七、Linux使用与问题分析排查
1.硬链接和软链接的区别?
https://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/index.html
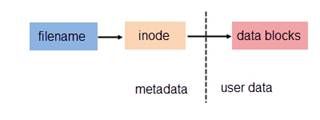
(1)背景:文件都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。图 1.展示了程序通过文件名获取文件内容的过程。
图 1. 通过文件名打开文件
清单 3. 移动或重命名文件
| 1 2 3 4 5 6 7 8 9 10 |
|
在 Linux 系统中查看 inode 号可使用命令 stat 或 ls -i(若是 AIX 系统,则使用命令 istat)。清单 3.中使用命令 mv 移动并重命名文件 glibc-2.16.0.tar.xz,其结果不影响文件的用户数据及 inode 号,文件移动前后 inode 号均为:2485677。
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。
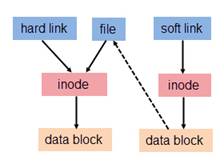
(2)硬链接:若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名(见 图 2.hard link 就是 file 的一个别名,他们有共同的 inode)。硬链接可由命令 link 或 ln 创建。如下是对文件 oldfile 创建硬链接。每添加一个一个硬链接,文件的链接数就加1。
| 1 2 |
|
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;(inode 号仅在各文件系统下是唯一的,当 Linux 挂载多个文件系统后将出现 inode 号重复的现象)
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
(3)软链接:与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接(实际上只是一段文字,里面包含着它所指向的文件的名字,系统看到软链接后自动跳到对应的文件位置处进行处理)。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块(见 图 2.)。因此软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
图 2. 软链接的访问
2.inode是什么?
索引节点号,非文件名称。inode 号仅在各文件系统下是唯一的,当 Linux 挂载多个文件系统后将出现 inode 号重复的现象
3.Linux常用命令有哪些?
4.怎么看一个Java线程的资源耗用?
(1)获取java程序的id
jps -l
(2)虚拟机运行状态信息
jstat gcutil 2764
(2)分析进程号为10599 的线程情况
jstack -l 10242 > stack.log
5.Load过高的可能性有哪些?
进程可运行状态时,它处在一个运行队列run queue中,与其他可运行进程争夺CPU时间。 系统的load是指正在运行和准备好运行的进程的总数。比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的load就是5。load average就是一定时间内的load数量。
衡量CPU 系统负载的指标是load,load 就是对计算机系统能够承担的多少负载的度量,简单的说是进程队列的长度。请求大于当前的处理能力,会出现等待,引起load升高。
造成cpu load过高的原因。从编程语言层次上full gc次数的增大或死循环都有可能造成cpu load 增高
首先要找到哪几个线程在占用cpu,之后再通过线程的id值在堆栈文件中查找具体的线程,看看出来什么问题。
寻找最占CPU的进程
- 通过命令 ps ux
- 通过top -c命令显示进程运行信息列表 (按键P按CPU占有资源排序)
寻找最耗CPU的线程
top -Hp 进程ID 显示一个进程ID的线程运行信息列表 (按键P按CPU占有资源排序)
如果该进程是java进程,需要具体查看是哪段代码造成的CPU负载过高,根据上述获得到的线程ID可以使用JDK下的jstack来查看堆栈。
由于在堆栈中线程id是用16进制表示的,因此可以将上述线程转化成16进制的表示。
jstack java进程id | grep 16进制的线程id -C5 --color
6./etc/hosts文件什么做用?
该文件是Linux主机名的相关配置文件。
Linux 的/etc/hosts是配置ip地址和其对应主机名的文件,这里可以记录本机的或其他主机的ip及其对应主机名。
比如文件中有这样的定义
192.168.102.136 dbfan aeolus
假设192.168.102.136是一台网站服务器,在网页中输入http://dbfan或http://aeolus就会打开192.168.102.136/的网页。dbfan是域名,aeolus是主机名别名
通常情况下这个文件首先记录了本机的ip和主机名:
127.0.0.1 localhost.localdomain localhost
7./etc/resolv.conf文件什么作用?
