TensorflowOnSpark-集群版
参考:
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN
http://www.cnblogs.com/heimianshusheng/p/6768019.html
基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
http://www.tuicool.com/articles/a6ziUzf
软件:
虚拟机 ubuntu16.04.01 LTS
Getting Started TensorFlowOnSpark on Hadoop Cluster
Before you start, you should already be familiar with TensorFlow and have access to a Hadoop grid with Spark installed. If your grid has GPU nodes, they must have cuda installed locally.
1、
安装Hadoop,Spark
参考:
http://www.itnose.net/detail/6478156.html
Spark On YARN 分布式集群安装
http://blog.csdn.net/dream_an/article/details/52946840
Hadoop2.7.3完全分布式集群部署过程
参考:安装Hadoop,Spark集群模式
在 Master 节点(hadoop1)上进行:
2、Install Python 2.7 (如果有自带python2.7 可以在自带的Python上按下面的步骤安装,不需再安装python2.7)
这一步的是在本地文件夹里下载安装 Python ,目的是在进行任务分发的时候能够把这个 Python 和其他依赖环境(这里指的是包含 TensorFlow)同时分发给对应的 Spark executor ,所以这一步不是单纯的只安装 Python 。
#下载解压 Python 2.7
export PYTHON_ROOT=~/Python #/root/Python 设置环境变量(vim /etc/profile #写入在该文件中 source /etc/profile)
curl -O https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz #下载安装包
也可以使用 wget https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz #下载安装包
也可以直接打开连接 https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz #Windows下载
tar -xvf Python-2.7.12.tgz -C ~/ #解压安装包
rm Python-2.7.12.tgz # 删除安装
#在编译 Python 之前,需要完成以下工作,否则编译产生的 python 会出现没有 zlib 、没有 SSL 模块等错误
#安装 ruby , zlib , ssl 相关包
sudo apt install ruby
sudo apt-get install zlib1g-dev(
sudo apt install zlib1g,zlib1g.dev)
sudo apt install libssl-dev
#进入刚才解压的 Python 目录,修改 Modules/Setup.dist文件,该文件是用于产生 Python 相关配置文件的
cd Python-
2.7
.
12
sudo vim Modules/Setup.dist
#去掉 ssl , zlib 相关的注释:
#与 ssl 相关:
#SSL=/usr/local/ssl
#_ssl _ssl.c \
# -DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
# -L$(SSL)/lib -lssl -lcrypto
#与 zlib 相关:
#zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz
#编译 Python 到本地文件夹 ${PYTHON_ROOT}
cd ~
pushd Python-2.7.12
./configure --prefix="${PYTHON_ROOT}" --enable-unicode=ucs4
#./configure 这一步如果提示 "no acceptable C compiler" , 需要安装 gcc : sudo apt install gcc
make
make install
popd
rm -rf Python-2.7.1
#安装 pip
pushd "${PYTHON_ROOT}"
curl -O https://bootstrap.pypa.io/get-pip.py
# wget https://bootstrap.pypa.io/get-pip.py #下载速度快
bin/python get-pip.py
rm get-pip.py
#安装 pydoop
# 先停止Hadoop,spark 再重新启动Linux(否则安装pydoop会出错)
# 如果一直弹出 LocalModeNotSupported
# 可以尝试下重新配置hadoop,再重新启动服务 即可!!!
${PYTHON_ROOT}/bin/pip install pydoop
#这里安装 pydoop,若是提示错误:LocalModeNotSupported,直接下载资源包通过 setup 安装:
#资源包下载:
https://pypi.python.org/pypi/pydoop
wget https://pypi.python.org/packages/75/75/085a6410b085f231328884ca3349287a8705822ad8afdca715401e5c4f33/pydoop-1.2.0.tar.gz
#tar -xvf pydoop-1.2.0.tar.gz
#cd pydoop-1.2.0
#python setup.py build
#python setup.py install
#安装 TensorFlow (
worker节点
上也需要安装 Python2.7(
只需在自带的版本安装)
对应的TensorFlow)
${PYTHON_ROOT}/bin/pip install tensorflow
# 默认安装最新版本
#这里安装 tensorflow ,不需要从源码进行编译安装,除非你需要 RDMA 这个特性
或者
${PYTHON_ROOT}/bin/pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp27-none-linux_x86_64.whl
# 安装0.12.1版本
sudo pip install tensorflow==0.12.1
# gpu版本
sudo pip install tensorflow.gpu==0.12.1
popd
# 视情况而定(不是必要的步骤)
cd /opt/hadoop-2.6.5/sbin
./start-all.sh #(先启动hadoop)
cd /opt/spark-1.6.0/sbin
./start-all.sh #(先启动spark)
cd ~
(2) 安装 TensorFlowOnSpark
cd ~
git clone https://github.com/yahoo/TensorFlowOnSpark.git
