1 正则表达式的介绍
正则表达式使用单个字符串来描述,匹配一系列符合某个句法规则的字符串
对字符串的检索匹配和处理
2 python 正则表达式
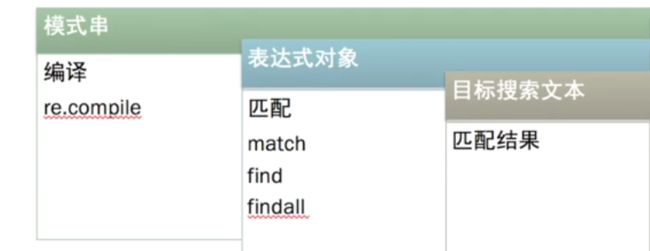
python通过re模块提供对正则表达式的支持
- 先将正则表达式的字符串形式编译为Pattern实例
- 使用Pattern实例处理文本并获得匹配结果
- 使用实例获得信息,进行其他操作
dd.PNG
字符:
| 一般字符 | 自身匹配 | abc | abc |
|---|---|---|---|
| . | 匹配任意换行符"\n"以外的字符。 在DOALL模式下也能匹配换行符 |
a.c | abc |
| \ | 转义字符 | a\.c a\\c |
a.c a\c |
| [...] | 字符集。可以是[abc]或[a-c]或[^abc]表示不是abc的其他字符 | a[bcd]e | abe ace ade |
预定义字符集(可以写在[...]中):
| 一般字符 | 自身匹配 | abc | abc |
|---|---|---|---|
| \d | 数字:[0-9] | a\dc | a1c |
| \D | 非数字:[^\d] | a\Dc | abc |
| \s | 非空字符:[<空格>\t\r\f\v] | a\sc | a c |
| \S | 非空白字符:[^\S] | a\Sc | abc |
| \w | 单词字符:[A-Za-z0-9] | a\wc | abc |
| \W | 非单词字符:[^\w] | a\Wc | a c |
数量词(用在字符或(......)之后):
| 一般字符 | 自身匹配 | abc | abc |
|---|---|---|---|
| * | 匹配前一个字符0次或无限次 | abc* | ab abccc |
| + | 匹配前一个字符1次或无限次 | abc+ | abc abccc |
| ? | 匹配前一个字符0次或一次 | ab? | ab abc |
| {m} | 匹配前一个字符m次 | ab{2}c | abbc |
| {m,n} | 匹配前一个字符m至n次 m和n可以省略 |
ab{1,2}c | abc abbc |
逻辑、分组:
| 一般字符 | 自身匹配 | abc | abc |
|---|---|---|---|
| | | 代表左右表达式任意匹配一个,它总是先尝试 匹配左边的表达式,一旦成功匹配则跳过右边的表达式 如果 | 没有包括在括号中,则它的范围是整个正则表达式 |
abc|def | abc def |
| (...) | 将括起来的表达式做为分组,从表达式左边开始每遇到, 一个分组的左边括号,编号+1。分组表达式做为一个整体, 可以后接数量词。表达式中 | 仅在该组中有效 |
(abc){2} a(123|456)c |
abcabc a456c |
iLmsux(编译选项指示):
| re.I | 忽略大小写 |
| re.L | 使用预定字符类\w \w \b \B \s \S取决当前区域设定 |
| re.M | 多行模式改变^和$的行为 |
| re.S | .任意匹配模式 |
| re.U | 使用预定义类\w \W \B \s \S \d \D 取决Unicode定义的字符属性 |
| re.X | 详细模式,可以多行,忽略空白字符,并且可以加入注释 |
3 贪婪模式和非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里的数量词默认是贪婪的,意思是总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。
例如:
正则表达式"abc"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪方法"ab?",将找到"a"。