并发编程 01—— ThreadLocal
并发编程 02—— ConcurrentHashMap
并发编程 03—— 阻塞队列和生产者-消费者模式
并发编程 04—— 闭锁CountDownLatch 与 栅栏CyclicBarrier
并发编程 05—— Callable和Future
并发编程 06—— CompletionService : Executor 和 BlockingQueue
并发编程 07—— 任务取消
并发编程 08—— 任务取消 之 中断
并发编程 09—— 任务取消 之 停止基于线程的服务
并发编程 10—— 任务取消 之 关闭 ExecutorService
并发编程 11—— 任务取消 之 “毒丸”对象
并发编程 12—— 任务取消与关闭 之 shutdownNow 的局限性
并发编程 13—— 线程池的使用 之 配置ThreadPoolExecutor 和 饱和策略
并发编程 14—— 线程池 之 整体架构
并发编程 15—— 线程池 之 原理一
并发编程 16—— 线程池 之 原理二
并发编程 17—— Lock
并发编程 18—— 使用内置条件队列实现简单的有界缓存
并发编程 19—— 显式的Conditon 对象
并发编程 20—— AbstractQueuedSynchronizer 深入分析
并发编程 21—— 原子变量和非阻塞同步机制
第1 部分 ThreadPoolExecutor简介
ThreadPoolExecutor是线程池类。对于线程池,可以通俗的将它理解为"存放一定数量线程的一个线程集合。线程池允许若个线程同时允许,允许同时运行的线程数量就是线程池的容量;当添加的到线程池中的线程超过它的容量时,会有一部分线程阻塞等待。线程池会通过相应的调度策略和拒绝策略,对添加到线程池中的线程进行管理。"
第2 部分 ThreadPoolExecutor数据结构
ThreadPoolExecutor的数据结构如下图所示:

各个数据在ThreadPoolExecutor.java中的定义如下:
// 阻塞队列。 private final BlockingQueueworkQueue; // 互斥锁 private final ReentrantLock mainLock = new ReentrantLock(); // 线程集合。一个Worker对应一个线程。 private final HashSet workers = new HashSet (); // “终止条件”,与“mainLock”绑定。 private final Condition termination = mainLock.newCondition(); // 线程池中线程数量曾经达到过的最大值。 private int largestPoolSize; // 已完成任务数量 private long completedTaskCount; // ThreadFactory对象,用于创建线程。 private volatile ThreadFactory threadFactory; // 拒绝策略的处理句柄。 private volatile RejectedExecutionHandler handler; // 保持线程存活时间。 private volatile long keepAliveTime; private volatile boolean allowCoreThreadTimeOut; // 核心池大小 private volatile int corePoolSize; // 最大池大小 private volatile int maximumPoolSize;
1. workers
workers是HashSet
wokers的作用是,线程池通过它实现了"允许多个线程同时运行"。
2. workQueue
workQueue是BlockingQueue类型,即它是一个阻塞队列。当线程池中的线程数超过它的容量的时候,线程会进入阻塞队列进行阻塞等待。
通过workQueue,线程池实现了阻塞功能。
3. mainLock
mainLock是互斥锁,通过mainLock实现了对线程池的互斥访问。
4. corePoolSize和maximumPoolSize
corePoolSize是"核心池大小",maximumPoolSize是"最大池大小"。它们的作用是调整"线程池中实际运行的线程的数量"。
例如,当新任务提交给线程池时(通过execute方法)。
-- 如果此时,线程池中运行的线程数量< corePoolSize,则创建新线程来处理请求。
-- 如果此时,线程池中运行的线程数量> corePoolSize,但是却< maximumPoolSize;则仅当阻塞队列满时才创建新线程。
如果设置的 corePoolSize 和 maximumPoolSize 相同,则创建了固定大小的线程池。如果将 maximumPoolSize 设置为基本的无界值(如 Integer.MAX_VALUE),则允许池适应任意数量的并发任务。在大多数情况下,核心池大小和最大池大小的值是在创建线程池设置的;但是,也可以使用 setCorePoolSize(int) 和 setMaximumPoolSize(int) 进行动态更改。
5. poolSize
poolSize是当前线程池的实际大小,即线程池中任务的数量。
6. allowCoreThreadTimeOut和keepAliveTime
allowCoreThreadTimeOut表示是否允许"线程在空闲状态时,仍然能够存活";而keepAliveTime是当线程池处于空闲状态的时候,超过keepAliveTime时间之后,空闲的线程会被终止。
7. threadFactory
threadFactory是ThreadFactory对象。它是一个线程工厂类,"线程池通过ThreadFactory创建线程"。
8. handler
handler是RejectedExecutionHandler类型。它是"线程池拒绝策略"的句柄,也就是说"当某任务添加到线程池中,而线程池拒绝该任务时,线程池会通过handler进行相应的处理"。
综上所说,线程池通过workers来管理"线程集合",每个线程在启动后,会执行线程池中的任务;当一个任务执行完后,它会从线程池的阻塞队列中取出任务来继续运行。阻塞队列是管理线程池任务的队列,当添加到线程池中的任务超过线程池的容量时,该任务就会进入阻塞队列进行等待。
第3 部分 线程池调度
线程池的主要工作流程如下图:
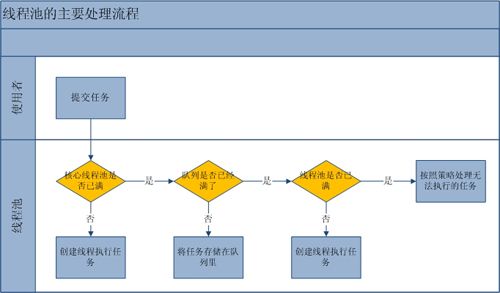
从上图我们可以看出,当提交一个新任务到线程池时,线程池的处理流程如下:
- 首先线程池判断基本线程池是否已满?没满,创建一个工作线程来执行任务。满了,则进入下个流程。
- 其次线程池判断工作队列是否已满?没满,则将新提交的任务存储在工作队列里。满了,则进入下个流程。
- 最后线程池判断整个线程池是否已满?没满,则创建一个新的工作线程来执行任务,满了,则交给饱和策略来处理这个任务。
图-01:

图-02:

说明:
在"图-01"中,线程池中有N个任务。"任务1", "任务2", "任务3"这3个任务在执行,而"任务4"到"任务N"在阻塞队列中等待。正在执行的任务,在workers集合中,workers集合包含3个Worker,每一个Worker对应一个Thread线程,Thread线程每次处理一个任务。
当workers集合中处理完某一个任务之后,会从阻塞队列中取出一个任务来继续执行,如图-02所示。图-02表示"任务1"处理完毕之后,线程池将"任务4"从阻塞队列中取出,放到workers中进行处理。