Feature Engineering for Machine Learning 机器学习中的特征工程(三)
第三章是Text Data: Flatting, Filtering, and Chunking.
3.1 Bag-of-X: Turning Natural Text into flat Vectors
3.2 Filtering for Cleaner Features
3.3 Atoms of Meaning: From words to n-Grams to Phrases
本章介绍文本的特征工程,我们以bag-of-words开始,这是基于单词统计学上的表示,tf-idf是一个重要的特征尺度变换。本章主要是关于提取特征,清理特征的。
3.1 Bag-of-X: Turning Natural Text into flat Vectors(把自然语言变成向量)
对于文本数据,我们可以用统计学上的词频来表示,这称之为bag-of-words,对于一些简单的分类任务来说,这通常比较有效。也通常用于信息检索中。
在bag-of-words特征化的过程中,一个文本被转化成一列向量,比如下面这句话。

原始的文本是一些单词的序列,但是bag-of-words却失去了单词之间的联系,更重要的是数据在特征空间中的位置,如果单词表中有n个单词,一份文本就变成了n维空间中的一个点,下面的图显示了二维特征空间中的一个点。
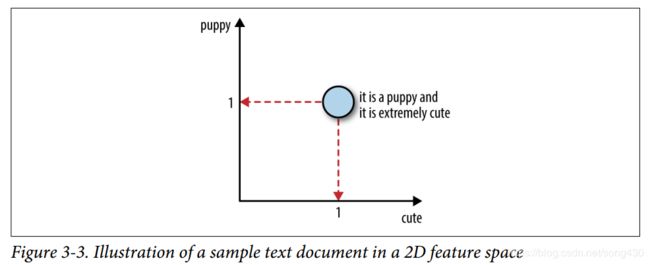
上面的图是在特征空间中表现数据,下面的是在文本空间中表示特征,坐标轴表示的是特征出现的次数。

bag-of-words并不完美,因为它失去了原有文本语义上的联系,比如“不错”,可能就会被分解成“不”和“错”两个含义,都表示不太好的意思,所以下面讲bag-of-n-Grams。
bag-of-n-grams是bag-of-words的扩展,一个单词就称之为1-gram,一个句子“Emma knocked on the door”,可以产生n-gram,包括“Emma knocked”,“knocked on”,“on the”,“the door”。
n-grams保留了原始句子的结构,就会产生更丰富的信息,但是也有相应的损失,理论上来说,有 k k k个非重复单词,就会有 k 2 k^2 k2个2-grams,但实际上不会有这么多,因为不是所有的单词组合都有意义,这也就意味着特征空间是稀疏的, n n n越大,花费就越大。
下面的代码用来展示 n n n是如何影响cost的,采用的是Yelp reviews dataset数据集。
import pandas
import json
from sklearn.feature_extraction.text import CountVectorizer
# Load the first 10,000 reviews
f = open('data/yelp/v6/yelp_academic_dataset_review.json')
js = []
for i in range(10000):
js.append(json.loads(f.readline()))
f.close()
review_df = pd.DataFrame(js)
