MySQL系列—索引相关的数据结构和算法(B+Tree)
MySQL目前提供了以下4种索引。
- B-Tree 索引:最常见的索引类型,大部分引擎都支持B树索引。
- HASH 索引:只有Memory引擎支持,使用场景简单。
- R-Tree 索引(空间索引):空间索引是MyISAM的一种特殊索引类型,主要用于地理空间数据类型。
- Full-text (全文索引):全文索引也是MyISAM的一种特殊索引类型,主要用于全文索引,InnoDB从MYSQL5.6版本提供对全文索引的支持。
衍生索引:主键,唯一索引,组合索引,前缀索引等。hash索引适合key-value查询(等值查询),不适合范围查询。
| 索引 | MYISAM引擎 | InnoDB引擎 | Memory引擎 |
|---|---|---|---|
| B-tree索引 | 支持 | 支持 | 支持 |
| full-text索引 | 支持 | - | - |
| hash索引 | - | - | 支持 |
| R-tree索引 | 支持 | - | - |
通常我们所说的索引是指B-Tree索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引。使用B-Tree这个术语,是因为MySQL在CREATE TABLE或其它语句中使用了这个关键字,但实际上不同的存储引擎可能使用不同的数据结构,比如InnoDB就是使用的B+Tree。
B+Tree中的B是指balance,意为平衡。需要注意的是,B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
在介绍B+Tree前,先了解一下二叉查找树,它是一种经典的数据结构,其左子树的值总是小于根的值,右子树的值总是大于根的值,如下图①。如果要在这课树中查找值为5的记录,其大致流程:先找到根,其值为6,大于5,所以查找左子树,找到3,而5大于3,接着找3的右子树,总共找了3次。同样的方法,如果查找值为8的记录,也需要查找3次。所以二叉查找树的平均查找次数为(3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3次,而顺序查找的话,查找值为2的记录,仅需要1次,但查找值为8的记录则需要6次,所以顺序查找的平均查找次数为:(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3次,因为大多数情况下二叉查找树的平均查找速度比顺序查找要快。
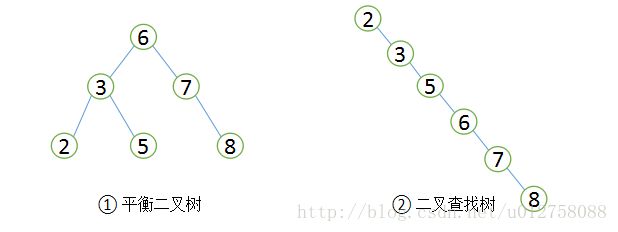
由于二叉查找树可以任意构造,同样的值,可以构造出如图②的二叉查找树,显然这棵二叉树的查询效率和顺序查找差不多。若想二叉查找数的查询性能最高,需要这棵二叉查找树是平衡的,也即平衡二叉树(AVL树)。
平衡二叉树首先需要符合二叉查找树的定义,其次必须满足任何节点的两个子树的高度差不能大于1。显然图②不满足平衡二叉树的定义,而图①是一课平衡二叉树。平衡二叉树的查找性能是比较高的(性能最好的是最优二叉树),查询性能越好,维护的成本就越大。比如图①的平衡二叉树,当用户需要插入一个新的值9的节点时,就需要做出如下变动。

通过一次左旋操作就将插入后的树重新变为平衡二叉树是最简单的情况了,实际应用场景中可能需要旋转多次。至此我们可以考虑一个问题,平衡二叉树的查找效率还不错,实现也非常简单,相应的维护成本还能接受,为什么MySQL索引不直接使用平衡二叉树?
随着数据库中数据的增加,索引本身大小随之增加,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级。可以想象一下一棵几百万节点的二叉树的深度是多少?如果将这么大深度的一颗二叉树放磁盘上,每读取一个节点,需要一次磁盘的I/O读取,整个查找的耗时显然是不能够接受的。那么如何减少查找过程中的I/O存取次数?
一种行之有效的解决方法是减少树的深度,将二叉树变为m叉树(多路搜索树),而B+Tree就是一种多路搜索树。理解B+Tree时,只需要理解其最重要的两个特征即可:第一,所有的关键字(可以理解为数据)都存储在叶子节点(Leaf Page),非叶子节点(Index Page)并不存储真正的数据,所有记录节点都是按键值大小顺序存放在同一层叶子节点上。其次,所有的叶子节点由指针连接。如下图为高度为2的简化了的B+Tree。

