CV-笔记-RetinaNet和Focal Loss
目录
- 1 Focal Loss
- 1.1 之前目标检测中解决样本不平衡的方法
- 1.2 Focal loss
- 1.2.1 普通的加权方式
- 1.2.2 focal loss
- 2 RetinaNet
- 2.1 FPN
- 2.2 anchor
- 2.3 打label
- 2.4 分类分支
- 2.5 回归分支
- 2.6 推理阶段 Inference阶段 也就是预测阶段
- 2.5 训练阶段
- 2.5.1 参数初始化
- 网络训练细节
- 结果
- 引用
1 Focal Loss
文章的题目是Focal Loss for Dense Object Detection,密集目标检测。主要还是解决那些和目标没有交集的anchor的分类,这些anchor是最简单的负样本,但是他们数量巨多。
- 样本不平衡:对于RPN来说大部分anchor都是负样本,对于yolo来说大部分格子都是负样本。
- 两阶段目标检测训练的最后的分类部分通常都是稀疏的,什么意思呢,first stage generates a sparse set of candidate object locations, and the second stage classifies each candidate location as one of the foreground classes or as background using a convolutional neural net- work.(第一阶级会产生一些建议区域,然后第二阶段对这些区域进行分类,这样对第二阶段来说需要分类的区域已经大大减少了,所以说是稀疏的),见 Fast R-CNN。
- 而单阶段的目标检测训练通常是密集的,什么意思呢,就是需要对所有可能区域进行分类,见YOLO。举个例子:以输入为800X800,五层金字塔尺度分别为100X100,50X50,25X25,12X12,6X6,算一下anchor数量,119745, 10几万anchor覆盖在整张图像中,密密麻麻,让你知道什么是密集检测,哈哈,插句话,10几万anchor中绝大多数都是负样本,无用的计算太多,这也是现在anchor free的一个出发点。【2】
- 单阶段检测(高密度检测)训练遇到的主要问题是样本不平衡,因为通常正样本总是小于负样本的,例如yolo是根据目标中心是不是落在格子里,落在格子里那么这个格子就是正样本,否则这个格子就是负样本,那么大部分格子肯定是没有目标的,也就是说正负样本是非常不平衡的。而Fast R-CNN也是,region proposal很多,但是里面大部分区域(anchor)应该是负样本,少部分(anchor)是正样本,所以Fast R-CNN训练分类的时候是通过(稀疏)采样。因为anchor是要分类的,所以大部分anchor是负样本。
- 在这篇文章之前一般都是双阶段的效果比较好(proposal-driven mechanism)。
- 所以有没有办法让单阶段的效果变好,毕竟单阶段的速度快。
- 文章就抓住了训练时候正负样本既不平衡的这个主要矛盾来提高模型精度。最后达到了和FPN, mask R-CNN这样的精度。
- 最好的模型是ResNet-101- FPN(当然是文章提出的时候,现在backbone都有很多优秀的了), 5fps。