# Create feature transformers for unigrams, bigrams, and trigrams.
# The default ignores single-character words, which is useful in practice because
# it trims uninformative words, but we explicitly include them in this example for
# illustration purposes.
bow_converter = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
bigram_converter = CountVectorizer(ngram_range=(2,2), token_pattern='(?u)\\b\\w+\\b')
trigram_converter = CountVectorizer(ngram_range=(3,3), token_pattern='(?u)\\b\\w+\\b')
# Fit the transformers and look at vocabulary size
bow_converter.fit(review_df['text'])
words = bow_converter.get_feature_names()
bigram_converter.fit(review_df['text'])
bigrams = bigram_converter.get_feature_names()
trigram_converter.fit(review_df['text'])
trigrams = trigram_converter.get_feature_names()
print (len(words), len(bigrams), len(trigrams))
26047 346301 847545
# Sneak a peek at the n-grams themselves
words[:10]
['0', '00', '000', '0002', '00am', '00ish', '00pm', '01', '01am', '02']
bigrams[-10:]
['zucchinis at',
'zucchinis took',
'zucchinis we',
'zuma over',
'zuppa di',
'zuppa toscana',
'zuppe di',
'zurich and',
'zz top',
'à la']
trigrams[:10]
['0 10 definitely',
'0 2 also',
'0 25 per',
'0 3 miles',
'0 30 a',
'0 30 everything',
'0 30 lb',
'0 35 tip',
'0 5 curry',
'0 5 pork']
所产生的效果如下

3.2 Filtering for Cleaner Features(清洗特征)
Stopwords
分类和检索通常不会对文本有很深的理解,比如,在句子“Emma knocked the door”中,单词“on”和“the”不会改变这个句子是关于一个人和一扇门的,对于粗粒度的任务-比如分类-来说,代词、介词、冠词不会有太大的价值,然而在语义分析时可能就不同了。
一个很流行的NLP python包,NLTK,包含了语言学家定义的stopwords列表,(需要安装NLTK),比如英文单词中的
[a, about, above, am, an, been, didn’t, couldn’t, i’d, i’ll, itself, let’s, myself,
our, they, through, when’s, whom, …]。
Frequency-Based Filtering
stopwords列表是预先定义没有意义的特征,统计学上的频率也可以找到一些常用的单词。
看下面的这张表,列出了40个在Yelp reviews数据集中最常用的单词

实际上常常将上面两种方法混合使用。
我们或许有时候还会去除一些非常稀有的单词,在统计学上,如果一个单词指出现1到2次,噪声的可能性就会大一些。
以Yelp reviews为例,160w条评论里有357481个非重复单词,189915个单词只出现在一条评论里,41162个单词出现在两个评论里,超过60%的单词都是比较罕见的,这是一个典型的heavy-tailed分布。这些不常见的单词就会使得运算和存储都有很大的浪费。
不常见的单词可以很容易的通过词频的方式找出来,然后把它们丢进garbage bin,可以作为额外的一个特征,比如下面这幅图。
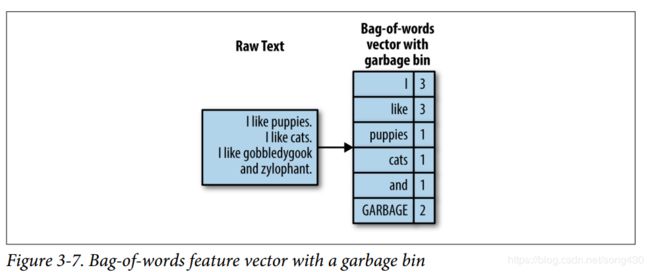
“flower”和“flowers”是一个意思,但是技术上却被分成了2个,如果把这些不同的单词映射到同一个单词上就好了。
stemming(词干)是一个NLP的任务,有很多方式把不同单词归于同一个词干,比如指定语义上的规则,或者是观测到的数据。
多数的stemming工具基于英语,Porter stemmer一个常用的免费的stemming工具。下面是一个stemming过程。
import nltk
stemmer = nltk.stem.porter.PorterStemmer()
stemmer.stem('flowers')
u'flower'
stemmer.stem('zeroes')
u'zero'
