OpenMP基本概念
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。
OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:

OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
- parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for:parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
private:指定一个或多个变量在每个线程中都有它自己的私有副本;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
copyin:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
default:用来指定并行域内的变量的使用方式,缺省是shared。
API函数
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP API函数以及说明:
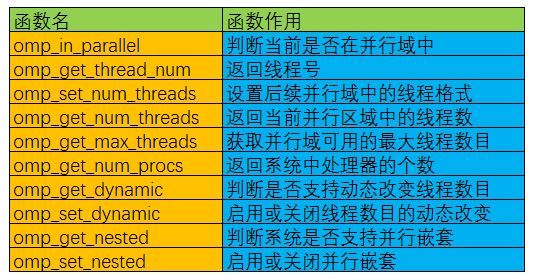
环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量:
- OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
简单示例之parallel使用
parallel制导指令用来创建并行域,后边要跟一个大括号将要并行执行的代码放在一起:
#include
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel
{
cout << "Test" << endl;
}
system("pause");
} 执行以上程序有如下输出:
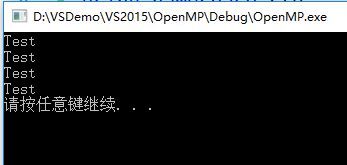
程序打印出了4个“Test”,说明parallel后的语句被4个线程分别执行了一次,4个是程序默认的线程数,还可以通过子句num_threads显式控制创建的线程数:
#include
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel num_threads(6)
{
cout << "Test" << endl;
}
system("pause");
} 编译运行有如下输出:
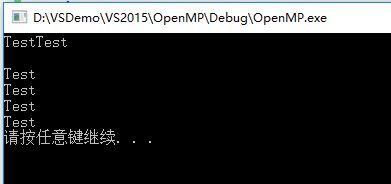
程序中显式定义了6个线程,所以parallel后的语句块分别被执行了6次。第二行的空行是由于每个线程都是独立运行的,在其中一个线程输出字符“Test”之后还没有来得及换行时,另一个线程直接输出了字符“Test”。
简单示例之parallel for使用
使用parallel制导指令只是产生了并行域,让多个线程分别执行相同的任务,并没有实际的使用价值。parallel for用于生成一个并行域,并将计算任务在多个线程之间分配,从而加快计算运行的速度。可以让系统默认分配线程个数,也可以使用num_threads子句指定线程个数。
#include
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel for num_threads(6)
for (int i = 0; i < 12; i++)
{
printf("OpenMP Test, 线程编号为: %d\n", omp_get_thread_num());
}
system("pause");
} 运行输出:
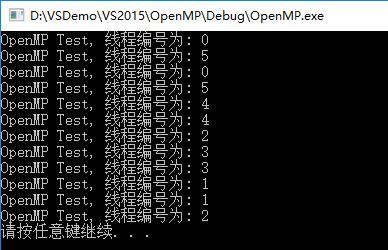
上边程序指定了6个线程,迭代量为12,从输出可以看到每个线程都分到了12/6=2次的迭代量。
OpenMP效率提升以及不同线程数效率对比
#include
#include"omp.h"
using namespace std;
void test()
{
for (int i = 0; i < 80000; i++)
{
}
}
void main()
{
float startTime = omp_get_wtime();
//指定2个线程
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("指定 2 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定4个线程
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 4 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定8个线程
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 8 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定12个线程
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 12 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP多线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
system("pause");
} 以上程序分别指定了2、4、8、12个线程和不使用OpenMP优化来执行一段垃圾程序,输出如下:
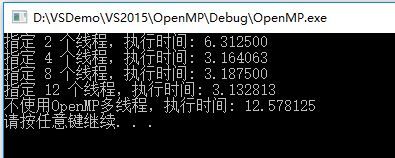
可见,使用OpenMP优化后的程序执行时间是原来的1/4左右,并且并不是线程数使用越多效率越高,一般线程数达到4~8个的时候,不能简单通过提高线程数来进一步提高效率。