Tensorflow(2):MNIST识别自己手写的数字--进阶篇(CNN)
本文利用卷积神经网络(CNN)实现自己手写的数字识别。主要参考自Tensorflow中文社区官方教程【Minst进阶】
1.卷积神经网络简介
卷积神经网络是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
卷积网络通过一系列方法,将数据量庞大的图像识别问题不断降维,最终使其能够被训练。CNN最早由Yann LeCun提出并应用在手写字体识别上(MINST),其提出的网络称为LeNet-5,结构如下:
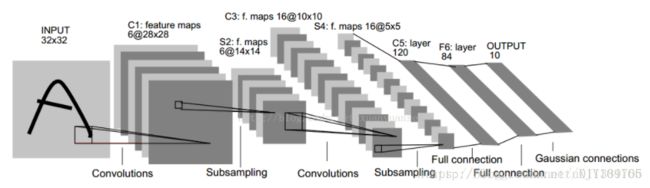
该网络由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
1.1 卷积(Convolutions)
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的,这也意味着我们在这一部分学习的特征也能用在另一部分上。

总结下convolution的处理过程:
假设给定了r * c的大尺寸图像,将其定义为xlarge。首先通过从大尺寸图像中抽取的a * b的小尺寸图像样本xsmall训练稀疏自编码,得到了k个特征(k为隐含层神经元数量),然后对于xlarge中的每个a*b大小的块,求激活值fs,然后对这些fs进行卷积。这样得到(r-a+1)*(c-b+1)*k个卷积后的特征矩阵。
1.2 池化(又叫子采样Subsampling)
在通过卷积获得了特征(features)之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以把所有解析出来的特征关联到一个分类器,例如softmax分类器,但计算量非常大。例如:对于一个96X96像素的图像,假设我们已经通过8X8个输入学习得到了400个特征。而每一个卷积都会得到一个(96 − 8 + 1) * (96 − 8 + 1) = 7921的结果集,由于已经得到了400个特征,所以对于每个样例(example)结果集的大小就将达到892 * 400 = 3,168,400 个特征。这样学习一个拥有超过3百万特征的输入的分类器是相当不明智的,并且极易出现过度拟合(over-fitting).

所以就有了pooling这个方法,其实也就是把特征图像区域的一部分求个均值或者最大值,用来代表这部分区域。如果是求均值就是mean pooling,求最大值就是max pooling。
2.模型训练及保存
根据前面的原理,我们搭建CNN网络对数据进行训练,训练数据来自【Yann LeCun’s MNIST page】。该训练代码改编自Tensorflow中文社区官方教程【Minst进阶】
#-*- coding: UTF-8 -*-
import tensorflow as tf
import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # one_hot 编码 [1 0 0 0]
sess = tf.InteractiveSession()
x = tf.placeholder("float", shape=[None, 784], name='x') # 输入
y_ = tf.placeholder("float", shape=[None, 10], name='y_') # 实际值
# 初始化权重
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 产生正态分布 标准差0.1
return tf.Variable(initial)
# 初始化偏置
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape) # 定义常量
return tf.Variable(initial)
'''
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
input: 输入图像,张量[batch, in_height, in _width, in_channels]
filter: 卷积核, 张量[filter_height, filter _width, in_channels, out_channels]
strides: 步长,一维向量,长度4
padding:卷积方式,'SAME' 'VALID'
'''
# 卷积层
def conv2d(x,W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
'''
tf.nn.max_pool(value, ksize, strides, padding, name=None)
value: 输入,一般是卷积层的输出 feature map
ksize: 池化窗口大小,[1, height, width, 1]
strides: 窗口每个维度滑动步长 [1, strides, strides, 1]
padding:和卷积类似,'SAME' 'VALID'
'''
# 池化层
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 最大池化
# 第一层卷积 卷积在每个5*5中算出32个特征
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1, 28, 28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 密集连接层 图片尺寸缩减到了7*7, 本层用1024个神经元处理
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropout 防止过拟合
keep_prob = tf.placeholder("float", name='keep_prob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 输出层 最后添加一个Softmax层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2, name='y_conv')
# 训练和评估模型
cross_entropy = - tf.reduce_sum(y_ * tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
# 保存模型
saver.save(sess, "E:/MyPython/02MNIST_NN/mnist/minst_cnn_model.ckpt") 最后我们保存训练好的模型到本地,模型的名称为minst_cnn_model.ckpt,包括所有训练好的参数和模型结构。
3.数据测试
我们利用windows自带的画图软件,鼠标手写数字,并保存成png图片(这里我保存成了270*270像素大小),如下图所示:



在代码里,首先定义函数imageprepare()对图片数据进行预处理,转换成28*28像素的灰度图,并将像素值转换到[0,1]范围内。
from PIL import Image
import tensorflow as tf
def imageprepare():
file_name = 'number28_28/5_270_270.png'
myimage = Image.open(file_name)
myimage = myimage.resize((28, 28), Image.ANTIALIAS).convert('L') #变换成28*28像素,并转换成灰度图
tv = list(myimage.getdata()) # 获取像素值
tva = [(255-x)*1.0/255.0 for x in tv] # 转换像素范围到[0 1], 0是纯白 1是纯黑
return tva
result = imageprepare()
init = tf.global_variables_initializer()
saver = tf.train.Saver
with tf.Session() as sess:
sess.run(init)
saver = tf.train.import_meta_graph('minst_cnn_model.ckpt.meta') # 载入模型结构
saver.restore(sess, 'minst_cnn_model.ckpt') # 载入模型参数
graph = tf.get_default_graph() # 加载计算图
x = graph.get_tensor_by_name("x:0") # 从模型中读取占位符张量
keep_prob = graph.get_tensor_by_name("keep_prob:0")
y_conv = graph.get_tensor_by_name("y_conv:0") # 关键的一句 从模型中读取占位符变量
prediction = tf.argmax(y_conv, 1)
predint = prediction.eval(feed_dict={x: [result], keep_prob: 1.0}, session=sess) # feed_dict输入数据给placeholder占位符
print(predint[0]) # 打印预测结果我们利用前面保存的训练好的模型进行识别,在session里,加载保存好的模型及其计算图,同时读取模型中的占位符张量。最后将我们待测试的图片输入到模型里,输出识别结果。
4.识别结果



根据官方实验结果,若模型训练20000次,测试时准确率基本能达到99.2%.
5.注意事项
若识别准确率不高,一般是由于我们手写数字和训练数据相差太大导致的。
一般原因是:(1)自己手动画的数字线条太细了;(2)画的有些数字在图片中的位置没有位于中心;(3)训练集是西方的手写数字,和中国的手写数字习惯不同。下面是官方的训练数据中的部分数字。

在画图时,数字效果(画笔粗细等)尽量和上面训练集保持一致,就会得到较高的识别率!
是以为记!