从零开始的Hadoop大数据集群(伪)搭建,全免费VirtualBox虚拟机Ubuntu版,学习向,超详细---(三)
一、搭建hadoop集群
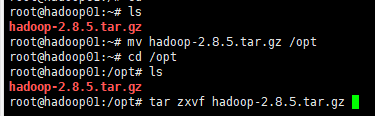
这节搭建hadoop,首先去hadoop官网下载hadoop-2.8.5的包。然后启动虚拟机,打开xshell,上传到hadoop01服务器上。
如图:

接着将其拷贝到/opt下。然后执行解压命令:
mv hadoop-2.8.5.tar.gz /opt
cd /opt
tar zxvf hadoop-2.8.5.tar.gz
解压好之后,可以开始配置了。
cd hadoop-2.8.5/etc/hadoop/
ll
可以看到如图所示:
首先这个hadoop里面是有文档的。如果你在windows环境解压好,可以看到在share/doc/hadoop里有index.html,这个就是文档了。

我们点击左边的cluster step,这个就是集群搭建。里面有非常详细的配置。我这里就不说了,直接按照上面的文档进行配置。
首先 vim core-site.xml (请自行手打,不习惯linux可以拷贝到windows环境下)

然后 vim hdfs-site.xml

执行 cp mapred-site.xml.template mapred-site.xml
然后 vim mapred-site.xml

然后 vim yarn-site.xml

然后 vim hadoop-env.sh
修改export JAVA_HOME=/usr/local/jdk1.8 如图:(重要!即使你配了系统环境变量java_home,这里也要修改!)

然后 vim slaves (你有几台slave就写几台)
这里有几个要点,注意:
(1)我给的配置,都是最少配置。大部分都使用默认配置。详细的默认配置参考官方文档。如图

官方文档给了全部的默认配置和详细说明。(后悔没好好学英语吧)
(2)有人觉得我的配置比其他文章配置都少很多,后面是需要你自己去学习每一个配置做什么用的。
我给的配置能够完全运行hadoop集群的。其他的配置请自行学习和研究!
写好所有的配置之后,执行远程拷贝,将hadoop拷贝到每一台机器上!(可以删除里面的html文档再拷贝,这样节约很多空间)
scp -r /opt/hadoop-2.8.5 root@hadoop02:/opt/
scp -r /opt/hadoop-2.8.5 root@hadoop03:/opt/
scp -r /opt/hadoop-2.8.5 root@hadoop04:/opt/
scp -r /opt/hadoop-2.8.5 root@hadoop05:/opt/
二、测试wordcount
所有准备工作做好之后,接下来就要测试集群是否能够正常运行了。
我们先配置环境变量。
vim /etc/profile
添加hadoop的环境,如图:

算上以前配置的java环境变量。总共是这么多。
然后 source /etc/profile
接着格式化集群。运行:hadoop namenode -format
接着启动集群。运行
start-all.sh (注意,会提示你这个脚本已经废弃)结果如下图:

接着,测试一下。
执行 hdfs dfs -mkdir /user/root
如果执行成功,就会在hdfs上建立这个文件夹。
查看一下,执行hdfs dfs -ls /
然后我们运行官方文档的例子WordCount。
打开官方文档,左边找到Tutorial 如图:

按照 上面的步骤来,首先找个地方建立 WordCount.java文件,接着输入代码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 然后 执行(官方文档有更详细的。我们这里配置过JAVA_HOME了,直接运行这个就好)
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
接下来执行:
hadoop com.sun.tools.javac.Main WordCount.java
jar cf wc.jar WordCount*.class
结果如下:
![]()
我们建立输入文件夹。执行
hdfs dfs -mkdir -p /user/root/wordcount/input
随便找一个文章放进去。就去hadoop文件里面找吧。
hdfs dfs -put /opt/hadoop-2.8.5/README.txt /user/root/wordcount/input
然后执行
hadoop jar wc.jar WordCount wordcount/input wordcount/output

出现这样的说明运行成功。接着,我们查看一下运行结果。
hdfs dfs -cat wordcount/output/*
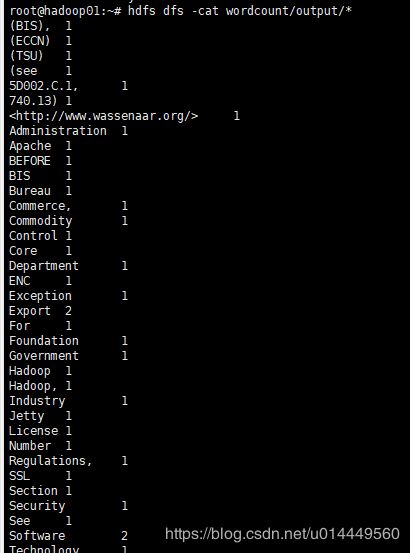
至此,hadoop集群环境搭建完毕。