Recorder︱深度学习小数据集表现、优化(Active Learning)、标注集网络获取
一、深度学习在小数据集的表现
深度学习在小数据集情况下获得好效果,可以从两个角度去解决:
- 1、降低偏差,图像平移等操作
- 2、降低方差,dropout、随机梯度下降
先来看看深度学习在小数据集上表现的具体观点,来源于《撕起来了!谁说数据少就不能用深度学习?这锅俺不背!》
原文:https://simplystatistics.org/2017/05/31/deeplearning-vs-leekasso/
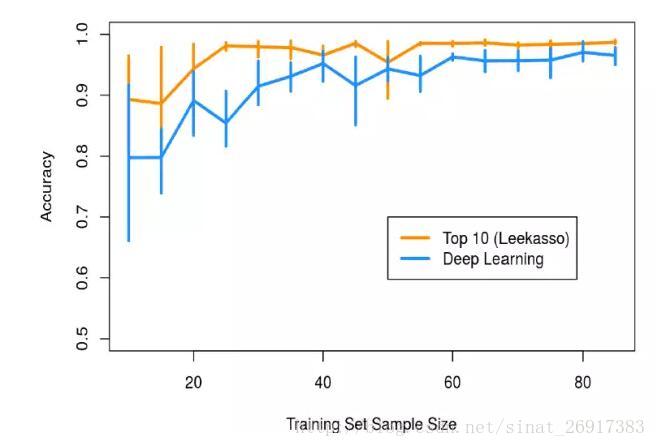
1、样本数量少于100个,最好不要使用深度学习
倘若你的样本数量少于100个,最好不要使用深度学习,因为模型会过拟合,这样的话,得到的结果将会很差。
他采用了两种方法:
- 一种方法采用的是神经网络模型,共5层,其中激活函数是双曲正切函数;
- 另一种方法使用的是李加索变量选择方法,这种方法思想就是挑选10个边际p值最小的像素来进行(用这些值做回归就可以了)。
实验结果表明,在只有少量的样本的情况下,李加索方法的表现要优于神经网络。
.
2、小数据集深度学习同样优异,就是得注意优化问题
同样是手写数字,这次放在了R中的kerasR中跑,得到的结论:
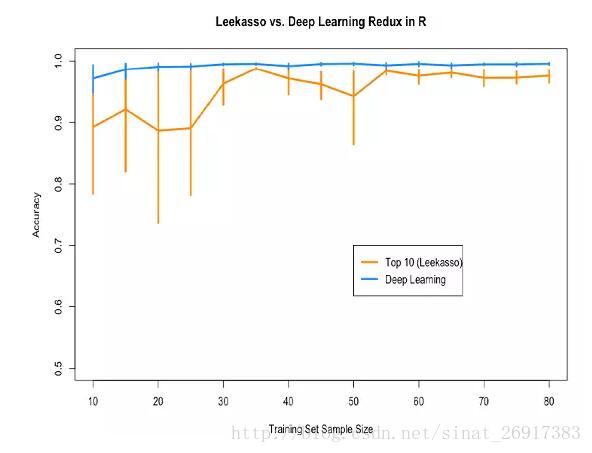
其中该贴作者做的优化:
(1)激励函数很重要,使用tanh作为激励函数的神经网络很难训练。最后使用Relu
(2)确保随机梯度下降能够收敛。
(3)不同的框架会导致不同的结果。最终是在Rstudio进行实验得到的结论,Python版本的逻辑回归使用的是liblinear来实现,我觉得这样做的话,会比R默认的实现方式更加的健壮,有更强的鲁棒性。
.