1.1 之前目标检测中解决样本不平衡的方法
利用第一阶段过滤到大部分假阳(背景),然后第二阶段再进行下面的工作:
- 对需要分类的区域进行采样,见Fast R-CNN。
- 在线难例挖掘 online hard example mining (OHEM)
相比之下,一个单级目标检测必须处理一组更大的候选对象位置,这些对象位置是通过图像定期采样的。实际上,这常常相当于枚举约100k个位置,这些位置密集地覆盖了空间位置、尺度和纵横比。虽然也可以采用类似的抽样启发法,但它们的效率很低,因为训练过程仍然由容易分类的背景示例所主导。这种低效率是对象检测中的一个经典问题,通常通过引导或硬示例挖掘等技术来解决。
这种不平衡导致了两个问题:(1)训练效率低,因为大多数区域都是简单的负样本,这种简单的负样本对训练作用不大;(2)整体而言,很容易被这些容易的但是很多的负样本影响,导致模型退化。
1.2 Focal loss
- Huber损失(类似smooth L1),该函数通过降低具有较大错误的示例(硬示例)的损失的权重来减少异常值的贡献,因为在误差大的时候损失的梯度是不变的,不变很重要 这样就不容易被误差值所影响,其实也就是差值一个是不进行平方,一个进行平方计算,平方计算就会增长很快,而在误差小的时候梯度慢慢减少。
- 相比之下,Focal loss的重点并不是处理异常值,而是通过减权简单的例子来解决阶级不平衡,这样即使简单的例子的数量很大,它们对总损失的贡献也很小。这点非常重要,是减少简单例子的影响,所以选择这个loss的适合一定要思考你的负样本是不是所谓的简单的负样本。
下面来看一下cross entropy的损失函数曲线(其实就是-log§):
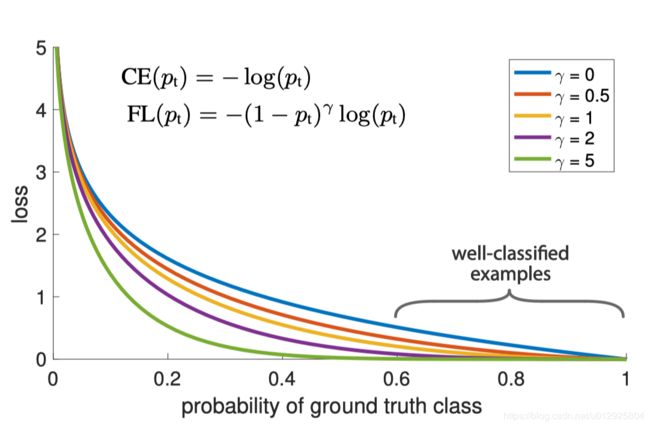
cross entropy可以看着只计算这个神经元负责的当前正样本的loss,假设有两个神经元分别预测目标和背景,那么对于两个神经元来说这两个都是正样本(因为第一个负责预测目标,第二负责预测背景呀,所以第一个神经元的正样本就是目标,第二个神经元的正样本就是背景,都是要预测概率为1的)因为是onehot。
这里有个假设,假设有个正样本,我们预测他为正样本的概率是0.6~1之间,我们就算这个样本是简单的,也就说能预测对的就算是简单的。
所以我们观察上图可以发现,在我们定义的简单样本的区间内,其实普通的cross entropy的loss还是继续下降的(也就是说还是有一点的loss的),因为cross entropy总是希望概率可以很大很确信。所以可以看出focal loss在这个区间内的loss是很小的,而预测不对的话损失是很大的。这就是Focal loss核心思想。划重点。
因为我们希望在目标检测中那么多的负样本不要共享很多loss,预测的差不多得了,能大于0.6就好了,知道你是就行了,超过0.6,loss就少贡献一点,但是因为正负都是同等对待的,所以正样本预测的概率数值也会小一点。
1.2.1 普通的加权方式

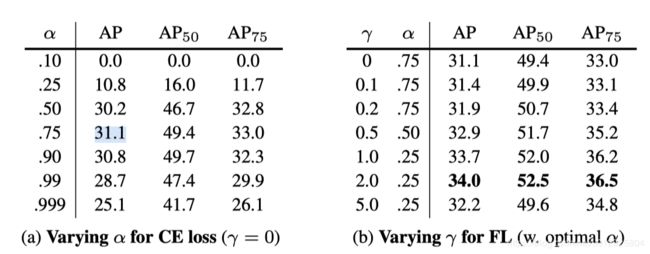
- 虽然alpha参数可以平衡正负样本,但是还无法区分简单和困难的例子,我们希望减少简单例子的权重而关注(Focus)那些难的样本。
- α ∈ [0, 1] for class 1(正样本) and 1−α for class −1(负样本).