stemmer.stem('stemmer')
u'stem'
stemmer.stem('sixties')
u'sixti'
stemmer.stem('sixty')
u'sixty'
stemmer.stem('goes')
u'goe'
stemmer.stem('go')
u'go'
但是,“new”和“news”被stemmed成“new”,所以,stemming也不常用。
3.3 Atoms of Meaning:From words to n-Grams toPhrases(理解的原子性)
bag-of-words的概念很简单。 但计算机如何知道单词是什么? 文本文档以数字形式表示为字符串,基本上是一系列字符。 也可能以JSON blob或HTML页面的形式转换成半结构化文本。 但即使添加了标签和结构,基本单元仍然是一个字符串。 如何将字符串转换为单词序列? 这涉及解析和标记化(parsing and tokenization)的任务,我们将在下面讨论。
Parsing and Tokenization(解析和符号化)
当字符串不只包含纯文本时,必须进行解析。 例如,如果原始数据是网页,电子邮件或某种类型的日志,则它包含其他结构。 需要决定如何处理标记,页眉和页脚,或日志中不感兴趣的部分。 如果文档是网页,则解析器需要处理URL。 如果是电子邮件,那么像From,To和Subject这样的字段可能需要特殊处理 - 否则这些标题将最终作为最终计数中的正常单词,这可能没有用。
轻度解析后,文档的纯文本部分可以进行标记化。 这将字符串 - 一系列字符 - 转换为一系列标记。 然后可以将每个令牌计为一个单词。 标记生成器需要知道哪些字符表示一个标记已结束而另一个标记已开始。 空格字符通常是好的分隔符,标点字符也是如此。 如果文本包含推文,则哈希标记(#)不应用作分隔符(也称为分隔符)。
有时,分析需要对句子而不是整个文档进行操作。 例如,n-gram,一个词概念的概括,不应超出句子边界。 更复杂的文本特征化方法,如word2vec也适用于句子或段落。 在这些情况下,需要首先将文档解析为句子,然后进一步将每个句子标记为单词。
Collocation Extraction for Phrase Detection(用于短语检测的搭配提取)
一系列令牌立即产生单词列表和n-gram。 然而,从语义上讲,我们更习惯于理解短语,而不是n-gram。 在计算自然语言处理(NLP)中,有用短语的概念称为搭配。 用Manning和Schütze(1999:151)的话来说,“搭配是一种由两个或两个以上的词组成的表达,与某些传统的说话方式相对应。”
搭配比其各部分的总和更有意义。例如,“strong tea”具有超越“great physical strength”和“tea”的不同含义;因此,它被认为是一个搭配。另一方面,短语“cute puppy”意味着它的各个部分的总和:“cute”和“puppy”。因此,它不被认为是搭配。
搭配不一定是连续的序列。例如,句子“Emma knocked on the door”被认为包含搭配“knock door”。因此,并非每个搭配都是n-gram。相反,并非每个n-gram都被视为有意义的搭配。
因为搭配不仅仅是各部分的总和,所以单个字数不能充分捕捉它们的含义。bag-of-words不足以作为代表。Bag-of-n-grams也存在问题,因为它捕获了太多含义 - 较少的序列(在n-gram例子中考虑“this is”)并且没有足够的有意义的序列(如knock door)。
搭配作为特征很有用。但是如何从文本中发现并提取它们呢?一种方法是预定义它们。如果我们真的很努力,我们可能会找到各种语言的综合成语列表,我们可以查看任何匹配的文本。这将是非常昂贵的,但它会工作。如果语料库是非常特定于域的并且包含深奥的术语,那么这可能是首选方法。但是该列表需要大量的手动策划,并且需要不断更新以适应不断变化的语料库。例如,分析推文或博客和文章可能不太现实。
自从过去二十年统计NLP出现以来,人们越来越多地选择用于查找短语的统计方法。统计配置提取方法不是建立一个固定的短语和惯用语句列表,而是依赖于不断发展的数据来揭示当时流行的说法。
Frequency-based methods
表3-2显示了整个Yelp评论数据集中最受欢迎的双字母组(n = 2)。 正如我们所看到的,按文档计数排名前10位最常见的双字母组合是非常通用的术语,并不含有太多含义。

Hypothesis testing for collocation extraction
原始人气计数太粗糙了。 我们必须找到更聪明的统计数据才能轻松挑选出有意义的短语。 关键的想法是询问两个词是否比偶然出现的更频繁。 回答这个问题的统计机制称为假设检验。
假设检验是一种将噪声数据归结为“是”或“否”答案的方法。 它涉及将数据建模为从随机分布中抽取的样本。 随机性意味着人们永远无法100%肯定答案; 一直有异常值的可能性。 因此,答案与概率相关联。
在搭配提取的背景下,多年来已经提出了许多假设检验。 最成功的方法之一是基于似然比检验(Dunning,1993)。 对于给定的单词对,该方法测试观察数据集上的两个假设。 假设1(零假设)说单词1独立于单词2.另一种说法是看到单词1与我们是否也看到单词2无关。假设2(备选假设)说看到单词1 改变看到单词2的可能性。我们采用替代假设来暗示这两个单词形成一个共同的短语。 因此,短语检测的似然比检验(又名配置提取)会询问以下问题:给定文本语料库中观察到的单词出现次数是否更可能是从两个单词彼此独立出现的模型生成的,或者是 这两个词的概率纠缠在一起的模型?