git clone https://github.com/yahoo/tensorflow.git
#从 yahoo 下载的 TensorFlowOnSpark 资源包里面 tensorflow 是空的文件夹,git 上该文件夹连接到了 yahoo/tensorflow ,这里需要我们将 tensorflow 拷贝到 TensorFlowO#nSpark 下面:
sudo rm -rf TensorFlowOnSpark/tensorflow/
sudo mv tensorflow/ TensorFlowOnSpark/
#上面 tensorflow 和 TensorFlowOnSpark 文件目录根据自己的实际情况修改,我的是在根目录下面,所以如上
(3) 安装编译 Hadoop InputFormat/OutputFormat for TFRecords
#安装以下依赖工具:
sudo apt install autoconf,automake,libtool,curl,make,g++,unzip,maven(
如果出错 分开安装
)
#先安装 protobuf
apt install maven
# apt install protobuf-compiler(不使用这句 它只会安装2.6版本,我们需要3.x版本,如果安装了
apt-get purge
protobuf-compiler 卸载掉
http://blog.csdn.net/get_set/article/details/51276609
)
安装 protobuf 参考下面的
地址:https://github.com/google/protobuf/releases
选择
Source code
(tar.gz)下载
tar -zxvf protobuf-3.1.0.tar.gz -C /usr/local/
cd protobuf-3.1.0/
# 如果使用的不是源码,而是release版本 (已经包含gmock和configure脚本),可以略过这一步
./autogen.sh
# 指定安装路径
./configure --prefix=/usr/local/protobuf
#编译
make
# 测试,这一步很耗时间
make check
make install
# refresh shared library cache.
ldconfig
设置一下环境变量 /etc/profile
vim /etc/profile
# (动态库搜索路径) 程序加载运行期间查找动态链接库时指定除了系统默认路径之外的其他路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib
# (静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/libexport PATH=$PATH:/usr/local/protobuf/bin
source
/etc/profile
查看版本
protoc --version
之后,对于相同的系统环境,就不需要再编译了,直接将编译好的protobuf(目录:/usr/local/protobuf)分发到其他计算机,设置环境变量即可。
# git 上有详细说明:github上有详细的安装说明:https://github.com/google/protobuf/blob/master/src/README.md
#也可以参考链接:
http://www.itdadao.com/articles/c15a1006495p0.html
#编译 TensorFlow 的 protos:
git clone https://github.com/tensorflow/ecosystem.git
cd ecosystem/hadoop
protoc --proto_path=/root/TensorFlowOnSpark/tensorflow/ --java_out=src/main/java/ /root/TensorFlowOnSpark/tensorflow/tensorflow/core/example/{example,feature}.proto
source /etc/profile
mvn clean package
mvn install
#将上一步产生的 jar 包上传到 HDFS
cd target
cd /root/ecosystem/hadoop/target
hadoop fs -put tensorflow-hadoop-1.0-SNAPSHOT.jar(
如果出错
使用下面那句)
hadoop fs -mkdir -p tensorflow-hadoop-1.0-SNAPSHOT.jar

出现错误:
Call From hadoop1/192.168.101.49 to Hadoop1:9000 failed on connection exception
先停止spark、hadoop(如果启动了)(启动时先启动hadoop,再是spark)
cd /opt/spark-1.6.0/sbin
./stop-all.sh #(先启动spark)
cd /opt/hadoop-2.6.5/sbin
./stop-all.sh #(先启动hadoop)
vim
/opt/hadoop-2.6.5/etc/hadoop/
core-site.xml
将Hadoop1:9000 改成hadoop1
:9000 (hadoop1,2,3都需修改)
修改完后,在
依次
启动hadoop、spark(hadoop1 上启动)
cd /opt
source /etc/profile
bin/
hdfs namenode -format
#格式化namenode,如果启动了namenode,下次启动hadoop就不用再使用这句,
重复使用
会导致DataNode无法启动
cd /opt/hadoop-2.6.5/sbin
./start-all.sh #(先启动hadoop)
如果还是无法启动
namenode
/home/wu/hadoop/dfs/name/current 或者
手动创建该目录
、或者在该目录内创建和删除文件
cd /opt/spark-1.6.0/sbin
./start-all.sh #(先启动spark)
source /etc/profile
jps
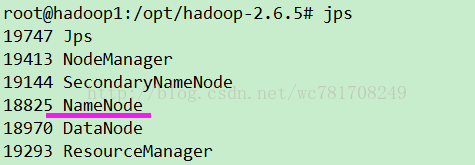
cd
/root/ecosystem/hadoop/target
注:
如果出现hadoop连接错误,先停止hadoop,在重启,即可
如果出现
put: `.': No such file or directory
使用
hadoop fs -mkdir -p tensorflow-hadoop-1.0-SNAPSHOT.jar
HDFS上没建用户主目录,执行hadoop fs -mkdir /user,hadoop fs -mkdir /user/<用户名>,再上传。
注:
必须启动hadoop 和 spark
(4) 为 Spark 准备 Python with TensorFlow 压缩包
pushd
"${PYTHON_ROOT}"
zip -r Python.zip *popd
#将该压缩包上传到 HDFS
hadoop fs -put ${PYTHON_ROOT}/Python.zip (
如果出错
使用下面那句)
hadoop fs -mkdir -p ${PYTHON_ROOT}/Python.zip
hadoop fs -ls
# 查看上传的文件 或者
hdfs dfs -ls
(5) 为 Spark 准备 TensorFlowOnSpark 压缩包
pushd TensorFlowOnSpark
