设计一个预测每个 window 的一个类概率分布的 FCN。明显的是,在扫描输入图像时,window 的数量由输入图像的大小、window 的大小和 window 之间使用的 step 的大小所决定。理想上,一个图像分割模型将为图像中的每个像素产生一个概率分布。但在实际中如何做到这些?这里我会再次利用来自 FCN 论文的一个方法。
当输入图像连续穿过「卷积的」Alexnet 的各个层时,输入中的像素数据被有效的压缩为一系列粗糙的、更高层次的特征表征。在图像分割中,这么做的目的是插入这些粗糙特征来为输入中的每个像素重建出好的分类。事实证明使用解卷积(deconvolutional)层能很好的做到这些。这些层进行与卷积相反的逆运算:给定卷积输出和 filter 定义的情况下,一个解卷积层能够发现会生成这种输出的输入数据。记住在处理输入时,卷积层(或池化层)中的 stride 决定了 window 滑动的距离,因此它也是输出如何下采样的一种测量。相反,在解卷积层中的 stride 是输出如何上采样的一种度量。把 stride 选择为 4,输出就更大了 4 倍!
下一个问题是:在模型中,我如何决定上采样多少最后卷积层的激活函数,从而获得与输入图像同样大小的输出?我需要检查每一层,并谨慎的记下它的换算系数(scaling factor)。一旦我检查了所有层,只需要把所有换算系数相乘就行。让我们看一下 Alexnet 中的第一个卷积层:

卷积层 1 的 stride s 是 4,因此换算系数是 1/4。在所有层上重复此过程,我测定该模型的所有换算系数是 1/32,就像表 2 总结的那样。因此,解卷积层所需的 stride 大小是 32。

为了完备性,我必须要说的是卷积层的 stride 产生的输出在所有空间维度上都是输入大小的数倍这一说法并不完全正确。在实际中,向输入中增加 padding 将增加激活函数的数量。相反,使用核函数将打掉输入中的激活函数。如果你向该层提供无线长的输入,输入/输出比例将确实存在于所有(空间)维度。事实上,每个卷积(池化)层的输出都被移动了。表 2 是对这些计算的总结:
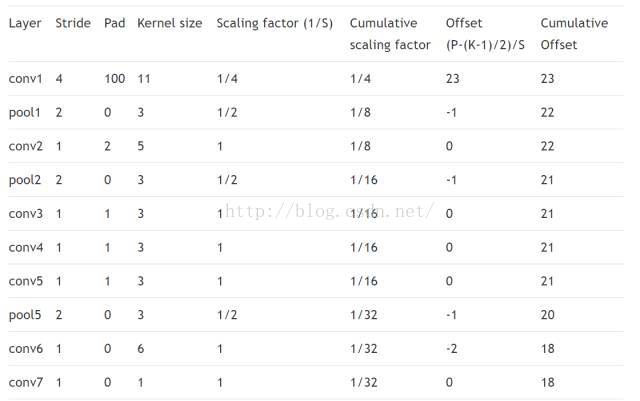
表 2 展示了网络的输出移动了 18 个像素。在此分割模型中我要用的最后一个技巧是一个层 crop 该网络的输出,并在每个边界移除 18 个额外像素。在带有 Crop 层的 Caffe 上很容易做到这一点,在下面列表中有所定义。

你可能注意到此版本的 Alexnet 要比卷积层 1 中的 padding 更多。有两个原因:一个原因是为了生成更大的初始迁移,以便于连续层招致的 offset 不被消化进图像。然而另一个主要原因是让该网络处理输入图像边界的方式是它们能够近似的碰触到网络的感受野。
终于,我有了复制 FCN-Alexnet 模型的所有东西。接下来,让我们看一下来自 SYNTHIA 数据集的新鲜图片。
SYNTHIA 数据集
SYNTHIA 数据集首次公开在论文《The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes》中。
图 9 展示了来自 SYNTHIA 数据集的图像样本。这些图像综合地展示了生成的带有各种目标分类的城市场景,比如建筑、道路、汽车和行人,该数据集也包括白天、黑夜不同场景下的情景。有趣的是,这些图像看起来很真实,足以迷惑人类:呃,第一张图中有人站在马路中间读报纸看起来很怪异,他肯定不怀好意!