3、本节的结论
(1)任何措施都是为了取得偏差与方差的平衡。假若你没有足够多的数据,那么使用简单的模型相比于复杂模型来说可能会更好(简单模型意味着高偏差/低方差,复杂模型意味着低偏差/高方差)。
(2)神经网络有很多的方法来避免过拟合,dropout(降低方差)与随机梯度下结合,就会起到bagging算法的作用。
(3)深度学习能够轻易地将具体问题的限制条件输入到我们的模型当中,这样很容易降低偏差:
最好的例子就是卷积神经网络。在一个CNN中,我们将图像的特征经过编码,然后输入到模型当中去。例如,我们使用一个3X3的卷积,我们这样做实际上就是在告诉我们的网络局部关联的小的像素集合会包含有用的信息。此外,我们可以将经过平移与旋转的但是不变的图像,通过编码来输入到我们的模型当中。这都有助于我们降低模型对图片特征的偏差。并能够大幅度降低方差并提高模型的预测能力。(4)使用深度学习并不需要如google一般的海量数据:
使用上面所提及的方法,即使你是普通人,仅仅拥有100-1000个数据,你仍然可以使用深度学习技术,并从中受益。通过使用这些技术,你不仅可以降低方差,同时也不会降低神经网络的灵活性。你甚至可以通过迁移学习的方法,来在其他任务上来构建网络。
.
4、延伸案例:深度学习与XGBoost在小数据集上的测评,你怎么看?
来源于公众号机器之心
本篇文章实验了以下几款数据集:
Telecom churn 数据集(n=2325)
ANN神经网络准确率:0.79
XGBoost准确率:0.86
三种红酒数据集(n=59)
ANN神经网络准确率:0.983
XGBoost准确率:1
德国人资信数据(n=1000)
ANN神经网络准确率:0.779
XGBoost准确率:0.770
所以从上面来看,ANN 有时能得到最好的性能,而 XGBoost 有时也能得到最好的性能。所以我们可以认为只要 ANN 控制了过拟合和过训练,它就能拥有优良的表现,至少是能和 XGBoost 相匹配的性能。
XGBoost 的调参确实需要很多时间,也很困难,但 ANN 基本不用花时间去做这些事情,所以让我们拭目以待 ANN 到底是否会在小数据集上也会有大的发展
.
二、深度学习在少标注情况下的主动学习(Active Learning)
很多的标注集如何获得更多的数据?在文献《Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally》提到了:
横坐标是训练集的样本数,纵坐标是分类的performance
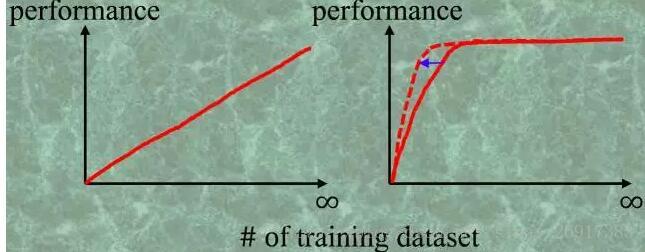
深度学习并不是左图那样,数据越多效果直线上升,而是右边这样是有一个临界值。当达到了这个临界的数目时,再去标注数据的ground truth就是在浪费时间和金钱。
红实线我们认为是在随机地增加训练集,那么红虚线就是用主动学习(Active Learning)的手段来增加训练集,从而找到一个更小的子集来达到最理想的性能。 那么临界值如何找到或者尽快平移呢?
- (1)临界点大小和这个分类问题的难度有关,如果这个分类问题非常简单,如黑白图像分类(白色的是1,黑色的是0),那么这个临界值就特别小,往往几幅图就可以训练一个精度很高的分类器;如果分类问题很复杂,如判断一个肿瘤的良恶性(良性是0,恶性是1),那么这个临界值会很大,因为肿瘤的形状,大小,位置各异,分类器需要学习很多很多的样本,才能达到一个比较稳定的性能。
- (2)主动学习那些比较“难的”,“信息量大的”样本(hard mining)。关键点是每次都挑当前分类器分类效果不理想的那些样本(hard sample)给它训练,假设是训练这部分hard
sample对于提升分类器效果最有效而快速。
.