DNS客户机配置文件,用于设置DNS服务器的IP地址及DNS域名,还包含了主机的域名搜索顺序。
该文件是由域名解析器(resolver,一个根据主机名解析IP地址的库)使用的配置文件。它的格式很简单,每行以一个关键字开头,后接一个或多个由空格隔开的参数。
示例
domain 51osos.com
search www.51osos.com 51osos.com
nameserver 202.102.192.68
nameserver 202.102.192.69r
nameserver:定义DNS服务器的IP地址。可以有很多行的nameserver,每一个带一个IP地址。在查询时就按nameserver在本文件中的顺序进行,且只有当第一个nameserver没有反应时才查询下面的nameserver。
domain: 定义本地域名。当为没有域名的主机进行DNS查询时,也要用到。如果没有域名,主机名将被使用,删除所有在第一个点( .)前面的内容。
search:定义域名的搜索列表。它的多个参数指明域名查询顺序。当要查询没有域名的主机,主机将在由search声明的域中分别查找。domain和search不能共存;如果同时存在,将会使用后面出现的。
sortlist:对返回的域名进行排序。允许将得到域名结果进行特定的排序。它的参数为网络/掩码对,允许任意的排列顺序。
8.如何快速的将一个文本中所有“abc”替换为“xyz”?
方法1
对于一个文件中统一替换字符串,用vim就可以实现,方法也比较简单:
:s/XXX/YYY/g
其中XXX是需要替换的字符串,YYY是替换后的字符串
以上这句只对当前行进行替换,如果需要进行全局替换,则要:
:%s/XXX/YYY/g
如果需要对指定部分进行替换,可以用V进入visual模式,再进行
:s/XXX/YYY/g
或者可以指定行数对指定范围进行替换:
:100, 102s/XXX/YYY/g
方法2
Linux下批量替换多个文件中的字符串的简单方法。用sed命令可以批量替换多个文件中的字符串。
sed -i "s/原字符串/新字符串/g" `grep 原字符串 -rl 所在目录`(千万注意这个符号,是最左上角那个符号不是单引号)
例如:我要把/test下所有包含abc的文件中的abc替换为def,执行命令:
sed -i "s/abc/def/g" `grep abc -rl /test`
这是目前linux最简单的批量替换字符串命令了!
方法3:
在日程的开发过程中,可能大家会遇到将某个变量名修改为另一个变量名的情况,如果这个变量是一个局部变量的话,vi足以胜任,但是如果是某个全局变量的话,并且在很多文件中进行了使用,这个时候使用vi就是一个不明智的选择。这里给出一个简单的shell命令,可以一次性将所有文件中的指定字符串进行修改:
grep "abc" * -R | awk -F: '{print $1}' | sort | uniq | xargs sed -i 's/abc/abcde/g'
替换字符:sed -i "s/old/new/g" /test
查找包含指定字符的文件名:grep aaa –ul /test
9.你常用的Linux下用来进行网络和磁盘IO分析的工具有哪些?
