机器学习模型评分总结(sklearn)
文章目录
- 目录
- 模型评估
- 评价指标
- 1.分类评价指标
- acc、recall、F1、混淆矩阵、分类综合报告
- 1.准确率
- 方式一:accuracy_score
- 方式二:metrics
- 2.召回率
- 3.F1分数
- 4.混淆矩阵
- 5.分类报告
- 6.kappa score
- ROC
- 1.ROC计算
- 2.ROC曲线
- 3.具体实例
- 2.回归评价指标
- 3.聚类评价指标
- 1.Adjusted Rand index 调整兰德系数
- 2.Mutual Information based scores 互信息
- 3.Homogeneity, completeness and V-measure
- 4.Fowlkes-Mallows scores
- 5.Silhouette Coefficient 轮廓系数
- 6.Calinski-Harabaz Index
- 4.其他
目录
模型评估
有三种不同的方法来评估一个模型的预测质量:
- estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题。
- Scoring参数:使用cross-validation的模型评估工具,依赖于内部的scoring策略。见下。
- 通过测试集上评估预测误差:sklearn Metric函数用来评估预测误差。
评价指标
评价指标针对不同的机器学习任务有不同的指标,同一任务也有不同侧重点的评价指标。
主要有分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、热门主题模型(topic modeling)、推荐(recommendation)等。
1.分类评价指标
acc、recall、F1、混淆矩阵、分类综合报告
1.准确率
方式一:accuracy_score
# 准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)
Out[127]: 0.33333333333333331
accuracy_score(y_true, y_pred, normalize=False) # 类似海明距离,每个类别求准确后,再求微平均
Out[128]: 3
方式二:metrics
宏平均比微平均更合理,但也不是说微平均一无是处,具体使用哪种评测机制,还是要取决于数据集中样本分布
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。
微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。参考博客
from sklearn import metrics
metrics.precision_score(y_true, y_pred, average='micro') # 微平均,精确率
Out[130]: 0.33333333333333331
metrics.precision_score(y_true, y_pred, average='macro') # 宏平均,精确率
Out[131]: 0.375
metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro') # 指定特定分类标签的精确率
Out[133]: 0.5
其中average参数有五种:(None, ‘micro’, ‘macro’, ‘weighted’, ‘samples’)
2.召回率
metrics.recall_score(y_true, y_pred, average='micro')
Out[134]: 0.33333333333333331
metrics.recall_score(y_true, y_pred, average='macro')
Out[135]: 0.3125
3.F1分数
metrics.f1_score(y_true, y_pred, average='weighted')
Out[136]: 0.37037037037037035
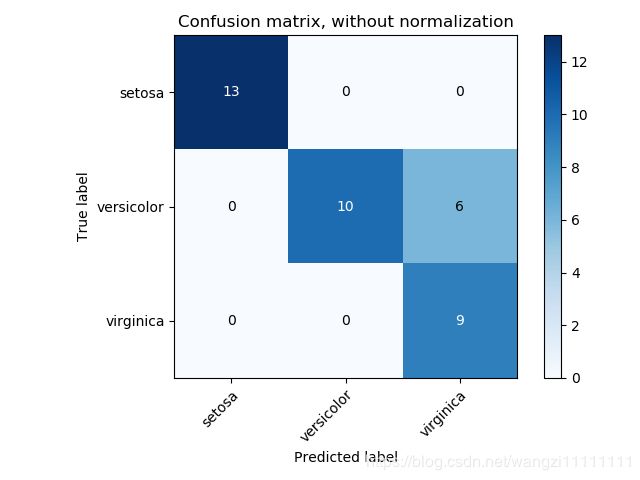
4.混淆矩阵
# 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
Out[137]:
array([[1, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 1],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0]])
横为true label 竖为predict
5.分类报告
# 分类报告:precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 2, 0]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
包含:precision/recall/fi-score/均值/分类个数
6.kappa score
kappa score是一个介于(-1, 1)之间的数. score>0.8意味着好的分类;0或更低意味着不好(实际是随机标签)
from sklearn.metrics import cohen_kappa_score
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
cohen_kappa_score(y_true, y_pred)
ROC
1.ROC计算
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
2.ROC曲线
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
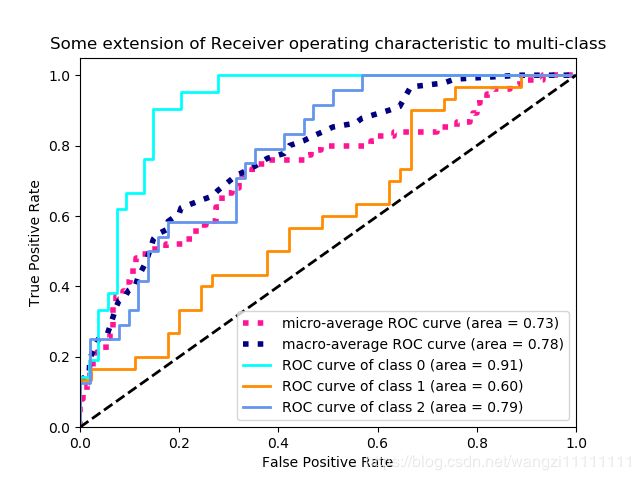
3.具体实例
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
# Import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 画图
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
plt.figure()
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
2.回归评价指标
回归是对连续的实数值进行预测,而分类中是离散值。



3.聚类评价指标
参考博客
1.Adjusted Rand index 调整兰德系数

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
2.Mutual Information based scores 互信息

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504
3.Homogeneity, completeness and V-measure
同质性homogeneity:每个群集只包含单个类的成员。
完整性completeness:给定类的所有成员都分配给同一个群集。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.homogeneity_score(labels_true, labels_pred)
0.66...
>>> metrics.completeness_score(labels_true, labels_pred)

4.Fowlkes-Mallows scores

5.Silhouette Coefficient 轮廓系数

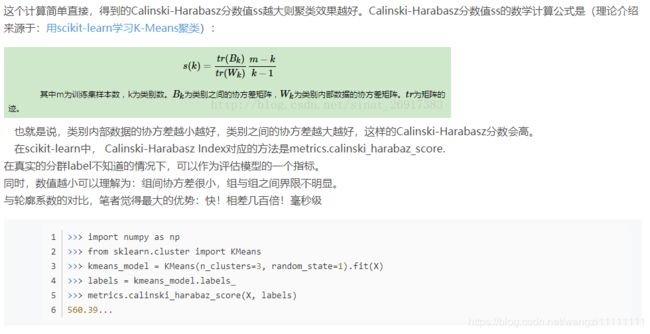
6.Calinski-Harabaz Index