Python爬虫(一)——爬取古诗文网,初识什么是爬虫
首先来说下什么是爬虫,按照百度百科的说法是:是一种按照一定规则,自动抓取万维网信息的程序或者脚本;首先它是程序,需要我们定义好规则,然后程序就会按照定义好的规则抓取网络上的信息,数据抓取下来了之后,需要我们对这个庞大的数据进行筛选、提取,也就是我们通常说的数据清洗,获得我们需要的信息。这里需要说的一点是,爬虫并不是python的专利,用其他的语言也是可以做到的,只是因为python提供了很多方便我们工作的库,可以极大的降低我们开发的难度,所以使用python开发爬虫非常多。
好了,我们简单的讲一下什么是爬虫:爬虫其实就是模拟了我们打开网页,获取网络信息的这一过程,只是他不用把过程显示出来,他默默完成这些工作,按照我们定义的规则,将打开的页面中特定的信息存储起来供我们使用。
使用python爬取信息,我们可以使用的工具和框架非常多,后面我们慢慢的学习;首先先来看一下,最简单的文字的提取,找到一个古诗文网站,网站的结构相较简单,可以帮助对爬虫这一概念很快的理解。
使用工具及环境:
- Python3.6
- 谷歌浏览器
先来分析下我们需要在古诗文网站获取李白的全部古诗,需要做哪几步?
- 首先我们肯定需要知道在哪个网址获取,并且打开那个网址——https://www.gushiwen.org/

- 我们需要获取李白的诗,那么肯定是在作者里面找到李白,或者直接在搜索栏直接搜索李白(这个我们后面再讲)
下面我们不啰嗦,直接找到李白的诗文页面: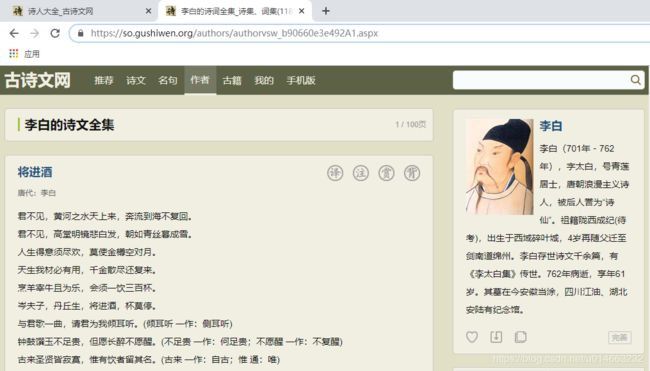
- 我们现在已经找到李白诗文所在的页面,接下来只需要将这些诗文保存起来就好了,那么现在我们要解决两个问题:
1)怎么将诗文提取出来,并保存起来;
2)我们发现上面标注了,李白的诗一共有100页,那么我们怎么把这100页诗文一次性下载下来 - 首先我们解决第一个问题,怎么把诗文提取出来?
说到这里,我们就要介绍一下网页是怎么构成的,像古诗文网它就是一个静态网站,不同的页面直接指向一个新的地址,我们操作的每一步其实都是在打开一个新的页面,操作的每一步其实就是一个超链接,有兴趣的可以观察一下你们一步步打开的网址;他们是用HTML语言来写的,它的中文名字叫超文本标记语言,它是一种解释型语言,这个是什么意思:
首先我们字面理解一下超文本,首先是个文本,标记它其实就是用不同的标签组织页面的结构,就像是国家,国家是个大的标签,然后标签下面还有省市区,一级一级下来,每一级都有它需要表达的内容;解释型语言就是,我们可以把浏览器当做是一个解释器,我们的python其实也是一个解释型语言,它的代码语句是一行一行解释下来的,你会发现python在执行代码的时候,一行代码有问题,他不会马上表现出来,知道他在执行到的那一刻才会报错,这就是因为他在解释的时候解释不通,不知道该怎么办了。
那么我们是不是可以把这个页面的源码调出来,我们不就可以通过这个源码找到我们需要的内容了嘛?