- 因为RetinaNet里面是直接预测k个类,而不是先预测是不是目标。所以这里的加权应该是直接在是目标的类别加权α,然后负样本加权1−α。
- 下图可以看出只加α和加了focal与α的α的值是不一样的,与我们直观理解一样只加α的时候正样本的权重应该要高一点,而加了focal以后反而正样本的权重要小一点好:
1.2.2 focal loss
所以focal loss增加了一个调制的因子(1 − pt )^γ,当γ大于0时就是focal loss,等于0的适合是普通的交叉熵loss。
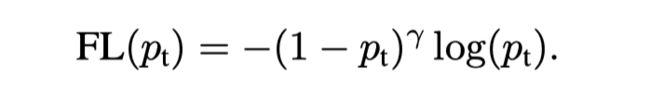
有两点:
- 可以发现当pt趋向于0的时候,
(1 − pt )^γ因子就接近1,loss的值是非常大的,当pt趋向于1的时候(或者说是子啊0.6到1的时候)(1 − pt )^γ这个因子就会解决与0,那么loss贡献就会非常的小,这个和γ参数也有关,γ越大那么预测概率解决于0的时候的loss越小。 - we found γ = 2 to work best in our experiments,作者实验下来 γ = 2的时候最好。
实际使用中作者还加了alpha权重:
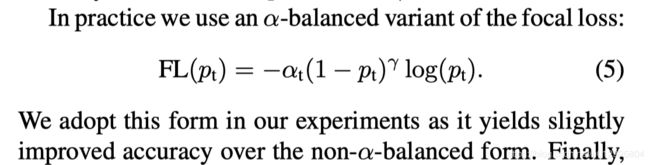
2 RetinaNet
单阶段(one-stage)的目标检测,使用了Focal Loss解决分类的正负样本不平衡问题。
为什么叫这个名字,因为是一个密集目标检测(像视网膜一样密集),这里的密集意思是一次性在所有区域里面检测模型,而不是像两阶段一样从建议区域里面检测。
retinanet只是使用了Focal Loss的一个网络,其他和这个loss无关,采样的都是以前的一些结构,然后很好的组合成一块。
总的结构是这样的:
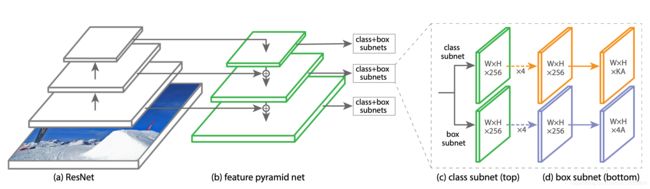
分别说一下RetinaNet里面用的这4个东西的设置:
- FPN
- Anchor
- 打label
- 分类分支
- 回归分支
2.1 FPN
- 右边特征金字塔层(level)从p3到p7用来检测,FPN原文中只是用了p3到p5.We construct a pyramid with levels P3 through P7 , where
lindicates pyramid level (Plhas resolution 2^l(2的l次方) lower than the input). - 金字塔层channel为256。
- P6是在p5上用stride为2的3x3卷积。P7也是这样,然后都有relu。, P 6 is obtained via a 3×3 stride-2 conv on C 5 , and P 7 is computed by applying ReLU followed by a 3×3 stride-2 conv on P 6 .
2.2 anchor
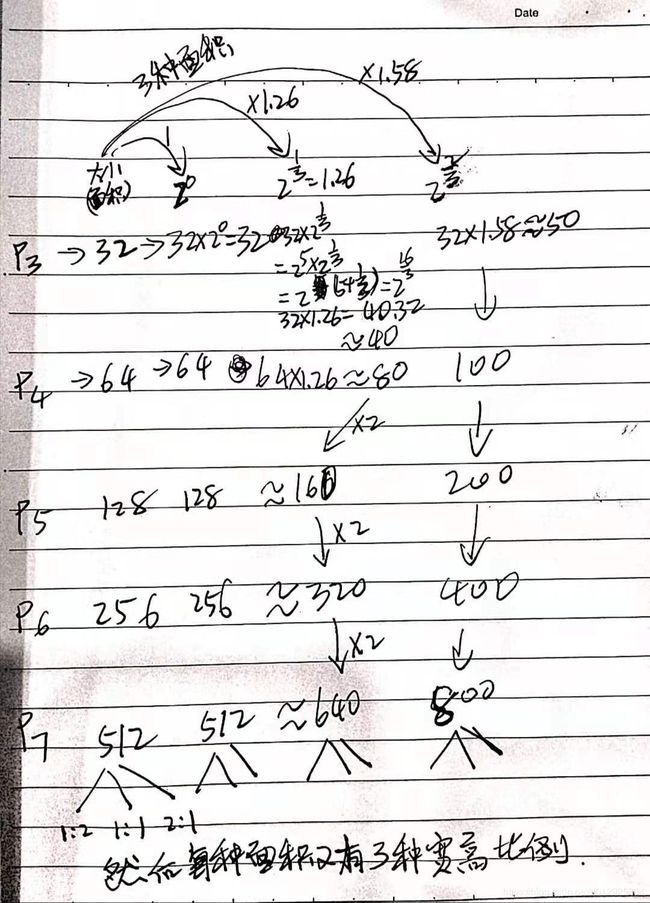
- P3, P4, P5,P6,P7 的基础面积分别是32,64,128,256,512,然后实际面积是基础面积乘以三个倍数,得到三种面积,倍数分别是
2^0=1,2^(1/3)=1.26,2^(2/3)=1.58;然后每种面积都有三种宽高比1:1, 1:2,2:1,所以每个金字塔层总共有9个anchor。
2.3 打label
记住正负样本是对anchor打的。
这里有个特例就是iou=0的时候,iou等于0说明anchor的框是完全和目标没有交集的,这个时候就没有box相对坐标可以回归了。
这里打label的阈值和RPN中有点不同,这里是与目标框iou大于等于0.5的anchor算是正样本,小于0.4的anchor算是负样本,[0.4,5)iou之间不计算loss.