怎么理解这两个特征?MySQL将每个节点的大小设置为一个页的整数倍(原因下文会介绍),也就是在节点空间大小一定的情况下,每个节点可以存储更多的内结点,这样每个结点能索引的范围更大更精确。所有的叶子节点使用指针链接的好处是可以进行区间访问,比如上图中,如果查找大于20而小于30的记录,只需要找到节点20,就可以遍历指针依次找到25、30。如果没有链接指针的话,就无法进行区间查找。这也是MySQL使用B+Tree作为索引存储结构的重要原因。
MySQL为何将节点大小设置为页的整数倍,这就需要理解磁盘的存储原理。磁盘本身存取就比主存慢很多,在加上机械运动损耗(特别是普通的机械硬盘),磁盘的存取速度往往是主存的几百万分之一,为了尽量减少磁盘I/O,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存,预读的长度一般为页的整数倍。
页是计算机管理存储器的逻辑块,硬件及OS往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(许多OS中,页的大小通常为4K)。主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
MySQL巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了读取一个节点只需一次I/O。假设B+Tree的高度为h,一次检索最多需要h-1 I/O(根节点常驻内存),复杂度 O(h)=O(logMN) 。实际应用场景中,M通常较大,常常超过100,因此树的高度一般都比较小,通常不超过3。
最后简单了解下B+Tree节点的操作,在整体上对索引的维护有一个大概的了解,虽然索引可以大大提高查询效率,但维护索引仍要花费很大的代价,因此合理的创建索引也就尤为重要。
仍以上面的树为例,我们假设每个节点只能存储4个内节点。首先要插入第一个节点28,如下图所示。

接着插入下一个节点70,在Index Page(非叶子节点)中查询后得知应该插入到50 - 75之间的叶子节点,但叶子节点已满,这时候就需要进行也分裂的操作,当前的叶子节点起点为50,所以根据中间值来拆分叶子节点,如下图所示。

最后插入一个节点95,这时候Index Page和Leaf Page都满了,就需要做两次拆分,如下图所示。
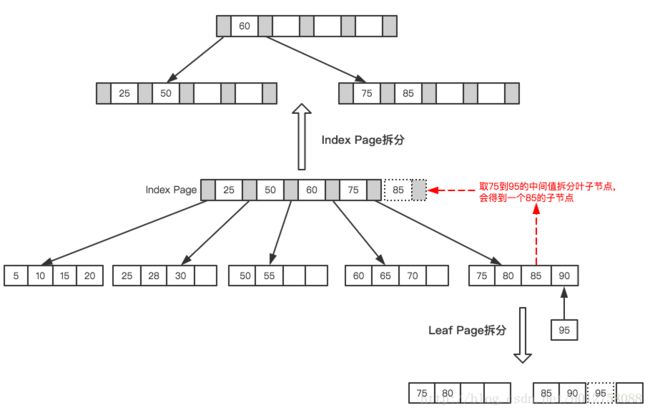
拆分后最终形成了这样一颗树。
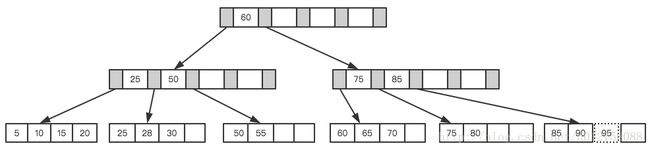
B+Tree为了保持平衡,对于新插入的值需要做大量的拆分页操作,而页的拆分需要I/O操作,为了尽可能的减少页的拆分操作,B+Tree也提供了类似于平衡二叉树的旋转功能。当Leaf Page已满但其左右兄弟节点没有满的情况下,B+Tree并不急于去做拆分操作,而是将记录移到当前所在页的兄弟节点上。通常情况下,左兄弟会被先检查用来做旋转操作。就比如上面第二个示例,当插入70的时候,并不会去做页拆分,而是左旋操作。

通过旋转操作可以最大限度的减少页分裂,从而减少索引维护过程中的磁盘的I/O操作,也提高索引维护效率。需要注意的是,删除节点跟插入节点类型,仍然需要旋转和拆分操作,这里就不再说明。
配合下一篇文章理解:MySQL系列—详解B+Tree