任务背景:
爬取水木社区某位贴主在所有发帖版面的帖子,分析随时间变化,贴主关注话题的变化。
主要步骤:
1.爬取帖子
这部分的实现源码存于“水木爬虫”文件夹中,运行环境为python3。
1)获取发帖版面:首先是spiderman_007.py,在代码中可设置待爬的贴主id。以贴主VChart为例,运行可得到该贴主发帖的版面及该版面的页数,记录在文件中“VChart.txt”中,
关键代码:


1 # 查找发贴版面并记录版面信息 2 while page_num < url[topical]: 3 content = get_url_content(now_url) 4 page_num += 1 5 page_str = str(page_num) 6 now_url = base_url + page_str # 构造爬虫的网页链接 7 soup = BeautifulSoup(content, 'html.parser') # 用BeautifulSoup提取网页中的文本内容 8 i = 0 9 name = 'VChart' 10 while i < 20: 11 # 查找标签获取贴主id 12 new_name = soup.find_all("li")[i].next_element.next_sibling.next_element.next_element.next_element 13 14 # 若查找到一条记录就记录信息并跳出循环进行下一版面的查找 15 if new_name == name: 16 f.write("\'" + topical + "\'" + ": " + str(url[topical]) + ", ") 17 i = 21 18 page_num = url[topical] + 1 19 elif new_name is None: 20 i = 21 21 i += 1
部分截图如下:

2)爬取帖子:根据Vchart.txt中的信息,运行spiderman.py可得到该贴主截至目前发布的帖子,记录在文件“VChart_texts.txt”中。
关键代码:
1 # 爬取每个版面的贴主的帖子并写入文件 2 now_url = base_url + page_str # 构造爬虫网页链接 3 soup = BeautifulSoup(content, 'html.parser') # 使用BeautifulSoup提取网页中的文本信息 4 i = 0 5 name = 'VChart' 6 while i < 20: 7 # 获取每一页所有的贴主id 8 new_name = soup.find_all("li")[i].next_element.next_sibling.next_element.next_element.next_element 9 10 if new_name == name: 11 new_url = base_url_+soup.find_all("li")[i].next_element.next_element.get('href') 12 f.write(new_url) 13 f.write("\n") 14 15 content_ = get_url_content(new_url) 16 soup1 = BeautifulSoup(content_, 'html.parser') 17 s = soup1.select(".sp") 18 f.write(s[2].previous_sibling()[0].get_text()) 19 l = len(s) 20 j = 2 21 while j < l-2: 22 s1 = s[j].get_text() 23 j += 1 24 f.write(s1) 25 time.sleep(1) 26 i += 1
部分截图如下:

2.对帖子进行排序、分词、聚类
1)排序:对帖子按时间进行排序,运行sort_data.py可得VCharttexts_sorted.txt,
关键代码:
1 # 根据一段帖子文本中的时间信息排序,返回一个list 2 def list_sort(list1): 3 pattern = re.compile("[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}") 4 5 print(list1) 6 list2 = re.findall(pattern, str(list1)) 7 list3 = list(zip(list2, list1)) 8 list3 = sorted(list3, key=lambda item: item[0]) 9 list4 = [] 10 for temp in list3: 11 list4.append(temp[1]) 12 return list4
部分截图如下:
2)分词:将帖子按一定时间段分为不同文件,以每一年为一段为例,该贴主的帖子发帖时间为2004-2018年,共分为15个文件存于文档->VChart->time中,运行fenci_time.py可以得到每一段时间文档的分词及词频结果,存于time文件下。
关键代码:
1 # 分词写并写入文件 2 def segmented(file, text): 3 ans = re.sub('[^\w\u4e00-\u9fff]+', "", text) # 正则表达式过滤出汉字 4 ans = "".join(ans.split()) 5 # seg_list = jieba.cut(ans) # 精确模式(默认是精确模式) 6 # print("[精确模式]: ", "/ ".join(seg_list)) 7 words = jieba.cut(ans, cut_all=False) 8 word_freq = {} 9 stopwords = stopwordslist('ting.txt') # 去除停用词 10 for word in words: 11 if word in word_freq: 12 word_freq[word] += 1 13 else: 14 word_freq[word] = 1 15 16 freq_word = [] 17 for word, freq in word_freq.items(): 18 freq_word.append((word, freq)) 19 freq_word.sort(key=lambda x: x[1], reverse=True)
3)分词:运行fenlegeci.py可以得到对所有贴子进行分词、排序并统计词频的文件“fencihou.txt”。
4)取出无用词:将fencihou.txt文件中的内容复制到Excel中,需要手动删去一些无意义和体现不出贴主发贴话题的词,例如“中”“提到”“大作”“水木”等。
5)计算百分比:运行cout_frequency&percent.py可以根据5)、6)中得到的结果得到每个词在每个时间段的词频百分比,生成文件“统计.xls”。词频百分比=该词的词频÷该时间段所有词的词频总数×100%。
关键代码:
1 # Excel文件读写操作 2 readbook = xlrd.open_workbook(r'统计_all.xlsx') 3 sheet = readbook.sheet_by_name('Sheet1') 4 nrows = sheet.nrows 5 f = xlwt.Workbook(encoding='utf-8') 6 table = f.add_sheet('data') 7 8 table.write(i, j, 0) 9 f.save("统计.xls")
部分截图如下:
6)生成.csv文件:在A1处填上“word”,将文件另存为“VChart时间词频百分比.csv”,即存为.csv格式的文件,注意编码方式要选择“UTF-8”。该文件可以被用于在weka软件中进行聚类。
7)聚类:打开weka->Explorer->Open file,选则打开6)中的csv文件。
选则Cluster,点击Choose选则SimpleKmeans算法进行聚类。
点击下图红框处可以设置KMeans相关参数。选则“Classes to clusters evaluation”并按“word”聚类,点击“Start”即可运行。
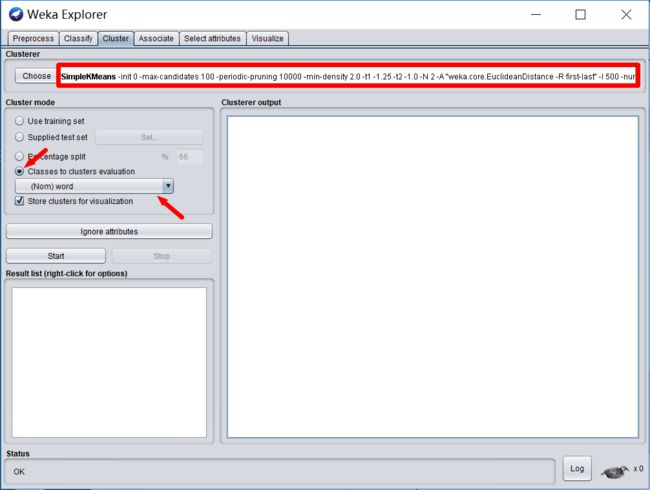
运行结束后,左下角会有运行记录,右键选则Save result buffer可以得到结果文件。
为了方便查看内容,推荐使用Notepad++打开文件。
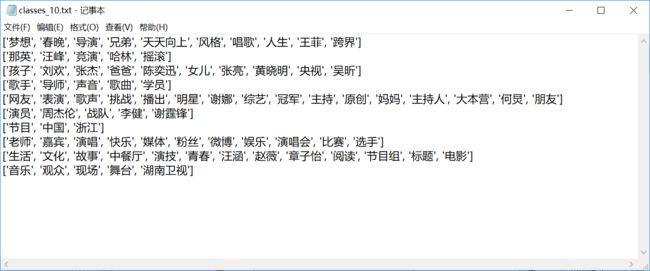
8)获取聚类结果:weka的运行结果文件中有很多用不到的信息,运行clustering文件夹下的get_class_words.py文件可以得到每一类的词的信息,形式如下:
3.展示
对每一类词随时间变化的展示,主要参考了https://github.com/TangliziGit/ColumnsAnimation.git中的项目。
1)统计每一类词的词频百分比在各个时间段内的平均值,用于展示。
2)使用ColumnsAnimation->data中的getdata.py可以得到自己的展示数据的data.json文件。
3)在data.json文件开头添加“var TotalData=”并另存为“data.js”放在ColumnsAnimation目录下,打开animation.html即可看到展示效果。
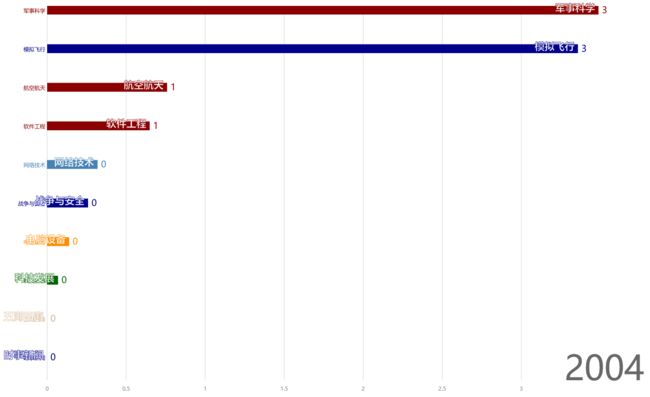
例如,在2004年,各个话题的词频百分比如下:
在2005年,各个话题词频百分比变化为:
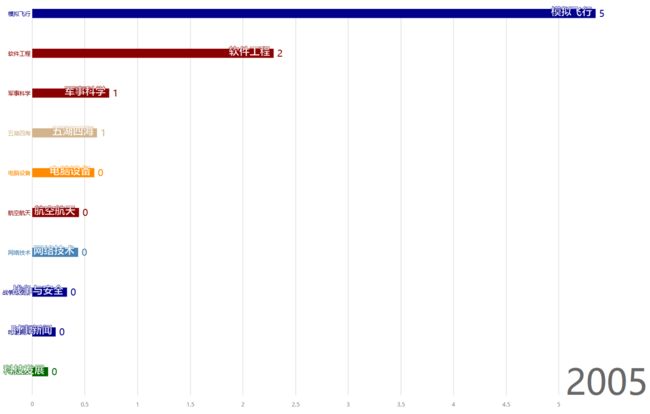
这两年里,贴主的最关注的话题由“军事科学”转向“模拟飞行”。对军事的爱好丝毫不减,只是转向了虚拟空间。同时,增加了对软件工程的关注度,与软件工程相关的电脑设备等话题关注度也有所提高,并且一如既地关注网络技术。
各话题词频变化统计展示至2018年,项目中的11-24.mp4为效果录屏文件,录屏效果如下:

由图可看出从2004-2018年,随时间变化,通过聚类得到的贴主关注的10个话题的变化。
本项目地址:https://git.coding.net/Ruidxr/ShuiMu.git