图 8:来自 SYNTHIA 数据集的样本。左:要分割的图像;右:ground truth
在 DIGITS 5.0 中,创造一个图像分割数据集简单到点到输入和 groud-truth 图像 folders 并点击「创造」按钮。DIGITS 支持各种标记形式,比如 palette 图像(标记图像中的像素值是调色板指针)和 RGB 图像(每种颜色指代一种类别)。
在 DIGITS 中创造自己的数据集之后,你可以可视化的探索里面的内容,就像图 10 一样。

图 10:DIGITS 中的数据集探索。Top:输入图像,Bottom:标记。
训练模型
在 DIGITS 中开始训练模型所需要的只是对数据集和网络的描述。如果你认为卷积的 Alexnet 的流程有些复杂或者太耗时间:DIGITS 5.0 加上了一个模型库(model store),FCN-Alexnet 可从库中取回。
然而,如果你选择较难的方式,并创造自己的模型描述,你可能就想用到像 Kaiming(MSRA)方法这样合适的权重初始化 scheme,它如今是 Rectified Liner Units 的顶尖方法。通过在 Caffe 中向参数层加入一个 weight_filler { type: "msra" } 可轻松做到这一点。如果你在 DIGITS 中以这种方式训练模型,你可能会得到类似于图 11 的曲线。你可以看到表现有些不尽人意。验证准确率高峰在 35%(意味着验证集中只有 35% 的像素被准确标记了。)训练损失与验证损失一致,表明该网络在训练集上欠拟合。
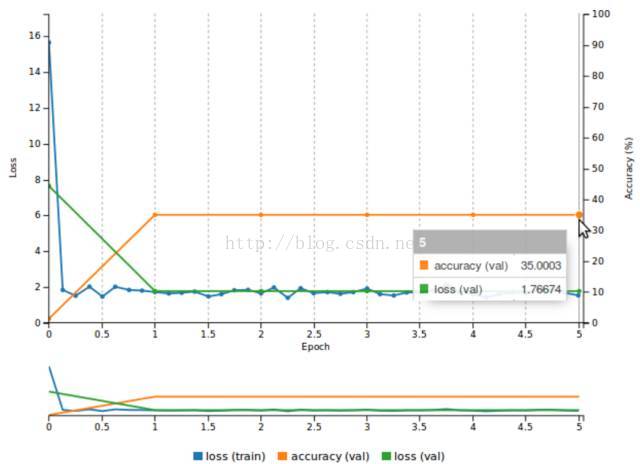
图 11:在 Synthia 上使用 DIGITS 中的权重初始化训练 FCN-Alexnet 时的训练/验证损失和验证准确率。
你可以在样本图像上尝试一下,并用 DIGITS 对图像分割进行可视化。你会得到类似图 12 的图像,在此你能看到网络在建立时任意的分类每件事。结果证明这种建立是 SYNTHIA 中最具代表的目标分类,该网络通过在建立时标记所有东西也慢慢地学到了 35% 的准确率。处理网络欠拟合训练集的方法都有哪些呢?
-
更长的训练:观察损失曲线,因为训练看起来已经达到了高点所以毫无办法。该网络已经进入了一个局部最小化,难以逃脱。
-
增加学习率并减小 batch 大小:这可能激励陷入局部最小化的网络探索周围环境外的东西,尽管这增加了网络偏离的风险。
-
增加模型的大小:这可能增加了模型的表达性。
我发现的另一个在计算机视觉上表现极好的方法是迁移学习。

