IGDATaiwan上Unity 优化讲座III
IGDATaiwan上Unity 优化讲座III (罗志达)
https://www.youtube.com/user/IGDATaiwan
议程: https://2019.tgdf.tw/agenda
今年 TGDF 台北遊戲開發者論壇,將有共五位Unity原廠講師,進行最前沿的技術分享,包括由Unity Evangelist羅志達帶來關於「運鏡技巧與DOTS技術(Data-Oriented Technology Stack)的結合」講題、以及專家級的Unity效能優化講座外,還有來自中國的技術經理成亮,分享輕量渲染管線(Lightweight Render Pipeline)相關議題。
Unity技術美術林宇,則將帶來可製作出全新渲染效果的Shader Graph編輯器的應用分享,並介紹如何透過本工具,建構各種從簡單到複雜進階的 shader。而Unity技術經理鮑健運,則將介紹可用於創作即時視覺效果的強大功能的Visual Effect Graph 。
最後,大中華區技術總監楊棟,則會從Unity Tiny Mode 輕量級 H5 應用開發進行詳解,技術經理鮑健運則會以Visual Effect Graph為講題,展示即時視覺效果的強大功能。對於遊戲程式及美術已有一定基礎的開發者,歡迎挑戰!
程序有关的:
- AMD 對遊戲開發者夥伴的互動與支援 https://www.youtube.com/watch?v=fOQdYRVG8mI
- 談 2019 年與往後的遊戲製作 https://www.youtube.com/watch?v=aVb6-Rkz7W4
- Mali GPU 架構以及 Mobile Studio 介紹 https://www.youtube.com/watch?v=Tds9w2hCujI
- AI 與大數據能為電子遊戲帶來什麼好處?
- 我的 DApp Game 開發日記 https://www.youtube.com/watch?v=ptSwFmRXiuQ
- Unity 輕量級渲染管線的使用與訂製 https://www.youtube.com/watch?v=pRI26fFpYpM
- 從第一天就開始玩遊戲:談遊戲開發時的持續整合與發佈 https://www.youtube.com/watch?v=pkzyqJulbTU
https://www.youtube.com/watch?v=pkzyqJulbTU
- AMD 對遊戲開發者夥伴的互動與支援
- 在 0 和 1 之間創造出更多可能 https://www.youtube.com/watch?v=PuMxGdd0lmM
- Unity 手機遊戲開發防火指南 https://www.youtube.com/watch?v=kdnm_osNZ9s
但是有许多Unity预设的行为,或是开发者没处理到的细节,会导致专案后期严重的困扰。希望能藉由分享自己多次救火的经验,帮助开发者们规划开发流程以避开陷阱,让专案顺利上架。本演讲会预设听众熟悉版本控制系统与Unity手机游戏开发、建置,会提到Unity版本选用、Git设定、自动建置概论与Android/iOS平台特性。
- 深入淺出 Unity Shader Graph https://www.youtube.com/watch?v=gegkgOH2_tY
- Tomorrow's Games. Today's Workflows. https://www.youtube.com/watch?v=gPt846MnPQ0
- 程序化遊戲關卡設計:三消遊戲之玩家體驗設計實務 https://www.youtube.com/watch?v=gothVfHHCec
- 多人連線遊戲架構的新典範 (ver.2019) 讲的Photon https://www.youtube.com/watch?v=ZRp-X69rC_0
- 轉換你的 Unity 專案到 DOTS 架構 https://www.youtube.com/watch?v=NnFEWXCY2po
- 紅魔導師的求生之路:從不寫程式開始的連線遊戲開發 https://www.youtube.com/watch?v=2TYmX8k_VGc
- Unity 優化講座 III
2019台北游戏开发者论坛Taipei Game Developers Forum(TGDF)论坛官网:https://2019.tgdf.tw/
讲者:罗志达/ Unity Evangelist讲题:Unity优化讲座III每年Unity官方会整理开发需要注意的优化要点,今年已经来到第三期,我们决定将今年的资料带到TGDF分享给各位开发者。本次的Unity优化讲座旨在定位出开发者比较常见的效能问题,并说明该如何回避这些情况与检查诊断,使用哪些工具等等。本议程适合听众为新手开发者或对于优化有兴趣的开发者,希望能为对在专案上想精进程式效能的人,提供一些方向。
ppt: https://www.slideshare.net/KelvinLo5/2019-unity-iii-tgdf
優化講座 I - 2017 http://unitytaiwan.blogspot.com/2017/03/unity_98.html
優化講座 II - 2018 https://www.slideshare.net/KelvinLo5/unity-ii
快速总结
• 这份资料不是让你看你知道了多少,⽽是让你审视你对专案是否有做过这样的全⾝检查,是否建立了⾃⼰的检查清单并每年执⾏最少⼀次。
• 同样⼀个预设值,不同的情况会有不同的最佳设定,设定不良代表效能消耗会分布在专案的每⼀个⾓落。
• 如果你从未调过预设值代表你的专案有很⼤的优化空间。
• 眼⾒不⼀定为凭,必须⽤⼯具跑报告来找出真正的问题点。
效能不佳到底是誰的責任?


