mysql— EXPLAIN命令的总结
最近在看一本书《高性能mysql》,这本书是一本经典的书,我通过这本书解决了许多实际开发中的问题,从建库到横向硬件的优化应有尽有。
这里总结一下sql语句Explain查询优化器的一些内容,主要是通过实例来解释命令后的每一行所输出每一列所代表的含义。
先看一下EXPLAIN后所有的列
![]()
id:
标识select所属的行,也就是第几个select子查询,如果没有子查询或者union查询,则所有的select id都是1
1).没有子查询或者 union查询
EXPLAIN select * from user_point up
LEFT JOIN user_point_history uph on up.id=user_point_id;
2).from前的子查询
第一个查询是最外层的查询,通过table列也能看到,第二个查询是from前的查询
EXPLAIN select uph.transaction_point
,(select up.point from user_point up where up.id=uph.user_point_id)
from user_point_history uph;

3).from后的子查询(派生表)
第二个查询是user_point,所以确定第一个查询是最外层的查询,至于table为什么是derived2这个在说table列的时候再细说。
EXPLAIN select * from (select * from user_point) up 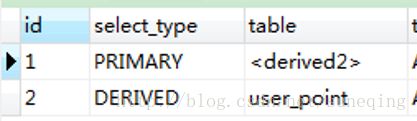
4).UNION查询
union输出的额外的行,也就是联合查询后的结果,一般都是放在匿名表中,之后mysql将结果读取到临时表中。临时表不再sql中出现,因此id是null,结果产生在最后因此它也是在最后的位置。
列表内容
EXPLAIN
select * from user_point u1
UNION
select * from user_point u2
select_type:
描述是简单查询,还是复杂查询。主要属性如下:
1).simple:简单的select查询,不包含子查询或者联合查询
EXPLAIN select * from user_point up
LEFT JOIN user_point_history uph on up.id=user_point_id;

2).primary:如果有子查询那么最外层(或者最开始)的select是primary类型
EXPLAIN select * from (select * from user_point) up

3).subquery:一般是from 之前子查询,也就是select列表中的查询
EXPLAIN select (select id from user_point_history LIMIT 1) from user_point ;

另外还有一种情况是DEPENDENT SUBQUERY,这种情况是列表子查询中的依赖最外层查询的数据了
EXPLAIN select
uph.transaction_point
,(select up.point from user_point up where up.id=uph.user_point_id)
from user_point_history uph;

4).drived:FROM后子查询select会出现此种类型,mysql会递归并将结果放到一个临时表中吗,服务器内部称为派生表,因此该临时表是从子查询中派生而来的
EXPLAIN select * from (select * from user_point) up

5).union/union result:在union后紧跟的查询,标记union类型,从union的匿名标检索结果的select被标记为union result
EXPLAIN
select * from user_point u1
UNION
select * from user_point u2
table:
这一列显示对应了正在访问那张表,主要分成三种分类
1).无派生标和联合查询
EXPLAIN select (select id from user_point_history LIMIT 1) from user_point ;
2).派生表查询
派生表(from 后的select查询)的外层查询的table列是’drivedN’的形式,N是子查询的ID,N指向的是EXPLAN输出后面的一行,也就是这个派生表的查询
EXPLAIN select (select id from user_point_history LIMIT 1) from (select * from user_point) up ;

3).UNION联合查询
table列中的‘ union1,2’指向的是参与联合查询的id
EXPLAIN
select * from user_point u1
UNION
select * from user_point u2

type:
关键的一列,决定了如何查找表中的行,下面的性能从差到优
1).ALL:全表扫描,意味着mysql会扫描整张表,如果使用了limit效率会提高,或者在Extra列中显示”USING distinct/not exists”。
EXPLAIN select * from user_point_history ![]()
2).Index 这个跟全表扫描一样,主要查询是按照MYSQL索引次序进行,它的优点是避免了排序,而缺点是要承担按照索引次序排序读取整个表的开销;
EXPLAIN select * from user_point_history ORDER BY id desc ![]()
如果在extra列看到了using index,则mysql正在使用覆盖索引,它只扫描索引的数据,而不是按照索引次序的每一行,它比次序全表扫描的开销要少很多
EXPLAIN select id from user_point_history ![]()
3).range:范围扫描,它开始于索引里的某一点,返回匹配这个值域的行。这比全表扫描要好一点。用不着遍历全部索引了。这种是where 子句中带有 between 或者 ><
EXPLAIN select id from user_point_history where id>'' ![]()
利用索引去查找一系列值时,例如IN() 或者OR 列表,也会显示为范围扫描。
EXPLAIN select id from user_point_history where id in ('1','2','3') or id>'' ![]()
4).ref 这是一种索引访问,它可能会找到多个符合条件的行,因此它是查找和扫描的混合体。此类索引访问只有当前使用非唯一索引,或者唯一索引的非唯一性前缀才会出现。
注:此表中user_id和invest_id是联合唯一索引。这里符合”唯一索引的非唯一性前缀才会出现“
EXPLAIN SELECT * FROM `task_invest` ti where ti.user_id=''; 5).eq_ref 使用这种索引查找,mysql最多会返回一条符合条件的记录。这种访问方法可以使用主键或者唯一索引查找时。它会将它们与某个参考值做比较
6).const,system 当mysql能对查询的部分进行优化,将其转换为一个常量时,它就会使用这些访问类型。举例:如果通过某一行的主键放入where子句里的方式来选取此行的主键,mysql能把这个查询转换为一个常量
possible_key:
这一列显示了查询可以使用哪些索引,这是基于访问的列和使用比较操作符来判断的,这个列在优化过程的早期创建的,因此有些罗列出来的索引可能后期优化过程是没用的
key:
mysql决定用那个索引来访问。
key_len:
使用索引的字节数,比如user表的主键user_id 是varchar(32)则这里的长度是98
ref:
指向key列中索引查询用到的列或常量
row:
估计为了找到所需的行需要检查读取的行数。不是结果集的行数。
这个需要检查的列是663*9704
filtered
它显示的针对表里符合查询某个条件的记录的百分比所做的一个悲观估算,需要将row列数据与其相乘,就能看到mysql估算它将和查询计划里前一个表的行数
举例:表中有1000条数据,id自增长,从1到1000,当查询id<500的数据时,此列值为50,row列是1000,则可以估算访问到的数据为500左右。