1、主动学习——不知真正label去寻找hard sample
通过两个指标:
- (1)“熵(entropy)”。刻画信息量,把那些预测值模棱两可的样本挑出来,对于二分类问题,就是预测值越靠近0.5,它们的信息量越大。
- (2)“多样性(diversity)。”对于一幅图我们进行平移变换,我们知道它们其实是来自同一幅图的,那么最后的预测应该是一致的,如果当前网络对于这写patch的预测值偏差很大,那么我们认为这个样本是比较难分类的,需要被挑出来作为训练集。
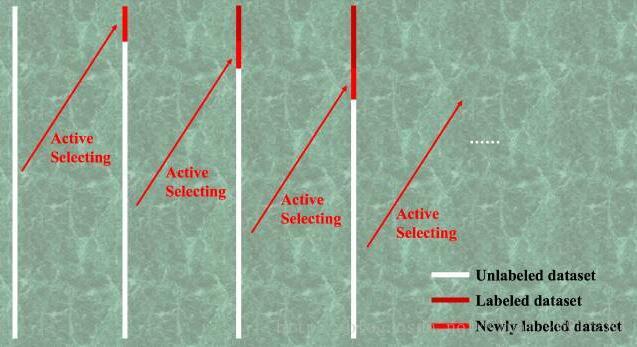
通过不断迭代寻找hard sample,然后重新训练,可以很快获得“高精度的模型+更多标注样本”。
.
2、初步解决方案
- 把1000张图放到在大量自然图像中预训练的网络(LeNet,AlexNet,GoogLeNet,VGG,ResNet等等)中测试一遍,得到预测值,然后挑出来那些“最难的”,“信息量最大的”样本,你看一下,给出他们的标签(卷毛比雄犬还是哈瓦那犬);
- 用这些刚刚给了标签的样本训练深度网络N;
- 把剩下那些没有标签的图像用N测试,得到预测值,还是挑出来那些“最难的”,“信息量最大的”样本,你再给出他们的标签(卷毛比雄犬还是哈瓦那犬);
- 刚刚给了标签的样本和原来有标签的样本组成新的训练集,继续用它们来训练深度网络N;
- 重复步骤3,4,直到 [?]
如FIG.2所示,每次循环都用不断增加的标记数据集去提升分类器的性能,每次都挑对当前分类器比较难的样本来人为标记。
怎么停止:
1、分类器对选出来的hard samples分类正确
2、选出来的hard samples人类也无法标记
.
三、从网络图片获取标注集
本节来源于程序员原创文章《面向图像分析应用的海量样本过滤方案》,作者:常江龙,苏宁云商IT总部资深算法专家。拥有多年的图像及视觉相关算法研发经验,目前专注于基于深度学习的图像内容分析算法平台的开发及优化,面向商品、人脸、OCR等图像算法实用技术领域。
通常需要获得不同类别对象的足量样本图像。其样本来源,可以有四种基本途径:
- 实地拍摄相关物品,此类方法效率比较低,适用于类别较少,每类需要大量高质量样本的情况,比如目标检测
- 识别对象如果是商品,可以利用其商品主图,但商品主图经过图像处理,且较为单一,与实际场景不符;
- 在不同网站通过文本搜索或匹配获取相关的网络图像,此类方法可以获得大量的图像样本
- 通过图像生成的方式来获得样本图像,比如近年来发展很快的生成对抗网络(GAN),此类方法的前景非常看好,但目前来说在大量不同类别上的效果还有待提升。
1、标注数据获取——多重过滤框架
网络图片中较多干扰、噪声图片,如何处理呢? 来看看苏宁团队的框架:
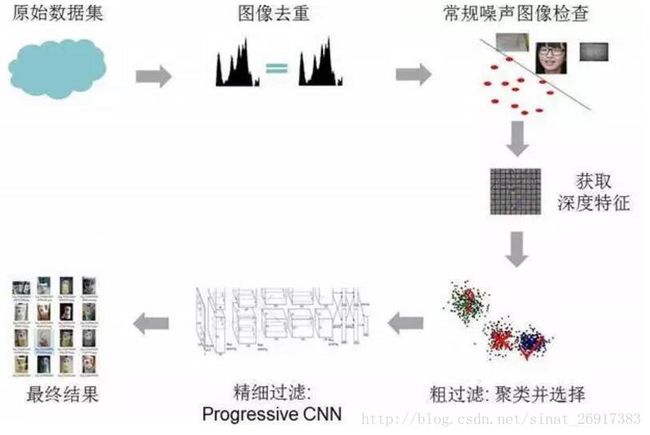
- (1)网络爬取
- (2)图像去重
- (3)去噪-粗筛,训练噪声的分类器,利用HOG,进行粗筛,过滤掉人脸、包装、发票等无关的常见类型噪声图像
- (4)去噪-聚类,获得深度特征并聚类(选取合适的聚类作为目标样本,并将其他聚类作为噪声图像去除),人脸、纸箱外包装、发票、聊天纪录图、商品或店铺Logo图等,占有相当高的比例
- (5)去噪-精筛,通过分类进行筛选(利用分类器返回的置信度来评估样本与相应类别的相关度)
.
