Channel Pruning for Accelerating Very Deep Neural Networks 算法笔记
论文:Channel Pruning for Accelerating Very Deep Neural Networks
论文链接:https://arxiv.org/abs/1707.06168
代码地址:https://github.com/yihui-he/channel-pruning
这是一篇ICCV2017的文章,关于用通道剪枝(channel pruning)来做模型加速,通道减枝是模型压缩和加速领域的一个重要分支。
文章的核心内容是对训练好的模型进行通道剪枝(channel pruning),而通道减枝是通过迭代两步操作进行的:第一步是channel selection,这一步是采用LASSO regression来做的,其实就是添加了一个L1范数来约束权重,因为L1范数可以使得权重中大部分值为0,所以能使权重更加稀疏,这样就可以把那些稀疏的channel剪掉;第二步是reconstruction,这一步是基于linear least squares(也就是最小二乘,或者叫最小平方)来约束剪枝后输出的feature map要尽可能和减枝前的输出feature map相等,也就是最小二乘值越小越好。可以看出本文的通道剪枝是对训练好的模型进行的,也就是文章说的inference time,当然作者在最后的conclusion中也提到以后会在train time中也引进通道剪枝,希望能减少训练的时间。
原文中作者列举的加速效果:Our pruned VGG-16 achieves the state-of-the-art results by 5 speed-up along with only 0.3% increase of error. More importantly, our method is able to accelerate modern networks like ResNet, Xception and suffers only 1.4%, 1.0% accuracy loss under 2 speedup respectively, which is significant.
本文采用的通道剪枝(channel pruning)是模型压缩和加速领域中一种简化网络结构的操作,文中作者还列举了其他两种常见的简化网络结构的操作:sparse connection和tensor factorization,可以看Figure1的对比。(a)表示传统的3层卷积操作。(b)表示sparse connection,这是通过去掉一些参数很小的连接得到的,理论上是有明显的加速效果的,但是在实现过程中并不容易,主要因为稀疏连接层的形状不规则。(c)表示tensor factorization,比如SVD分解,但是这种操作其实并不会减少channel数量,因此很难带来明显加速。(d)就是通道剪枝(channel pruning),也就是直接对channel做剪枝,移除掉一些冗余的channel,相当于给网络结构瘦身,而且各个卷积层的形状还比较统一。

Figure2是本文对卷积层做通道剪枝的一个示意图。先看左边大的虚线框,其中字母B表示输入feature map,同时c表示B的通道数量;字母W表示卷积核,卷积核的数量是n,每个卷积核的维度是c*kh*kw,kh和kw表示卷积核的size;字母C表示输出feature map,通道数是n。因此通道剪枝的目的是要把B中的某些通道剪掉,使得剪掉后的B和W的卷积结果能尽可能和C接近。当要剪掉B中的一些feature map的通道时,相当于剪掉了W中与这些通道对应的卷积核(对应W中3个最小的立方体块),这也是后面要介绍的公式中β的含义和之所以用L1范数来约束β的原因,因为L1范数会使得W更加稀疏。另外生成这些被剪掉通道的feature map的卷积核也可以删掉(对应Figure2中第二列的6个长条矩形块中的2个黑色虚线框的矩形块)。
因此最重要的就是如何判断B中的哪些通道要剪掉,具体是分两步来迭代进行的:In one step, we figure out the most representative channels, and prune redundant ones, based on LASSO regression. In the other step, we reconstruct the outputs with remaining channels with linear least squares. We alternatively take two steps. Further, we approximate the network layer-by-layer, with accumulated error accounted.
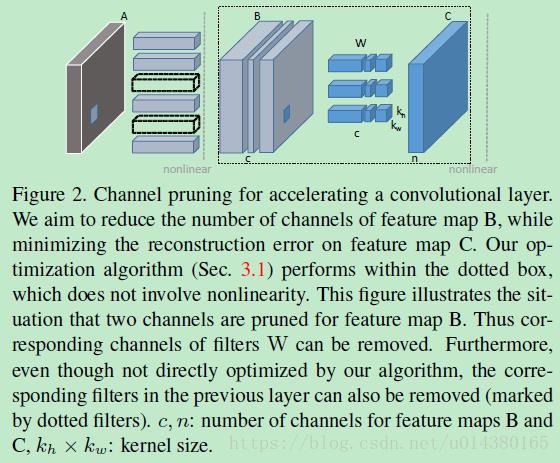
公式1就是优化方程。首先字母c表示待剪枝的feature map的通道数,待剪枝的feature map也就是该卷积层的输入feature map;W表示卷积核,维度是n*c*kh*kw,因此n就是输出feature map的通道数;X表示从输入feature map中取出的N个维度为c*kh*kw的samples。因此当卷积核W去卷积X时,得到的就是N*n大小的输出Y,这里要解释下N*n的含义,其实是输出n个feature map,每个feature map的长*宽等于N,因此这里相当于把二维的feature map拉直成一个向量,这样Y就是二维的,方便公式1中计算平方。β是一个向量,里面的值只有0或者1,当要丢掉某个channel的时候,β的对应位置就是0. || ||F是F范数。c’表示剪枝后feature map的通道数,因此最终要达到的目的是将通道数从c剪到c‘。
所以公式1的意思是:首先β的0范数要小于等于c‘,也就是说β向量中非零值的数量要小于c’。然后最小二乘部分的Y表示未剪枝时的输出feature map;求和部分表示按照β来剪枝后的输出feature map,因此这个优化式子是希望二者之间的差异越小越好,所以采取最小二乘(也就是最小平方)的方法来求β和权重W。