在优化执⾏之前,明⽩专案压⼒在哪里
- 2D? 3D?
- 资源有多少?载入资源压⼒⼤于渲染压⼒(网格⾯数少但是2D图量多)
- 最低规格?
- PBR?特效多?
- FPS要多少?
- ⼿机耗电比?
你有考虑过⼿机耗电比吗?

因为温度过高,所以做了这个,在尝试可以从厂商那里得到设备的温度,然后调整帧率。

FPS多少才是对的?
1. ⼀个常犯的错误是极速的跑设备最⾼的FPS。
2. FPS不⼀单是为了画质,也跟和游戏逻辑和硬体有很⼤的关系。
3. 最佳FPS应该是依照2.所找出能跑⼀致速度的最⾼FPS。
4. 眼⾒不⼀定为凭,⼀定要⽤⼯具分析来找出问题。
检查区块
1. CPU
2. GPU
3. 程式脚本
4. 记忆体管理
5. I/O Asset Bundles与单⼀Asset使⽤
6. UI
7. 其他
常⽤⼯具
ios 的分析工具太强大了,如果一开始先处理IOS的问题, 安卓也就解决了70%
•iOS: Instruments (Xcode Frame Capture, Allocations, Timer Profiler)
•Android: Snapdragon Profiler
•采用Intel CPU/GPU的平台: VTune 和Intel GPA
•PS4: Razor suite
•Xbox: Pix tool
•Unity Profiler,
A.效能分析器 :控制当下效能分析的⾏为。
B.时间轴:显⽰在每个性能分析器领域中的性能分析数据。
C.执⾏资料 :根据所选择的单⼀帧分析数据中更多资料。
D.执⾏分类 :根据当下选择的领域在区域中显⽰效能分析数据的式。
 視圖簡單描述了每幀記憶體使⽤情況。
視圖簡單描述了每幀記憶體使⽤情況。
现在上线的游戏统计均值大概在 300~350MB 比较好,超过就可以优化。
Memory Profiler ● 2018.3或以上版本● 抓取記憶體快照● 比較記憶體快照
解决问题就从下图中大块下手
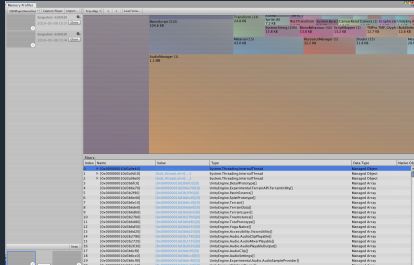
•Unity Entity Debugger,
Frame Debugger
列出前下畫⾯的所有drawcalls之外,並且還允許您逐個逐步執⾏它
XCode Frame Debugger - GPU

GPU的这种根据很有用, 比如达哥的一个 ECS射击,发现这个时候有一个高耗时, 用这个这个工具就可以定位到看不到的特效(第0帧还没有显示出来)
Forward Shading正向阴影
●原理:每个作弊于物体的预期光都会单独计算⼀次,因此画出电话会议的物体和光照数量的增加⽽成倍增加
●优点:不受硬件限制,可以使前端MSAA等
●缺点:
●1)光照计算损耗会因为光源和物体数量成倍增加
●2)每个物体接受的光照数量有限,通常除了主⽅向光外最多接受4栈预期光,逼真度受到限制
●3)⽬前还是比较适合⼿机,VR...
Deferred Shading延迟阴影
●原理:物体颜⾊,法线,材质等信息先渲染到G-Buffer中,光照最后单独渲染,从⽽避免了每个物体多个光照入射的问题。
●优点:作弊于每个物体的光照数量不再受到限制制,⽽且光照计算不会植入物体增加⽽增加比较适合真实画⾯类的游戏。
●缺点:
●1)移动设备需要⽀持OpenGL3.0
●2)不⽀持MSAA,可以使檐后处理AA
●3)半透明物体仍然使前端向前渲染
●4)⽬前还是比较适合PC有显卡的平台
渲染流程

