Neural Networks for Machine Learning by Geoffrey Hinton (6)
- Overview of mini-batch gradient descent
- 错误面
- Full Batch Learning 的收敛性问题
- 学习率问题
- 随机梯度下降法
- 2类学习算法
- 基本批梯度下降法
- 各种批梯度下降法中的小技巧
- 权重值初始化
- 中心化输入Shifting the inputs
- 均一化输入Scaling the inputs
- 更彻底的方法去除相关性
- 多层神经网络中容易出现的问题
- 4种加速批梯度下降的方法
- 动量方法
- 动量的直观理解
- 动量公式
- 极限速度
- 动量的改进版本
- 对不同权重使用单独的自适应学习率
- 思想的初衷
- 一种可行的独立调整方式
- 提高自适应学习率效果的若干技巧
- RMSProp把梯度平均修正
- Rprop仅仅使用梯度的符号
- 为什么Rprop不能用在 mini-batches上面
- RMSPropmini-batch 版本的Rprop
Overview of mini-batch gradient descent
错误面
- 线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。
- 对于多层神经元、非线性网络,在局部依然近似是抛物面。
Full Batch Learning 的收敛性问题
full batch 的方式虽然是朝着梯度最大的方向下降,但是当错误横截面不是圆形的时候,前进的方向并不指向错误最小点,如图1。

图1
学习率问题
如果学习率过大,权重会在错误面上面来回震荡,如图2,我们希望
- 在那些梯度较小,但是连续的方向上,快速前进。
- 在那些梯度较大,但是不连续的方向上,缓慢移动。

图2
随机梯度下降法
如果数据集足够充分,那么用一半的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
极限情况就是每次只用1个样本进行训练,这就是在线(online)学习。
批梯度下降法(Mini-batches)通常比在线学习要好:
- 更少的计算量。
- 矩阵乘法跟适用于GPU。
批梯度下降法需要在训练样本选取上尽量均衡,比如随机选取各类。
2类学习算法
- 使用全数据集的方法(如 non-linear conjugate gradient,非线性联合梯度法)。
- 使用批数据集的批梯度法,通常对于大型神经网络与大型数据集,批梯度下降法更合适,而mini-batch也要选取地足够大,这样在计算上会更高效。
基本批梯度下降法
设置一个初始学习率:
- 如果错误率持续变得糟糕或者剧烈震荡,需要减小学习率。
- 如果错误率基本上是平稳下降,但是非常缓慢,那么应该增加学习率。
在批梯度下降快要结束前,应该尽量减小学习率:
因为在不同的mini-batch之间是有扰动成分的,减小学习率可以消除这个效应。
当错误率不再下降时,也需要减小学习率。
这个错误率是指的验证(validation)数据集,与训练数据集和测试数据集相互独立。
各种批梯度下降法中的小技巧
权重值初始化
如果两个神经元的权重初始值相同,输入和输出层相同,那么它们将不能学习到不同的特征。因此需要使用随机初始化方法来打破这种对称性。
如果一个神经元输入端很多,那么这些输入权重的微小改变将会使得这个神经元反应过于剧烈。
- 因此一般需要按照 fan−in‾‾‾‾‾‾‾‾√ 等比例初始化权重。
- 也可以按照相同的方式等比例放缩学习率。
中心化输入(Shifting the inputs)
中心化即把输入样本全部减去全体样本的均值,这样输入样本具有0均值。
这样做的好处是能够平衡错误面,尽量扩大样本差异性。
均一化输入(Scaling the inputs)
均一化将数据都转化到单位长度上,这样可以把错误面变圆,如图3:

图3
更彻底的方法-去除相关性
对于线性神经元,使用 PCA (Principal Component Analysis) 方法可以去除掉各个成分之间的相关性。
对于球形错误面,梯度方向直接指向最小值处。
多层神经网络中容易出现的问题
如果初始学习率较大,隐含层的权重值将会变成很大的负值,从而梯度会变得很小,错误率会停止下降。
这是因为权重值跑道了一个很远的平面( plateau )上了,而这常常被错误认为是局部极值。
对用于分类的神经网络而言,网络很容易学会一种策略,这种策略让网络按照它应该输出为1的次数,成比例作出输出。
然而让网络学会更多关于输入的信息,会花费漫长的时间。这也因为是到了一个平面上,常常也被错误认为是到了局部最优值。
4种加速批梯度下降的方法
- 使用动量-使用权重的速度而非位置来改变权重。
- 针对不同权重参数使用不同学习率。
RMSProp-这是Prop 的均方根 ( Mean Square ) 改进形式,Rprop 仅仅使用梯度的符号,RMSProp 是其针对 Mini-batches 的平均化版本。
Riedmiller, M., and H. Braun (1993), “A Direct Adaptive Method for Faster Backpropagation Learning: the Rprop Algorithm”, in: IEEE International Conference on Neural Networks, San Francisco, CA, pp. 586-591.
利用曲率信息的最优化方法。
动量方法
动量的直观理解
如图4,小球在错误面上,最初朝梯度方向启动,但一旦具有速度,就不再完全按照梯度最大的方向前进了。
- 动量使得其安装原先的方向运行。
- 动量通过和之前梯度方向的结合显著减小在曲率交大处的震荡现象。
- 动量的结果是让权重以一种温和并连续的梯度方向前进。