2、图像去重与噪声过滤
过滤方式分为两种:
- (1)提取图像的直方图特征向量,利用特征向量之间的相似性进行去重;
- (2)或者构建一个哈希表,提取图像的简单颜色和纹理特征,对特征量化后利用哈希表进行查询,能够查询到的就是重复或极相似图像,查询不到的加入表中。
前一种方法对于微小差异表现更好,后一种方法的计算性能优势明显。
.
3、粗筛-噪声集分类器
待选样本集里往往会含有一些常见的噪声图像模式,比如人脸、纸箱外包装、发票、聊天纪录图、商品或店铺Logo图等,占有相当高的比例。
对于这些常见噪声图像,先提取其HOG特征,并用提前训练好的SVM分类器对其进行分类。为了保证精度,对于不同类的噪声图像,分别训练1vN的SVM分类器,只要图像判别为其中任一类噪声图像,即将其筛出。
以上两步,只利用了图像的简单特征,只能够去除样本集里的重复图像和常见噪声图像,对于更复杂的噪声图像模式,需要利用更有效的图像特征,并对于复杂类别采用无监督聚类来挖掘。
4、聚类
借助在Imagenet数据集上训练得到的网络模型,并利用已有的样本集进行fine-tune,这样模型对于特定品类的表达能力得到增强。这里对于一个图像样本,通过深度网络得到的特征是1024维向量,进一步通过PCA降维成256维的特征向量。这样图像样本集就构成了一个特征数据空间。
—模型:
接下来,在降维后的特征数据空间,利用一种基于密度的聚类算法进行聚类。该算法最突出的特点采用了一种新颖的聚类中心选择方法,其准则可描述为:
- 聚类中心附近的点密度很大,且其密度大于其任何邻居点的密度;
- 聚类中心和点密度比它更大的数据点,它们的距离是比较大的。
—做法:
选择了合适的聚类中心之后,再将各数据点分类到离其最近的聚类上,并根据各点距离相应聚类中心的远近,把它们划分成核心数据点和边缘数据点。
—优势:
该聚类算法思路简单,效率较高,并且对于不同的场景具有较好的鲁棒性。
在所得的聚类结果中,进一步选出密度较大且半径较为紧凑的聚类,其中的样本作为待选的目标样本数据,而其他聚类对应的样本则作为噪声样本予以筛除。
5、精筛
构建不同分类的深度学习模型,并进行fine-tuning
从目标样本中随机可放回的选取若干样本,并打上新的类别标签,作为新的训练样本,对一个已有的卷积神经网络模型进行fine-tune,这个卷积神经网络模型与前面提取特征的网络模型必须有一定差异(模型结构和训练数据都不同)。利用这个新的模型,对目标样本进行识别,得到其类别置信度。如果某个样本在所属类别上置信度很低,则将该样本作为不相关样本予以筛除。
6、效果
通过对于从网络获取的上万类别的近500万样本图像进行处理,并由人工校验算法的筛选结果。最终所得的目标样本,总体的类别相关度达到95%,其中对于较为热门的类别,样本相关度可以达到99%以上,总效率超过人工筛选百倍以上。图3左边是筛选得到的目标样本,右边是筛除掉的噪声图像。

.