当然,上面的式子是没有办法直接优化求解的,因此有了下面的公式2。公式2是将公式1中对β的约束加到公式中,同时使用L1范数代替原来β的L0范数,因为L0难以优化,而且有数学证明L1范数可以替换L0范数。参数λ用来控制β中非零值的数量,λ越大,β中的非零值越少,这样加速比也越大。另外||Wi||F=1是用来约束W的唯一解。
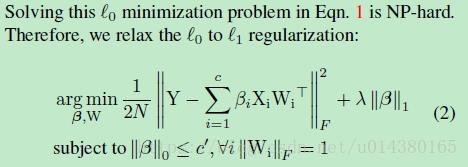
从前面的介绍可以看出最终这个优化式子要求的是最优的β和W,因此具体优化的时候是迭代进行的:先固定W,求解β,然后固定β,求解W。比如公式3就是固定W(XW用Z表示),求解β的公式。
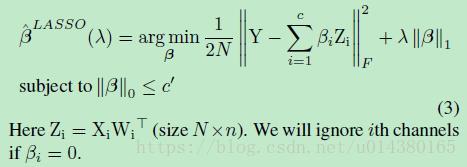
公式4就是固定β,求解W的公式。
![]()
优化中的一个细节是前面公式中的λ是在迭代过程中不断增大的,直到||β||0稳定以后就不增大了。
一旦满足β的约束:
![]()
就得到了所需的β和W。当然作者在实验中发现这样迭代操作比较耗时间,因此采取的策略是先不断优化公式3,直到达到上面这个β的约束时再优化公式4一次。
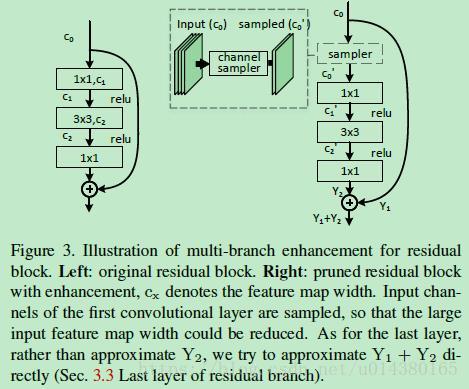
前面介绍的都是对于网络没有分支情况下的通道剪枝,但是现在的ResNet、GoogleNet网络都有多分枝,对于这种网络,文中以ResNet为例也做了分析,如图Figure3。首先,在这个residual block中,除了第一层和最后一层外的其他层都可以采用前面介绍的通道剪枝方式进行剪枝。针对第一层,因为原来其输入feature map的通道数是输出的4倍,因此在剪枝之前先对输入feature map做sample。针对最后一层的通道剪枝,由原来对Y2来优化,改成对Y1-Y1‘+Y2来优化(Y1和Y2表示剪枝之前的输出),Y1’表示前面层剪枝后得到的结果(也就是该residual block的输入,只不过和Y1不同的是该输入是前面层剪枝后得到的结果),否者shortcut部分带来的误差会对结果影响较大。
实验结果:
Figure4是在VGG16网络上对单层做不同的channel selection方式的实验结果对比,用来证明本文的这种channel selection算法的有效性。图例中fist k表示抽取前k个channel作为剪枝后的channel,max response表示选取卷积核权重的绝对值最大的一些channel作为剪枝后的channel。可以看出随着层数的增加,channel pruning的难度也增加,这表明在浅层中存在更多的冗余channel,这也是后面对模型做channel pruning时候对浅层和高层采取不同程度剪枝的依据(浅层剪枝得更加厉害,比如从conv1_x到conv3_x剪枝后剩余的通道数与conv4_x剪枝后剩余的通道数的比例是1:1.5,而conv5_x是不剪枝的,一方面因为conv5_x计算量少,另一方面从实验结果看其冗余率已经很低了)。

Table1是对整个VGG-16网络做通道剪枝的结果,可以看出在2倍加速的时候甚至没有影响到准确率。

Table2是作者在VGG-16网络上将本文的通道剪枝和spatial factorization、channel factorization结合在一起(对应表中的Our 3C)做加速的实验结果对比,可以看出结合不同的加速算法的效果都要优于某一种加速算法。
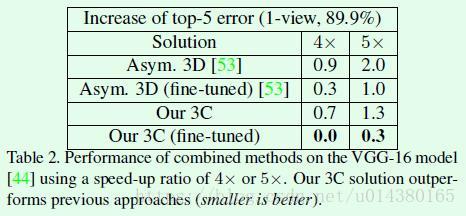
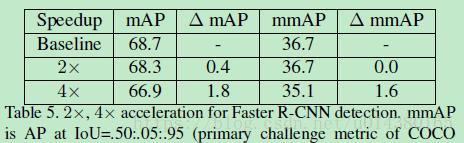
Table5是作者将加速算法用在object detection算法上的表现,这里是以Faster RCNN为例子。
其他更多实验结果可以参看论文,比如对于ResNet和Xception的通道剪枝的实验结果、train from scratch等。