图4
动量公式
v(t)=αv(t−1)−ε∂E∂w(t)
α 是衰减系数,是一个比1略小的常数。权重的改变量等于此刻的速度。
Δw(t)=v(t)=αv(t−1)−ε∂E∂w(t)=αΔw(t−1)−ε∂E∂w(t)
极限速度
v(∞)=11−α(−ε∂E∂w)
由于 α 接近1,可以看出极限速度会很大。在训练初始时刻,权重参数可能很大,需要把 α 设置较小(如0.5);当后期大权重系数消失后,权重可能卡在局部最优值中,这时需要将 α 平滑过渡到最终值(0.9或0.99)。
如果没有使用动量,会造成剧烈的震荡现象。
动量的改进版本
Ilya Sutskever 提出了一种新的动量,如图5,核心思想是先按照之前的方向前进,计算新位置的梯度作为修正,然后按照合方向更新权重。本质上是先赌再改的方式。传统方法是先改再赌。
Sutskever, Ilya, et al. “On the importance of initialization and momentum in deep learning.” Proceedings of the 30th international conference on machine learning (ICML-13). 2013.
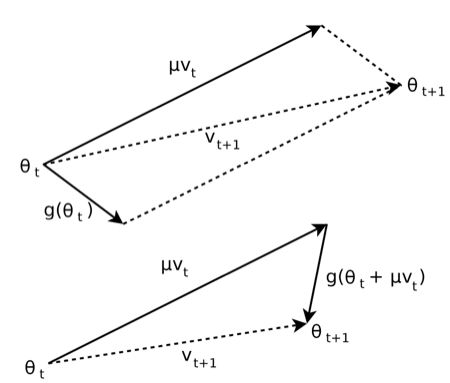
图5
对不同权重使用单独的自适应学习率
思想的初衷
对于多层神经网络结构,针对不同隐含层的最合适的学习率可能相差甚远。
一种可行的独立调整方式
定义局部增益 ( local gain ) gij 作为权重增量的调整系数,根据梯度的符号是否改变来相应调整权重的增量:
Δwij=−εgij∂E∂wijif(∂E∂wij(t)∂E∂wij(t−1))>0thengij=gij(t−1)+0.05elsegij=gij(t−1)∗0.95
- 这种策略保证了当震荡开始时,局部增益显著下降。
- 如果梯度是完全随机的,那么局部增益将会收敛于1附近。
提高自适应学习率效果的若干技巧
- 限制增益在合理范围内,如 [0.1,10] 。
使用Full Batch学习方式或者 Big mini-batches:
这保证了梯度符号的改变并非是由 mini-batch 的采样误差导致。
将自适应学习率与动量结合。
而动量却并不受影响。
RMSProp:把梯度平均修正
Rprop:仅仅使用梯度的符号
由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
对于full batch learning,我们能够只使用梯度的符号,对所有权重都更新相同的大小。
Rprop将只利用梯度符号与针对性单独更新各权值这两种思路结合了起来。
- 如果最近两次梯度符号相同,则乘以 1.2。
- 如果最近两次梯度符号相异,则乘以0.5。
- 让步长限定在合理范围内,如0.00001到50之间。
为什么Rprop不能用在 mini-batches上面?
因为不同mini-batch之间是有采样误差的,这样只要出现一次符号相异,之前积累的步长就完全被抵消了。
RMSProp:mini-batch 版本的Rprop
强制使得每次梯度的调整值非常接近:
vt=αvt−1+(1−α)(∇f)2θt=θt−1+ε∇f(θt−1)vt‾‾√+λ
Dauphin, Yann N., et al. “RMSProp and equilibrated adaptive learning rates for non-convex optimization.” arXiv preprint arXiv:1502.04390 (2015).