这里来区分一下简单负样本,难负样本:
- 简单负样本:那些和目标框没有交集的anchor,也就是IOU为0的anchor。
- 难负样本:和目标框有交集的,然后iou大于0小于0.4的,当然在这个范围内越接近0.4越难了,因为很接近目标啦,但还是负样本。
2.4 分类分支
- 不同金字塔层的分类分支是参数共享的。
- 分类分支和回归分支没有共同的conv,这个和RPN不一样。
- 分支的conv很多,加上最后一个预测的有5个3x3conv,最后预测的时候也是3x3conv。
- 最后预测的适合是sigmoid激活,而不是softmax。这样好像对Focal loss的使用好,因为可以想象focalloss应用范围都是概率要0到1之间的,softmax是加起来才是1 那可能本身概率就会小一点。
- 每个conv层的channel都是256,最后输出channel是k个类别乘以A个anchor。
- loss除以正样本的个数,loss除以正样本的个数,loss除以正样本的个数
2.5 回归分支
- 4乘A个channel。
- 回归离anchor最近的目标,regressing the offset from each anchor box to a nearby ground-truth object。一个目标可能分配给多个anchor,但是一个anchor只会分配一个目标。
- 回归分支不参数共享,不参数共享,不参数共享,重要的事情说三遍。
那么iou为0的时候要回归坐标吗?负样本要回归坐标吗?:
- regressing the offset from each anchor box to a nearby ground-truth object, if one exists.即如果存在的话要回归,。负样本不计算回归损失,只计算正样本的坐标回归损失,只计算正样本的坐标回归损失,只计算正样本的坐标回归损失重要的事情说三遍。且loss除以正样本的个数,loss除以正样本的个数,loss除以正样本的个数。
2.6 推理阶段 Inference阶段 也就是预测阶段
在推理阶段,由于预测出来的box也很多,分类的置信度阈值卡0.05(为什么这么低?不是0.5吗?因为后面还进行排序然后选前1000)的置信度阈值进行筛选,然后取置信度前1000的候选框(不足1000更好 ,接下来收集所有层的候选框,进行NMS,阈值0.5。
2.5 训练阶段
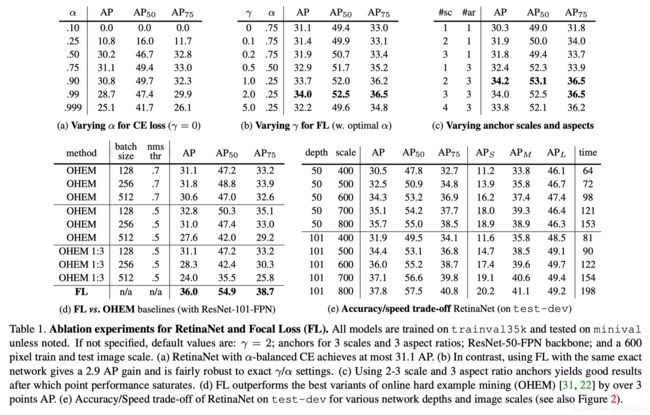
- γ = 2这是最好,是通过【0.5~5】测出来的。
- 再次强调使用所有anchor训练的,We emphasize that when training RetinaNet, the focal loss is applied to all ∼ 100k anchors in each sampled image。以输入为800X800,五层金字塔尺度分别为100X100,50X50,25X25,12X12,6X6,算一下anchor数量,119745个。
- 所有的loss相加哦,然后除以分配的ground-truth box的anchor(有交集)数量,因为简单负样本贡献loss少,几乎为0,难负样本还是贡献loss的,所以加入计算,因为负样本也是和目标框有交集的。The total focal loss of an image is computed as the sum of the focal loss over all ∼ 100k anchors, normalized by the number of anchors assigned to a ground-truth box.