我们可以通过快捷键 “Ctrl+U” ,或者右击网页空白的地方,点击 “查看网页源代码” 将网页源码打开: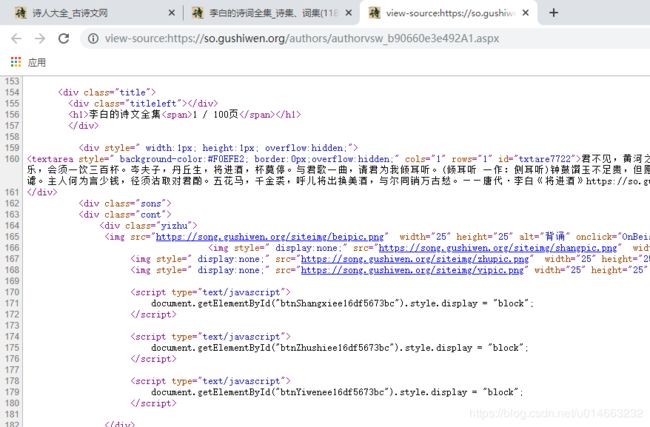
我们发现确实找到了诗文,但是这个页面有八百多行代码,没有基础的话看着头皮都发麻,那么有没有什么比较快的方法找到我们需要的那部分内容在什么位置呢?
我们右击网页中诗文的部分,然后选择 “检查”,我们发现弹出了一个窗口,里面显示和很多代码,这些代码跟我们之前看到的源码貌似很相似,我们后面就可以通过这个工具来查看源码,分析网页的结构,找出规律,从而构建爬取的规则: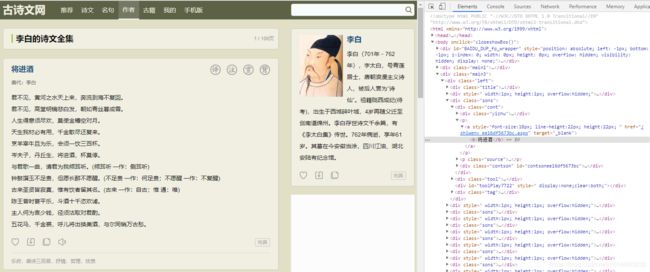
我们把其他隐藏起来的代码块点开,发现就是我们需要的内容: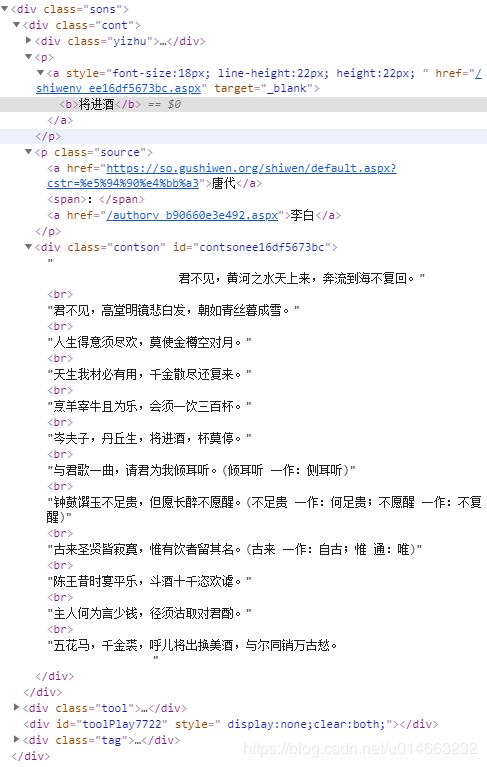
- 第二个问题,刚才说一共有一百个页面,我们怎么处理这100个页面呢?总不能写100个网址吧……
还是一样的,我们总结一下规律:https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx # 李白诗文第一页 https://so.gushiwen.org/authors/authorvsw_b90660e3e492A2.aspx # 李白诗文第二页 https://so.gushiwen.org/authors/authorvsw_b90660e3e492A3.aspx # 李白诗文第三页 ……我们发现网址是有规律的,只是最后一位有变化,那么我们是不是可以循环执行一百次,将网址重新拼接,访问,在提取内容;
这个仅限于有规律的网站,如果没有规律的话,我们发现一般网站最下面都有下一页,我们可以获取下一页的网址,然后访问,也是一样的。
好了,说的这么多,现在我们用代码来说明:
import requests # requests就是我们用来请求网页的库
# 如果没有用 pip install requests 安装
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx' # 访问的网址
result = requests.get(url) # 对目标网址发出请求
print(result) # 我们将访问的结果输出,看看返回了什么
print(result.status_code) # 打印状态码
print(result.url) # 打印请求url