zip -r ./tfspark.zip *
popd
以上便完成 环境的搭建
以下可以参考官网:
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN
http://www.cnblogs.com/heimianshusheng/p/6768019.html
4. 测试[5]
1)准备数据
下载、压缩mnist数据集
mkdir ${HOME}/mnist
pushd ${HOME}/mnist >/dev/null
curl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"
zip -r mnist.zip *
popd >/dev/null
注:如果下载慢 使用
wget +链接
下载
2)feed_dic方式运行,步骤如下
# step 1 设置环境变量
# set environment variables (if not already done)
vim /etc/profile
export PYTHON_ROOT=~/Python
export LD_LIBRARY_PATH=${PATH}
export PYSPARK_PYTHON=${PYTHON_ROOT}/bin/python
export SPARK_YARN_USER_ENV="PYSPARK_PYTHON=Python/bin/python"
export PATH=${PYTHON_ROOT}/bin/:$PATH
export QUEUE=gpu
# set paths to libjvm.so, libhdfs.so, and libcuda*.so
#export LIB_HDFS=/opt/cloudera/parcels/CDH/lib64 # for CDH (per @wangyum)
export LIB_HDFS=$HADOOP_PREFIX/lib/native/Linux-amd64-64
export LIB_JVM=$JAVA_HOME/jre/lib/amd64/server
export LIB_CUDA=/usr/local/cuda-7.5/lib64 # 指定cuda地址(如果不对手动更改)
export SPARK_HOME=/opt/spark-1.6.0
source /etc/profile
# for CPU mode:
# export QUEUE=default
# remove --conf spark.executorEnv.LD_LIBRARY_PATH
# remove --driver-library-path
# step 2 上传文件到hdfs
# step 2 上传文件到hdfs
hdfs dfs -mkdir mnist / hdfs dfs -mkdir -p mnist
hdfs dfs -rm /user/${USER}/mnist/mnist.zip
hdfs dfs -put ${HOME}/mnist/mnist.zip /user/${USER}/mnist/mnist.zip
注: hdfs dfs 类似于 hadoop fs
# hadoop fs -mkdir mnist
# hadoop fs -rm ${USER}/mnist/mnist.zip
# hadoop fs -put ${HOME}/mnist/mnist.zip(如果报错使用下面的那句)
# hadoop fs -mkdir -p ${HOME}/mnist/mnist.zip
# step
3
将图像文件(images)和标签(labels)转换为CSV文件
# save images and labels as CSV files
hdfs dfs -rm -r ${USER}/mnist/csv
cd ~
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--queue ${QUEUE} \
--num-executors 4 \
--executor-memory 4G \
--archives hdfs:///user/${USER}/Python.zip#Python,hdfs:///user/${USER}/mnist/mnist.zip#mnist \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda-7.5/lib64" \
--driver-library-path="/usr/local/cuda-7.5/lib64" \
TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output mnist/csv \
--format csv
# cpu 模式
cd ~
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--queue ${QUEUE} \
--num-executors 2 \
--executor-memory 1G \
--archives hdfs:///user/${USER}/Python.zip#Python,hdfs:///user/${USER}/mnist/mnist.zip#mnist \
TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output mnist/csv \
--format csv
# save images and labels as
TFRecords(转成Tfrecode数据)
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--queue ${QUEUE} \
--num-executors 4 \
--executor-memory 4G \
--archives hdfs:///user/${USER}/Python.zip#Python,mnist/mnist.zip#mnist \
--jars hdfs:///user/${USER}/tensorflow-hadoop-1.0-SNAPSHOT.jar \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda-7.5/lib64" \
--driver-library-path="/usr/local/cuda-7.5/lib64" \
TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output mnist/tfr \
--format tfr
Run distributed MNIST training (using feed_dict)
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--queue ${QUEUE} \
--num-executors 2 \
--executor-memory 1G \
--py-files TensorFlowOnSpark/tfspark.zip,TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--archives hdfs:///user/${USER}/Python.zip#Python \
TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \
--images mnist/csv/train/images \
--labels mnist/csv/train/labels \
--mode train \
--model mnist_model