- 因为去除掉iou为0的anchor以后,还剩下一部分有和目标交集的难负样本呀,所以这部分的负样本的数量还是大于正样本的,所以文章中还对loss加了个权重,来平衡这部分的loss。最后我们注意,α,重量分配到罕见的类。Finally we note that α, the weight assigned to the rare class, also has a stable range.(for γ = 2, α = 0.25 works best),这两个参数需要相互结合调整。
- α ∈ [0, 1] for class 1 and 1−α for class −1.
2.5.1 参数初始化
所有新conv层RetinaNet子网中除了最后一个conv外都初始化为bias=0。最后conv层用下面的公式算出来的值初始化,文章中设置为π = .01:
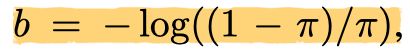
作用:这样初始化可以防止大量的背景锚点在训练的第一次迭代中产生较大的、不稳定的损失值。
网络训练细节
RetinaNet is trained with stochastic gradient descent (SGD). We use synchronized SGD over 8 GPUs with a total of 16 images per minibatch (2 images per GPU). Unless otherwise specified, all models are trained for 90k iterations with an initial learning rate of 0.01, which is then divided by 10 at 60k and again at 80k iterations. We use horizontal image flipping as the only form of data augmentation unless otherwise noted. Weight decay of 0.0001 and momentum of 0.9 are used. The training loss is the sum the focal loss and the standard smooth L 1 loss used for box regression [10]. Training time ranges between 10 and 35 hours for the models in Table 1e.
结果
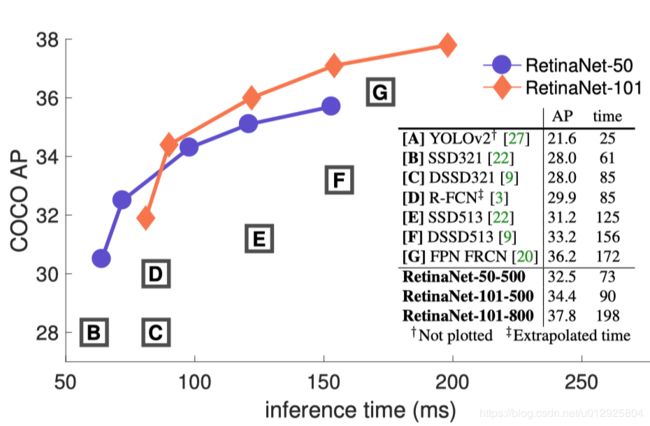
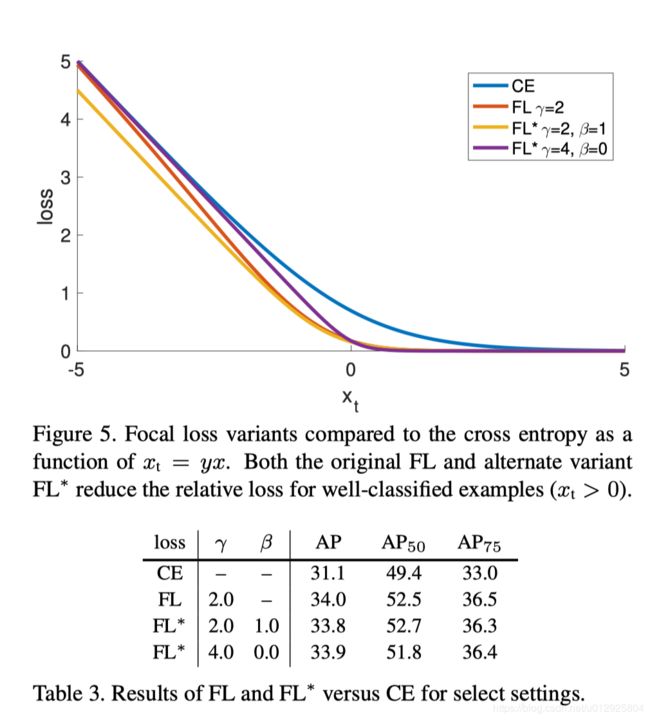
信息量确实很大,文章很好,看不动了,好累,直接贴实验结果吧。


引用
- 各种loss:http://baijiahao.baidu.com/s?id=1603857666277651546&wfr=spider&for=pc
- fpn anchor:https://www.cnblogs.com/wzyuan/p/10847478.html