print(result.headers) # 打印头信息
print(result.cookies) # 打印cookie信息
print(result.text) # 以文本形式打印网页源码
print(result.content) # 以字节流形式打印
# 输出结果:
# # 返回的就是响应的结果,200即为访问成功
# 200
# https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx
# {'Server': 'Tengine', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding, *', 'Cache-Control': 'public', 'Expires': 'Mon, 09 Dec 2019 12:17:34 GMT', 'X-AspNet-Version': '4.0.30319', 'X-Powered-By': 'UrlRewriter.NET 1.7.0, ASP.NET', 'Date': 'Mon, 09 Dec 2019 00:48:37 GMT', 'Ali-Swift-Global-Savetime': '1575852517', 'Via': 'cache23.l2cn1827[0,200-0,H], cache7.l2cn1827[2,0], cache9.cn1447[0,200-0,H], cache3.cn1447[1,0]', 'Age': '30454', 'X-Cache': 'HIT TCP_MEM_HIT dirn:6:387273622', 'X-Swift-SaveTime': 'Mon, 09 Dec 2019 01:52:45 GMT', 'X-Swift-CacheTime': '37489', 'Timing-Allow-Origin': '*', 'EagleId': '6f034f9715758829713824707e', 'Content-Encoding': 'gzip'}
#
# 最后面两项太长了,这里就不显示了 ok,什么状态码、头信息、cookie不清楚是什么,不用管,我们目前用不到,后面会详细讲的,但是有一个,我们最后是不是从源码分析的,所以我们需要返回页面的源码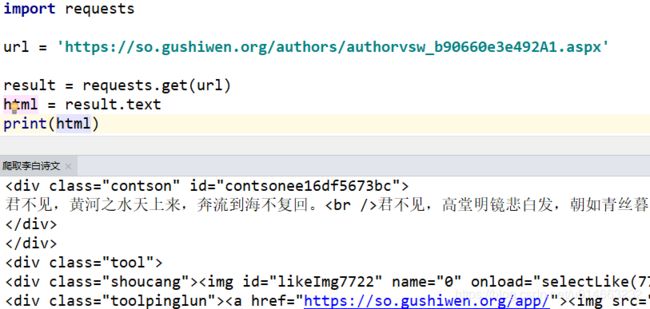
现在我们源码也有了,怎么找出我们需要内容呢?