我们可以将零假设 H n u l l H_{null} Hnull(独立)表示为 P ( w 2 ∣ w 1 ) = P ( w 2 ∣ n o t w 1 ) P(w2 | w1)= P(w2 | not \ w1) P(w2∣w1)=P(w2∣not w1),并且替代假设 H a l t e r n a t e H_{alternate} Halternate(非独立)为 P ( w 2 ∣ w 1 ) ≠ P ( w 2 ∣ n o t w 1 ) P(w2 | w1)≠P(w2 | not \ w1) P(w2∣w1)̸=P(w2∣not w1)。
最终的统计数据是两者之间比率的对数:
log λ = log L ( D a t a ; H n u l l ) L ( D a t a ; H a l t e r n a t e ) \log{\lambda} = \log{\frac{L(Data; H_{null})}{L(Data;H_{alternate})}} logλ=logL(Data;Halternate)L(Data;Hnull)
似然函数 L ( D a t a ; H ) L(Data; H) L(Data;H)表示在单词对的独立或非独立模型下看数据集中的单词频率的概率。 为了计算这个概率,我们必须对如何生成数据做出另一个假设。 最简单的数据生成模型是二项式模型,对于数据集中的每个单词,我们抛硬币,如果硬币出现,我们会插入特殊字,否则会插入其他字。 在此策略下,特殊单词出现次数的计数遵循二项分布。 二项分布完全由词的总数,感兴趣的词的出现次数和头部概率确定。
通过似然比检验分析检测常用短语的算法如下:
1.计算所有单例单词的出现概率: P ( w ) P(w) P(w)
2.计算所有唯一双单词的条件成对词出现概率: P ( w 2 ∣ w 1 ) P(w2 | w1) P(w2∣w1)
3.计算所有独特双单词的似然比logλ
4.基于它们的似然比排序
5.把最小比率的双单词作为特征
Chunking and part-of-speech tagging
分块比找n-gram更复杂,因为它使用基于规则的模型形成基于词性的标记序列。
例如,我们可能最感兴趣的是找到问题中的所有名词短语,其中实体(在本例中是文本的主题)对我们来说是最有趣的。 为了找到这一点,我们用词性标记每个单词,然后检查令牌的邻域以寻找词性分组或“块”。将单词映射到词性的模型通常是语言特定的。 几个开源Python库,如NLTK,spaCy和TextBlob,都有多种语言模型可供使用。
为了说明Python中的几个库如何使用PoS标记进行分块相当简单,让我们再次使用Yelp评论数据集。 在下面代码中,我们评估词性,使用spaCy和TextBlob查找名词短语。
import pandas as pd
import json
# Load the first 10 reviews
f = open('data/yelp/v6/yelp_academic_dataset_review.json')
js = []
for i in range(10):
js.append(json.loads(f.readline()))
f.close()
review_df = pd.DataFrame(js)
# First we'll walk through spaCy's functions
import spacy
# preload the language model
nlp = spacy.load('en')
# We can create a Pandas Series of spaCy nlp variables
doc_df = review_df['text'].apply(nlp)
# spaCy gives us fine-grained parts of speech using (.pos_)
# and coarse-grained parts of speech using (.tag_)
for doc in doc_df[4]:
print([doc.text, doc.pos_, doc.tag_])
Got VERB VBP
a DET DT
letter NOUN NN
in ADP IN
the DET DT
mail NOUN NN
last ADJ JJ
week NOUN NN
that ADJ WDT
said VERB VBD
Dr. PROPN NNP
Goldberg PROPN NNP
is VERB VBZ
moving VERB VBG
to ADP IN
Arizona PROPN NNP
to PART TO
take VERB VB
a DET DT
new ADJ JJ
position NOUN NN
there ADV RB
in ADP IN
June PROPN NNP
. PUNCT .