图 12:在 SYNTHIA 数据集上使用随机权重初始化训练 FCN-Alexnet 时,DIGITS 中图像分割的样本可视化。该网络在建立的时候就分类了每件事。
你不必从随机初始化权重开始来训练模型。在很多情况下,它有助于重新使用网络在另一个数据集上训练时学习到的知识。这在使用 CNNs(卷积神经网络)的计算机视觉当中尤其如此,因为许多的低维特征(线、角、形状、纹理)直接适用于任何的数据集。因为图像分割是在像素的级别上进行分类,因此图像分类数据集中的迁移学习是有意义的,例如,ILSVRC2012。这在使用 Caffe 时显得相当简单—当然这会有一个或两个问题!记住,在 Alexnet 的 fc6 当中,权重的形状为 4096×9216。在 FCN-Alexnet 的 conv6 当中,权重的形状为 4096×256×6×6。这个数量与权重的数量完全相同,但是因为形状的不同,Caffe 无法自动携带权重给 FCN-Alexnet。该操作可以使用 net surgery script 来进行,其示例可以在 Github 上的 DIGITS 存储库中找到。net surgery script 的作用是将参数从完全连接层转移到它们对应的卷积层上。但是你可能会发现,直接从公共的 DIGITS 模型库上下载预训练模型会更加容易。图 13 显示了模型库的预览:单击「FCN-Alexnet」旁边的「导入」,DIGITS 将会下载预训练模型。
另一个相关的担心是如何初始化之前在文本上添加的上采样层,因为这一层并非是初始化的 Alexnet 模型:在 FCN 论文中,建议随机初始化相关权重并且使网络进行学习它们。论文的作者随后意识到,以这样的方式初始化这些权重也很简单,即通过进行双线性插值,该层仅充当放大镜。在 Caffe 中,这是通过向该层添加 weight_filler {type: "bilinear"} 指令来完成的。
使用预训练的 FCN-Alexnet 模型时,你会注意到精度会快速地超过 90%,并且当测试独立的图片的时候(如图 14 所示)结果将会是一个更令人信服的图像分割,拥有者 9 个不同的对象类的检测。然而,你可能会稍微有些失望地看到对象的轮廓都非常粗糙。阅读下一部分和最后一部分,了解如何进一步提升我们的分割模型的精度和准确度。
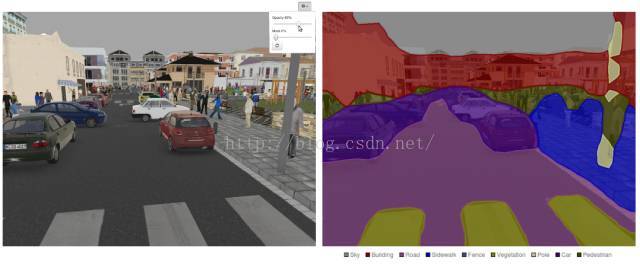
图 14:使用 ILSVRC2012 预训练的 Alexnet 在 SYNTHIA 数据集上训练 FCN-Alexnet 时 DIGITS 中图像分割的样本可视化。
精细分割
记住,添加到 FCN-Alexnet 的新的上采样层将 conv7 的输出放大了 32 倍。在实践当中,这意味着网络对每一个 32×32 的像素方块都会进行单独的预测,这解释了为什么对象的轮廓如此粗糙。FCN 论文中介绍了另一个解决这个限制的好方法:添加跳过链接,直接将 pool3 和 pool4 重定向到网络的输出。因为这些合并层在网络当中进一步回退,它们在低维特征上操作并且可以捕获到更加精细的细节。在被称为 FCN-8 的网络架构中,FCN 论文介绍了基于 VGG-16 的网络,其最终的输出是 pool3 上采样的总和的 8 倍,pool4 的上采样的 2 倍和 conv7 的 4 倍,如图 15 所示。这导致网络可以在更精细的颗粒上进行预测,下降到 8x8 的像素块。

图 15: FCN-8 跳过链接的图示—来源:FCN 论文
为了你的方便起见,可以从公共 DIGITS 模型商店下载预训练的 FCN-8。(你不会想要手动卷积 VGG-16 的!)如果你使用 DIGITS 训练 SYNTHIA 上的 FCN-8,你应该看到 只有几个时期,验证的准确率超过 95%。更重要的是,当你测试样例图片并且观察到 DIGITS 非常棒的图像分割可视化时,你会看到更加清晰地对象轮廓,如图 16 所示。

图 16:在 SYNTHIA 数据集上训练 FCN-8 时,DIGITS 中图像分割的样例可视化。
©本文由机器之心编译,转载请联系本公众号获得授权