https://blog.csdn.net/qq_43227570/article/details/84333747
(1)网络
| 工具 | 描述 |
|---|---|
| ping | 主要透过 ICMP 封包 来进行整个网络的状况报告 |
| traceroute | 用来检测发出数据包的主机到目标主机之间所经过的网关数量的工具 |
| netstat | 用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况 |
| ss | 可以用来获取socket统计信息,而且比netstat更快速更高效 |
| host | 可以用来查出某个主机名的 IP,跟nslookup作用一样 |
| tcpdump | 是以包为单位进行输出的,阅读起来不是很方便 |
| tcpflow | 是面向tcp流的, 每个tcp传输会保存成一个文件,很方便的查看 |
| sar -n DEV | 网卡流量情况 |
| sar -n SOCK | 查询网络以及tcp,udp状态信息 |
//显示网络统计信息
netstat -s
//显示当前UDP连接状况
netstat -nu
//显示UDP端口号的使用情况
netstat -apu
//统计机器中网络连接各个状态个数
netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
//显示TCP连接
ss -t -a
//显示sockets摘要信息
ss -s
//显示所有udp sockets
ss -u -a
//tcp,etcp状态 sar -n TCP,ETCP 1
//查看网络IO sar -n DEV 1
//抓包以包为单位进行输出
tcpdump -i eth1 host 192.168.1.1 and port 80
//抓包以流为单位显示数据内容
tcpflow -cp host 192.168.1.1(2)IO
| 工具 | 描述 |
|---|---|
| iostat | 磁盘详细统计信息 |
| iotop | 按进程查看磁盘IO的使用情况 |
| pidstat | 按进程查看磁盘IO的使用情况 |
| perf | 动态跟踪工具 |
iotop命令是一个用来监视磁盘I/O使用状况的top类工具。iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。Linux下的IO统计工具如iostat,nmon等大多数是只能统计到per设备的读写情况,如果你想知道每个进程是如何使用IO的就比较麻烦,使用iotop命令可以很方便的查看。
//查看系统io信息
iotop
//统计io详细信息
iostat -d -x -k 1 10
//查看进程级io的信息
pidstat -d 1 -p pid
//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常
perf record -e block:block_rq_issue -ag
perf report10.你常用的Linux下用来进行内存和CPU分析的工具有哪些?
(1)内存
| 工具 | 描述 |
|---|---|
| free | 缓存容量统计信息 |
| vmstat | 虚拟内存统计信息 |
| top | 监视每个进程的内存使用情况 |
| pidstat | 显示活动进程的内存使用统计 |
| pmap | 查看进程的内存映像信息 |
| sar -r | 查看内存 |
| dtrace | 动态跟踪 |
| valgrind | 分析程序性能及程序中的内存泄露错误 |
说明:
- free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
- valgrind可以分析内存泄漏问题。
- dtrace动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
使用方式
//查看系统内存使用情况
free -m
//虚拟内存统计信息
vmstat 1
//查看系统内存情况
top
//1s采集周期,获取内存的统计信息
pidstat -p pid -r 1
//查看进程的内存映像信息
pmap -d pid
//检测程序内存问题
valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
(2)cpu
| 工具 | 描述 |
|---|---|
| uptime | 平均负载 |
| vmstat | 包括系统范围的cpu平均负载 |
| mpstat | 查看所有cpu核信息 |
| top | 监控每个进程cpu用量 |
| sar -u | 查看cpu信息 |
| pidstat | 每个进程cpu用量分解 |
| perf | cpu剖析和跟踪,性能计数分析 |
说明:
- uptime,vmstat,mpstat,top,pidstat只能查询到cpu及负载的的使用情况。
- perf可以跟着到进程内部具体函数耗时情况,并且可以指定内核函数进行统计,指哪打哪。
//查看系统cpu使用情况
top
//查看所有cpu核信息
mpstat -P ALL 1
//查看cpu使用情况以及平均负载
vmstat 1
//进程cpu的统计信息
pidstat -u 1 -p pid
//跟踪进程内部函数级cpu使用情况
perf top -p pid -e cpu-clock11.发现磁盘空间不够,如何快速找出占用空间最大的文件?