SPACE SP
He PRON PRP
will VERB MD
be VERB VB
missed VERB VBN
very ADV RB
much ADV RB
. PUNCT .
SPACE SP
I PRON PRP
think VERB VBP
finding VERB VBG
a DET DT
new ADJ JJ
doctor NOUN NN
in ADP IN
NYC PROPN NNP
that ADP IN
you PRON PRP
actually ADV RB
like INTJ UH
might VERB MD
almost ADV RB
be VERB VB
as ADV RB
awful ADJ JJ
as ADP IN
trying VERB VBG
to PART TO
find VERB VB
a DET DT
date NOUN NN
! PUNCT .
# spaCy also does some basic noun chunking for us
print([chunk for chunk in doc_df[4].noun_chunks])
[a letter, the mail, Dr. Goldberg, Arizona, a new position, June, He, I,
a new doctor, NYC, you, a date]
#####
# We can do the same feature transformations using Textblob
from textblob import TextBlob
# The default tagger in TextBlob uses the PatternTagger, which is OK for our example.
# You can also specify the NLTK tagger, which works better for incomplete sentences.
blob_df = review_df['text'].apply(TextBlob)
blob_df[4].tags
[('Got', 'NNP'),
('a', 'DT'),
('letter', 'NN'),
('in', 'IN'),
('the', 'DT'),
('mail', 'NN'),
('last', 'JJ'),
('week', 'NN'),
('that', 'WDT'),
('said', 'VBD'),
('Dr.', 'NNP'),
('Goldberg', 'NNP'),
('is', 'VBZ'),
('moving', 'VBG'),
('to', 'TO'),
('Arizona', 'NNP'),
('to', 'TO'),
('take', 'VB'),
('a', 'DT'),
('new', 'JJ'),
('position', 'NN'),
('there', 'RB'),
('in', 'IN'),
('June', 'NNP'),
('He', 'PRP'),
('will', 'MD'),
('be', 'VB'),
('missed', 'VBN'),
('very', 'RB'),
('much', 'JJ'),
('I', 'PRP'),
('think', 'VBP'),
('finding', 'VBG'),
('a', 'DT'),
('new', 'JJ'),
('doctor', 'NN'),
('in', 'IN'),
('NYC', 'NNP'),
('that', 'IN'),
('you', 'PRP'),
('actually', 'RB'),
('like', 'IN'),
('might', 'MD'),
('almost', 'RB'),
('be', 'VB'),
('as', 'RB'),
('awful', 'JJ'),
('as', 'IN'),
('trying', 'VBG'),
('to', 'TO'),
('find', 'VB'),
('a', 'DT'),
('date', 'NN')]
print([np for np in blob_df[4].noun_phrases])
['got', 'goldberg', 'arizona', 'new position', 'june', 'new doctor', 'nyc']
总结
bag-of-words表示易于理解,易于计算,并且对分类和搜索任务有用。 但有时候单个单词太简单了,无法在文本中封装一些信息。 为了解决这个问题,人们会寻找更长的序列。 bag-of-n-grams是bag-of-words的自然概括。 这个概念仍然易于理解,并且像bag-of-words一样容易计算。
bag-of-n-grams产生更多不同的n-gram。 它增加了特征存储成本,以及模型训练和预测阶段的计算成本。 数据点的数量保持不变,但特征空间的维度现在要大得多。 因此,数据更加稀疏。 n越大,存储和计算成本越高,数据越稀疏。 由于这些原因,较长的n-gram并不总能导致模型精度(或任何其他性能测量)的改进。 人们通常在n = 2或3时停止。很少使用较长的n-gram。
对抗稀疏度和成本增加的一种方法是过滤n-gram并仅保留最有意义的短语。 这是搭配提取的目标。 理论上,搭配(或短语)可以在文本中形成非连续的令牌序列。 然而,在实践中,寻找不连续的短语具有更高的计算成本而没有太多的收益。 因此,配置提取通常从候选人的bigrams列表开始,并利用统计方法来过滤它们。