Render State
Render State是⼀组设定,例如VertexShader,Pixel Shader,贴图和光照设定。放置Render State发⽣变化时,都会调用SetPass。

Draw Calls 和数据优化
场景中的每个物件都必须由Graphics API处理才能在萤幕上呈现。我们的游戏可能在任何场景中有数千个物件。为了让游戏能顺利执⾏,我们可以利⽤静态和动态批次处理将相同物件分组到同⼀个任务。

Static Batching
• 场景里⾯的静态物件会⾃动批次渲染(Static Batching)
• 静态批次并不会减少Draw Call的呼叫次数
• 由于状态不会改变,所以不应有Render State变动的问题。
• 代表静态物件在执⾏期间做任何的改变将会造成庞⼤的Render State修改,重新合披造成效能⼤灾难。
• 它的使⽤代价就是包体变⼤换效能。
• 但可以⽤Runtime做静态批次处理来解决这个问题(StaticBatchingUtility.Combine)
• 有时候额外动态载入的AB静态物件并不会⾃动批次处理要⽤程式跑⼀次
Dynamic Batching
• 相同贴图的物件可以共⽤⼀组Render State(把所有网格先算到⼀个世界座标后⼀起处理),就可以节省SetPass的开销
• 可以从player settings打开
• 动态批次有⼀个模型900个顶点属性的限制,因此只适合⽤在⼩物件
• 有非常多可能的状况会打断动态批次:比如-1Scale的镜像,Multi-pass的Shader,灯光太多的Forward path或半透明物件等等
GPU Instancing
处理相同材质但不同设定(颜⾊、位置等等),重复利⽤GPU渲染过的资料
所以这个设定在材质上,GPU Instancing没有像动态批次的限制
材质把选项打勾即可
三种批次处理的优先顺序为:(是说同时勾选的时候Unity引擎底层的选择优先级)
静态 > GPU Instancing > 动态
可以⽤Frame Debugger来查看哪些批次被正确的执⾏或没有被合披的原因
因为批次处理有许多限制,比如和镜头的距离和⾓度
开发者常⾒的问题状况
CPU/GPU瓶颈?
在CPU开销不⼤的情况下,如果Gfx.WaitForPresent或者Graphics.PresentAndSync耗时很多,说明在等待GPU执⾏渲染命令。这种情况下可判断为GPU瓶颈

CPU or GPU 瓶颈
为了渲染单个帧,CPU和GPU都必须完成所有任务才能渲染下⼀帧。如果这些任务中的任何⼀个花费太长时间才能完成,则会导致帧的渲染延迟。

CPU 瓶颈
当我们的游戏渲染帧时因为CPU执⾏渲染任务所需的时间太长⽽造成延迟。 (Camera.Render)
GPU 瓶颈及诊断⽅式
1. 填充率:如果降低解析度(就是分辨率)后会改善,就很可能是填充率的问题。
2. 记忆体频宽:如果降低贴图解析(就是分辨率)后会改善,就很可能是记忆体频宽不⾜。
3. 顶点处理耗时:如果既不是填充率,也不是记忆体问题,⼤部分是顶点处理的问题。 (难道没有片元的问题?)
4. 渲染物件数量过多

CPU
1.后制处理(Post Processing)处理不好很容易造成CPU压⼒,如果发现Graphics.Blit消耗很⼤,可能要减少后制处理或是降低解析。
2.⼤量的实例化(Instantiate)很容易造成CPU压⼒,善⽤物件池来减低压⼒。
3.所有Get/Find调用(如GetComponentInChildren)不要在Update里⾯调用,最好在⼀开始就暂存起来。
4.和⽂字相关的处理,都要非常⼩⼼。 String相关处理会在记忆体堆叠上分配很多String物件。可以在处理数据时直接使⽤⼆进位格式,反序列化所需要的物件,减少⽂字转换造成的消耗。针对⽂字处理可以参考这篇:https://docs.microsoft.com/zh-cn/dotnet/standard/base-types/best-practices-strings
5.上⼀个问题也适⽤于Json, XML, DSL解析,如下图:JSON反序列化耗时%2.3造成卡顿。