延伸一:网络检索所产生的嘈杂数据来学习新的动作标签
来源于《学界 | 李飞飞协同斯坦福、CMU带来全新成果:从网络嘈杂的视频中进行学习》

在实验过程中,依赖于需要不断迭代的手工调整的数据标签策略(Hand-tuned data labeling policies)比较费时费力。
李飞飞她们团队提出了一种基于增强学习(Reinforcement learning-based)的方法,该方法能够从嘈杂的网络检索结果中筛选出适合于训练分类器的样本。
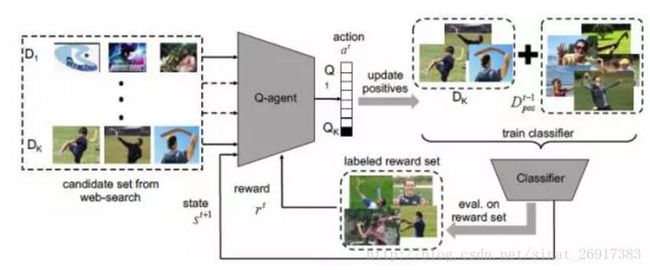
图二,模型框架图。该模型使用从网络搜索所得的候选示例集,为特定的视觉概念学习分类器。在每一个时间节距(time step)t,模型通过Q-learning的智能体来选择样本(比如Dk),并将该样本加入到已经存在的正样本数据集Dt-1中构成训练样本。然后该训练样本被用于训练视觉分类器。分类器将同时更新智能体的状态st+1并提供一个奖励rt。然后在测试期间,经过训练的智能体能够用于从任意的全新的视觉概念的网络检索结果中,自动选取出正样本。
该方法的核心思想是,使用Q-learning来学习一个小型标签训练数据上的数据标签策略,然后再利用该模型来自动标注嘈杂的网络数据,以获得新的视觉概念。
.
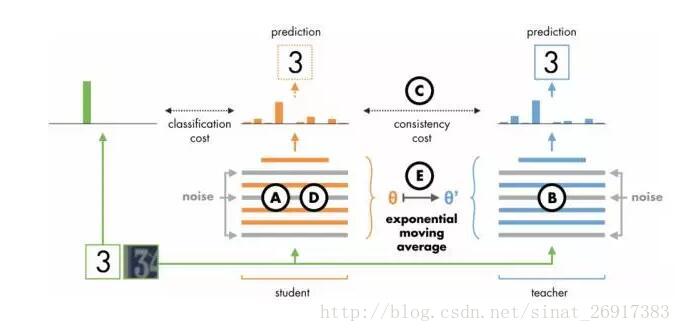
延伸二:入门 | 半监督学习在图像分类上的基本工作方式
Mean Teacher 的论文地址:https://arxiv.org/abs/1703.01780
Mean Teacher 的 GitHub 地址:https://github.com/CuriousAI/mean-teacher/
这些方法也非常容易实现和训练。例如,Mean Teacher 包含了以下步骤:
- 采用现有的监督学习模型。
- 将其复制一份。让我们将原始的称为「学生」,复制品称为「教师」。
- 在每个训练步骤中,让「教师」和「学生」一起评估一个小批量。在两个预测之间添加一致性代价函数(例如交叉熵)。
- 在每个训练步骤中,只用优化器训练「学生」权重。
- 在每个训练步骤后,将「教师」权重更新为「学生」权重的指数移动平均值。
也许,我们能想到的最简单的代理,就是将预测拉向最邻近的类别,无论是否正确。这正是 Entropy Minimization 所做的:
乍一看这似乎没什么用。毕竟,我们并未改变实际的预测类别,只是预测的自信度提高了(例如,从 70% 可能是狗,提升为 75% 可能是狗)。但是,如果我们考虑图像的全部特征,这一方案是有用的。我们鼓励分类器学习这样的特征——它们不仅能解释标记图片的类别,而且能解释未标记图片的类别。因此,对某些类别的强预测因素的特征将会变得更强,而给出混合预测的特征将会被逐渐弱化。
最近的新想法是让模型做出两个预测。让我们把他们称为学生和教师(其中之一或两者可能不同于原始预测)。然后,我们可以训练学生去预测教师。