我们文本匹配的方式很多,因为我们需要的内容都是标签的值,正则表达式在这种情况下不好匹配,所以我们选用xpath进行内容的提取,如果这一部分不了解的话,可以百度或看我的另一篇博文;
data = html.xpath('//div[@class="sons"]') # 根据源码分析,我们发现所有的诗文信息都是在里面的
# 所以我们先把所有的找出来
for d in data:
title = d.xpath('./div[@class="cont"]/p/a/b/text()') # 一层一层找,题目在这里
author = d.xpath('./div[@class="cont"]/p[@class="source"]/a/text()') # 朝代和作者
sw_all = '' # 最后将诗文拼接成字符串
sw = (d.xpath('./div[@class="cont"]/div/text()')) # 先将诗文所有的行全部获取下来
for s in sw: # 遍历所有的行
if s != '\n': # 我们发现会有很多空行产生,这个是我们不需要的
if s[0] == '\n': # 还有些在开头的时候会有一个换行
sw_all += s[1:] # 我们需要将换行符屏蔽掉,注意换行符是一个字符
else:
sw_all += s # 将其拼接在一起
sw_all += '\n' # 在每一行后面都加上一个换行符,这样所有的语句就不会都在一行上面
if sw_all == '': # 还有一种情况是,较短的诗文,里面还有一层标签,那么上面的循环就会全部过滤掉了
sw = (d.xpath('./div[@class="cont"]/div/p/text()')) # 重新匹配
for s in sw: # 跟上面的操作是一样的
if s != '\n':
if s[0] == '\n':
sw_all += s[1:]
else:
sw_all += s
sw_all += '\n'
现在我们已经可以匹配到所有的诗文信息了,接下来就是将诗文保存起来:
try: # 异常处理
# 这里先提前创建好了文件夹,需要注意点的是:有些题目中间有 '/' 分隔,最后合成文件名就会变成路径的一部分
# 这肯定是有问题的,所以我们需要将题目中的 '/' 替换掉
with open('./李白/{}({}).txt'.format(title[0].replace('/',' '),author[1]),'w') as f:
f.write(title[0]+'\n'+author[0]+' '+author[1]+'\n'+sw_all) # 将内容写入
except:
print('{}下载失败!'.format(title[0])) # 如果出现异常情况,提示那首诗文出现了问题
下面看一下全部的代码:
import requests
from lxml import etree
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx'
result = requests.get(url).text
html = etree.HTML(result)
data = html.xpath('//div[@class="sons"]')
for d in data:
title = d.xpath('./div[@class="cont"]/p/a/b/text()')
author = d.xpath('./div[@class="cont"]/p[@class="source"]/a/text()')
sw_all = ''
sw = (d.xpath('./div[@class="cont"]/div/text()'))
for s in sw:
if s != '\n':
if s[0] == '\n':
sw_all += s[1:]
else:
sw_all += s
sw_all += '\n'
if sw_all == '':
sw = (d.xpath('./div[@class="cont"]/div/p/text()'))
for s in sw:
if s != '\n':
if s[0] == '\n':
sw_all += s[1:]
else:
sw_all += s
sw_all += '\n'
try:
with open('./李白/{}({}).txt'.format(title[0].replace('/',' '),author[1]),'w') as f:
f.write(title[0]+'\n'+author[0]+' '+author[1]+'\n'+sw_all)
except:
print('{}下载失败!'.format(title[0]))
好了,现在还有最后一个问题,我们现在只是下载了一个页面的文章,如何获取所有的诗文呢?
我们这里直接采用最暴力的方法,直接凭借访问地址:
import requests
from lxml import etree
for n in range(1,101): # 从第1页到第100页
try: # 这里加上异常处理非常关键,如果页面出错,不会终止程序
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A{}.aspx'.format(str(n)) # 拼接访问地址
result = requests.get(url).text
html = etree.HTML(result)
data = html.xpath('//div[@class="sons"]')
for d in data:
title = d.xpath('./div[@class="cont"]/p/a/b/text()')
author = d.xpath('./div[@class="cont"]/p[@class="source"]/a/text()')
sw_all = ''
sw = (d.xpath('./div[@class="cont"]/div/text()'))
for s in sw:
if s != '\n':
if s[0] == '\n':
sw_all += s[1:]
else:
sw_all += s
sw_all += '\n'
if sw_all == '':
sw = (d.xpath('./div[@class="cont"]/div/p/text()'))
for s in sw:
if s != '\n':
if s[0] == '\n':
sw_all += s[1:]
else:
sw_all += s
sw_all += '\n'
try:
with open('./李白/{}({}).txt'.format(title[0].replace('/',' '),author[1]),'w') as f:
f.write(title[0]+'\n'+author[0]+' '+author[1]+'\n'+sw_all)
except:
print('{}下载失败!'.format(title[0]))
except:
print('第{}页下载失败'.format(n))

确实可以下载,但是只有100首,按理一个页面是10首,100个页面应该是1000首才对,找一下问题,我们看下第十一页:

惊奇的发现,竟然十页之后的内容,要我们用客户端才能访问,真是不想再说什么了;好了,这就是最简单的文本爬取的方法,有疑问或者没有讲清楚的,可以在下面留言哈!