带有Alpha的图集和不带Alpha的图集应该分开 (下图的左图没有Alpha , 右下的框中间是镂空的 所以应该分开, 或者认为左侧的图太大了)
单张⼤图可以不要放在图集里,节省Alpha通道

打图集的问题

发亮效果或是不同颜⾊应该分开处理 (左侧左侧按钮实际上是颜色上的区别,然后把白条拆出来)
图档或图集空⽩太多 (说的是右上的蓝条框)
贴图框中间部分可以缩⼩ (左下,使用九宫格)
长条形的图应该要缩短 (右下,因为通过拉伸就可以了)
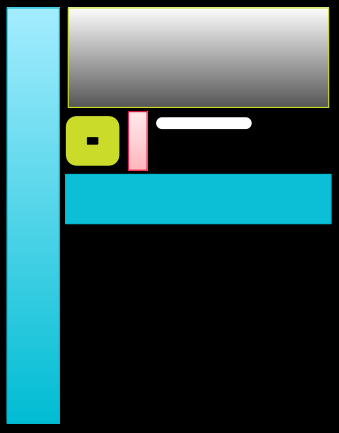
UI图集优化:
1. 缩⼩解析度并减少空⽩
2. 减少纯⾊UI尺⼨
3. 单张背景单独存放
4. 避免⼤量重复图形
5. 图集⼤⼩要是PO2正⽅形(Power of 2)
UI
1.UI必须动静分离
2.透明UI范围太⼤很容易造成overdraw
3.在战⾾画⾯可以60fps, 选单画⾯降为30fps会节省效能
4.静⽌不动的画⾯与⽂字,常常会犯了不断更新的错误。往往会造成GC
5.如果有字型档,只需要非系统字留下即可,像是Arial这种系统字可以不放在专案里。
老⽣常谈的常犯错误-贴图
- 背景图不需要Alpha通道的图带有Alpha通道
- 没距离需求却开了MipMaps
- 没有需要CPU处理的图却开了Read/Write Enabled (导致CPU【多出的拷贝】 跟GPU都有出一份)
- NPoT设定为None的话,比如贴图1562x1406的话,PVRTC格式会因为不是Power of 2转⽽改⽤RGBA32解压,占⽤会变很⼤。
- 不会近看的图解析度却很⾼或是超⾼解析度的法线贴图
- 很⼤张的纯⾊贴图
- Filter Mode能⽤Bilinear就不要⽤Trilinear
- 材质建议都要设为PO2

贴图 Mipmap
如果物件的Z轴不会改变,那么开启 MipMap 是⼀种浪费。 Normal也不需要开MipMap。
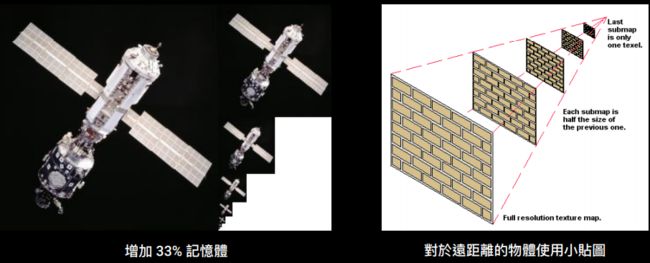
mipmap 还可以解决因为缩放导致的锯齿的问题。
老⽣常谈的常犯错误-模型
- 模型只⽤到uv, 却带了uv2, uv3,uv4。如果多个模型有多套UV,建议检查把模型的UV套数降低,只保留需要的。
- 不需要Import的检查都取消打勾

- 模型没⽤到Lightmap却把Generate Lightmap UV打勾,会额外产⽣uv2资讯
- 模型预设开启 Read/Write Enable,建议把不参与动态合批的模型关闭。
- Mesh Compression可以依照需求
- 如果原始模型⾯数很⾼,Optimize Mesh可以适度降低模型顶点数量
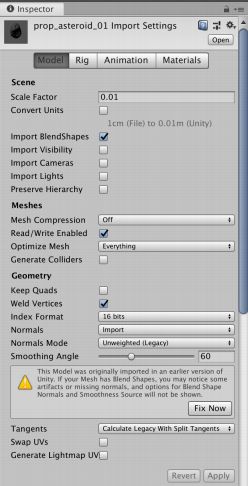
- 物件没有使⽤Light probes建议关闭。
- 没⽤Motion Vectors 也建议关闭。
- 没有使⽤阴影时,也建议关闭。