[root@localhost data]# find / -type f -size +10G
/usr/local/apache2/logs/access_log
然后可以通过du命令查看此文件的大小:
( du -sh * 查看根目录下每个文件夹的大小)
[root@localhost data]# du -h /usr/local/apache2/logs/access_log24G /usr/local/apache2/logs/access_log
12.Java服务端问题排查(OOM,CPU高,Load高,类冲突)
(1)OOM
java -Xmx10m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./oom.out HeapMemUseTest
分析OOM的工具推荐使用MAT,使用MAT分析dump下来的文件。mat会将内存问题暴露出来。
(2)cpu高
1.使用命令 ps -ef | grep 找出异常java进程的pid. 找出pid为 20189

2. top -H -p 20189,所有该进程的线程都列出来了。看看哪个线程pid占用最多,然后将这个pid转换为16进制,我这里是22718转换完58be,注意要小写
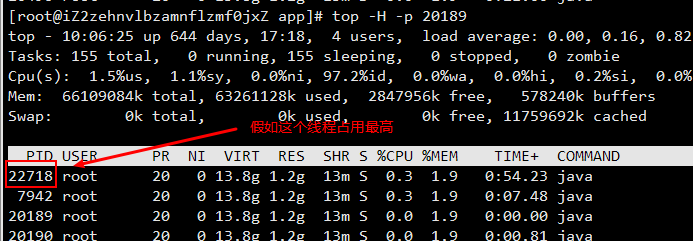

3. jstack 20189 > jstack.log 将java进程信息导出到文件,在jstack.log文件中搜索 58be
类似于下图,可以通过线程名或包名之类的判断是那个线程.

https://dongyajun.iteye.com/blog/613352
(4)类冲突
如果有异常堆栈信息,根据错误信息即可定位导致冲突的类名,然后在eclipse中CTRL+SHIFT+T或者在idea中CTRL+N就可发现该类存在于多个依赖Jar包中
若步骤1无法定位冲突的类来自哪个Jar包,可在应用程序启动时加上JVM参数-verbose:class或者-XX:+TraceClassLoading,日志里会打印出每个类的加载信息,如来自哪个Jar包
定位了冲突类的Jar包之后,通过mvn dependency:tree -Dverbose -Dincludes=
确定Jar包来源之后,如果是第一类Jar包冲突,则可用
13.Java常用问题排查工具及用法(top, iostat, vmstat, sar, tcpdump, jvisualvm, jmap, jconsole)
jps:虚拟机进程状况工具
jstat:虚拟机统计信息监视工具
jinfo:java配置信息工具
jmap:java内存映像工具。切换到JDK_HOME/bin/,执行以下命令:jmap -dump:format=b,file=heap.hprof 2576 (2576是我当前需要分析的java进程PID).
jhat:虚拟机堆转储快照分析工具。 jhat是用来分析java堆的命令,可以将堆中的对象以html的形式显示出来,包括对象的数量,大小等等,并支持对象查询语言。jhat -port 5000 heap.hrof
jstack:java堆栈跟踪工具。jstack 2576 > thread.txt
jconsole:观测Java进程信息的一个不错的工具,java监视和管理控制台。内存监控,线程监控(显示死锁信息等)
visualvm: 包含jconsole的功能,增加堆转储快照,分析程序性能(profile标签)
14.Thread dump文件如何分析(Runnable,锁,代码栈,操作系统线程ID关联)
(1)通过就jps找到对应的进程id后,可以使用jstack查看对应的堆栈信息。
(2)通过一些可视化工具更加方便的查看死锁位置,对象生存时间,垃圾回收等信息.例如:jconsole,visualVm,eclipse memory analyzer tool(MAT)
15.grep,awk,sed; 是否自己写过shell脚本;
grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
sed
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk是 AWK的 GNU版本
16.常见的cpu load过高,us过高,一般是什么问题。
Top命令是Linux下常用的系统性能分析工具,能实时查看系统中各个进程资源占用情况。
(1)衡量CPU 系统负载的指标是load,load 就是对计算机系统能够承担的多少负载的度量,简单的说是进程队列的长度。请求大于当前的处理能力,会出现等待,引起load升高。
造成cpu load过高的原因.从编程语言层次上full gc次数的增大或死循环都有可能造成cpu load 增高。
(2)us:指用户态占用cpu使用率非常高
17.常见的内存问题一般有哪些。 引申出是否用过free,top, jmap等。
内存泄漏(找到泄漏对象的gc root引用链,并查找到对象通过怎样的路径与gc root关联,并导致垃圾收集器无法自动回收它的),内存溢出等。堆溢出,栈溢出(达到堆容量的最大值时)