- 没有动画的物件,要设定为None
- 新版Unity已经把Optimize Game Objects移到别处

Shader
1.尽量避免使⽤Shader.WarmUpAllShaders()
在游戏启动时实例化所有的Shader是比较建议的,但是如果⽤这个函式,会依照对应的Shader产⽣所有可能会⽤到的Shader Variants,不管你会不会⽤到。
2.Unity的Shader Keywords是有上限的(⽬前256),Standard Shader约占了60个。
3.如果没⽤到Standard Shader,要注意有没有被包进去,通常都是连同Default Material。
4.预设Build-in Shader setting可以把没⽤到的关掉

⾳效
1.声⾳打开Force Mono,强制设为单声道⾳乐可以节省⼀半记忆体使⽤量。
2.如果在机器上的播放效果符合预期,建议采样率设置为22KHz。
3.建议不同设备上的压缩格式可以分别设置为:iOS平台使⽤MP3格式,Android平台使⽤Vorbis格式。
4.建议根据⾳频的⽤途不同,将LoadType设为不同的类型。比如背景⾳乐使⽤Streaming,⾳效使⽤Compressed in Memory。
个案分析

经常检查专案Assets的记忆体占⽤,以这里来看,Matrix4x4⾼达5.4MB是有优化空间的。 Matrix4x4代表场景的Transform资料,本案例由于场景有⾼达16000个物件导致记忆体占⽤较⾼。
压缩格式
1. ASTC
适⽤于A8芯片以上的iOS系统,以及⼤多较新的Android系统;相较于PVRTC和ETC2有更快的压缩速度。

2. PVRTC
在ASTC之前,PVRTC是iOS上的主要纹理压缩格式。

3. ETC2

贴图—压缩
1. 针对平台和质量设定相应的压缩格式
2. Crunch 压缩是建立在DXT或ETC格式之上的破坏压缩,可以进⼀步降低存储空间

Memory Profiler
使⽤Unity MemoryProfiler与Instrument中的Allocation⼯具来找专案的记忆体问题。在如果耗⽤记忆体过
⾼,在使⽤Instrument Allocation时会崩溃,建议团队在优化已知的记忆体问题后,再使⽤Allocation查看⼀
下。 Allocation中⼀个比较重要的关注点是Allocation⼯具中Dirty部分内存的消耗,这部分活跃内存的⼤⼩会
影响到系统是否决定强制关闭程序。以下是在我们⼯程师通过经验总结的不同内存机型Dirty内存最⼤可能的
安全值(IOS10之后系统Swap内存更加积极,该值会有70MB左右的提升)。
团队考量Dirty的总量时需要注意减去Performance tool data的Dirty占⽤,此项为Xcode Instrument本⾝的占
⽤,⼀般⼤⼩为32MB。 【针对这样的问题:游戏切换到后台,在切换回来就会发现有些是被重新启动的,在后面被杀掉了,原因就是文字解释】

载入Assets
任何载入Asset的流程,都可以⽤非同步载入。对于加速画⾯显⽰有帮助
载入时间可以看看是否是⼀个⾕形
如果⽬标机型较⾼,如iPhone6s,可以把Architecture设为ARM64,包体会比较⼩。 (安卓呢? Google已经强制64位了,所以~~~)

垃圾回收 GC
Unity 的记忆体清除过程是透过垃圾回收的来完成的。当数据不再处于被使⽤的状态时,此项功能会对其进⾏收集并从记忆体中清除。如果过于频繁地呼叫会对效能造成影响,这通常会在帧率突然下降时被注意到。
解决该问题的⽅法包括 :
• 在⼀个规定的时间呼叫垃圾回收。
• 使⽤物件池来减少游戏对象实例化和销毁。
• 避免在忙碌时(如 Update)中呼叫。
• 改⽤DOTS架构

GC每个专案状况不同,无法⽤⼀个通则来说明,简单来说就是你程式要优化啦!
物理
1.遊戲中沒有⽤到的物理,就不要勾
2.全部沒⽤就全部不要勾

1.Auto Sync Transforms
关闭这个选项,确保每⼀帧只会处理⼀次Transform的改变。
2.Auto Simulation
关闭这里等于停⽌所有FixUpdate里所有的物理运算,将不会对Tranform做任何更改。如果这里要取消打勾,先确认专案没有OnCollisionEnter和OnTriggerEnter呼叫。
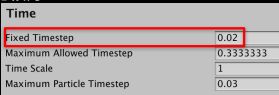
3.游戏中的物理更新时间可以尝试微调
比如0.02->0.05 (50->20次/秒)
4.能⽤几何碰撞体就⽤几何碰撞体,或组合起来。
5.避免在静态物体上放rigidbody增加不必要的计算。
6. 如果脚本有⽤到Physics.RaycastAll(), 建议改为 Physics.RaycastNonAlloc()比较好。
Post Processing Stack V2
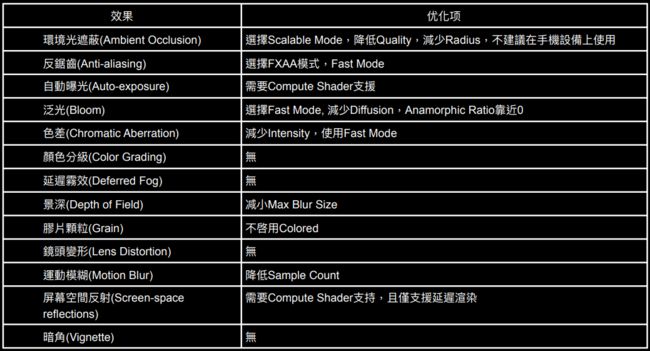

其他常犯错误
1.有全萤幕选单出现时,背后其他选单建议关闭。 【前面UI把后面的UI挡上的时候,后的UI也在显示】
2.全画⾯的特效没播放就不要放在画⾯上
3.Debug.log输出⼤量⽂字也容易造成GC, 在正式发布前必须要确保关闭输出。 (建议做开关)
4.开发者往往以为⼿机解析度比PC⼩, 在RenderTexture或是Post Processing制作时耗费很⾼的记忆体Buffer, 要⼩⼼处理。
iPhoneX解析为 1125 x 2346, ⾼于HD 1080 x 1920 (2xMb)
5.Post Processing Stack v1建议改为v2或未来的v3
6.显⽰⾃订Logo时,就应该开始载入场景资源了 (偶偶,显示Logo的时候就可以加载Assetbundle了,不要浪费任何空闲的时间)
其他常犯错误
1.场景没有寻径却带有Navmesh data
2.尽量避免在最忙碌的时候频繁的Active/Deactive物件每次打开/关闭物件都会⼀个⼀个呼叫旗下Component⼀个⼀个执⾏Enable()/Disable()的指令,如果带有Mesh Renderer这种元件,也会连锁处理底下的资源,对效能影响很⼤。所以要谨慎使⽤GameObject.SetActive(bool)或⽤物件池管理 。
3.在Update呼叫Camera.main(), 这会引⽤FindGameObjectWithTag(“MainCamera”), ⽽且不会暂存下来,建议⾃⾏暂存这个结果并引⽤。
⼀些观念
1.防⽌⼿机发热比跑极速来得重要
2.IL2CPP打包会比较久,包体会变⼤,但效能会变好。
3.WWW弃⽤改WebRequest
4.如果美术觉得有些⼩图压缩后效果不理想⽽选择不压缩,可以试试把图的解析度扩⼤⼀倍,然后压缩。这样在品质接受下压缩过的图片还是比未压缩⼩。
5.压缩图片时要注意贴图尺⼨,不要是长⽅形或NPOT
6.⼀般来说⼿游在同时间Mesh的总占记忆体尽量不要超过30Mb
7.贴图压缩Compression Quality可以设为最⾼品质,减少压缩所带来的品质损失。
⼀些观念
1.截⾄2019初为⽌分析市⾯上⼿机硬体运算能⼒平均值,建议⼀个画⾯的三⾓⾯最优保持在10W,最多不要超过20W。
2.UI解析通常是⽤1920 x 1080的画⾯设计,如果720p的解析看不出差异的话,建议⽤720p减轻记忆体压⼒。
3.参与烘焙的mesh, Normals不要设为none, 避免烘焙时⼀直警告