激光SLAM与视觉SLAM的现状与趋势
同时定位与地图构建(Simultaneous Localization And Mapping,简称SLAM),通常是指在机器人或者其他载体上,通过对各种传感器数据进行采集和计算,生成对其自身位置姿态的定位和场景地图信息的系统。SLAM技术对于机器人或其他智能体的行动和交互能力至为关键,因为它代表了这种能力的基础:知道自己在哪里,知道周围环境如何,进而知道下一步该如何自主行动。它在自动驾驶、服务型机器人、无人机、AR/VR等领域有着广泛的应用,可以说凡是拥有一定行动能力的智能体都拥有某种形式的SLAM系统。
一般来讲,SLAM系统通常都包含多种传感器和多种功能模块。而按照核心的功能模块来区分,目前常见的机器人SLAM系统一般具有两种形式:基于激光雷达的SLAM(激光SLAM)和基于视觉的SLAM(Visual SLAM或VSLAM)。
激光SLAM简介
激光SLAM脱胎于早期的基于测距的定位方法(如超声和红外单点测距)。激光雷达(Light Detection And Ranging)的出现和普及使得测量更快更准,信息更丰富。激光雷达采集到的物体信息呈现出一系列分散的、具有准确角度和距离信息的点,被称为点云。通常,激光SLAM系统通过对不同时刻两片点云的匹配与比对,计算激光雷达相对运动的距离和姿态的改变,也就完成了对机器人自身的定位。
激光雷达距离测量比较准确,误差模型简单,在强光直射以外的环境中运行稳定,点云的处理也比较容易。同时,点云信息本身包含直接的几何关系,使得机器人的路径规划和导航变得直观。激光SLAM理论研究也相对成熟,落地产品更丰富。
 图1,激光SLAM的地图构建(谷歌Cartographer[1])
图1,激光SLAM的地图构建(谷歌Cartographer[1])
VSLAM简介
眼睛是人类获取外界信息的主要来源。视觉SLAM也具有类似特点,它可以从环境中获取海量的、富于冗余的纹理信息,拥有超强的场景辨识能力。早期的视觉SLAM基于滤波理论,其非线性的误差模型和巨大的计算量成为了它实用落地的障碍。近年来,随着具有稀疏性的非线性优化理论(Bundle Adjustment)以及相机技术、计算性能的进步,实时运行的视觉SLAM已经不再是梦想。
通常,一个VSLAM系统由前端和后端组成(图2)。前端负责通过视觉增量式计算机器人的位姿,速度较快。后端,主要负责两个功能:
-
一是在出现回环(即判定机器人回到了之前访问过的地点附近)时,发现回环并修正两次访问中间各处的位置与姿态;
-
二是当前端跟踪丢失时,根据视觉的纹理信息对机器人进行重新定位。简单说,前端负责快速定位,后端负责较慢的地图维护。
VSLAM的优点是它所利用的丰富纹理信息。例如两块尺寸相同内容却不同的广告牌,基于点云的激光SLAM算法无法区别他们,而视觉则可以轻易分辨。这带来了重定位、场景分类上无可比拟的巨大优势。同时,视觉信息可以较为容易的被用来跟踪和预测场景中的动态目标,如行人、车辆等,对于在复杂动态场景中的应用这是至关重要的。第三,视觉的投影模型理论上可以让无限远处的物体都进入视觉画面中,在合理的配置下(如长基线的双目相机)可以进行很大尺度场景的定位与地图构建。
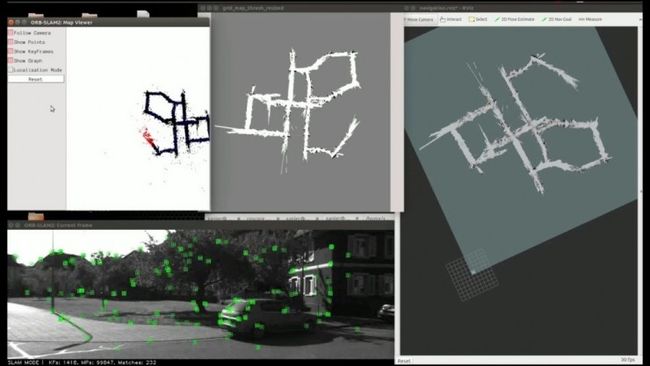 图2,视觉SLAM的前端定位与后端地图维护(ORB-SLAM2[2])
图2,视觉SLAM的前端定位与后端地图维护(ORB-SLAM2[2])
接下来我们将在细分项目上比较激光SLAM和VSLAM。
应用场景
在应用场景上,激光SLAM依据所使用的激光雷达的档次基本被分为泾渭分明的室内应用和室外应用,而VSLAM在室内外都有丰富的应用环境。VSLAM的主要挑战是光照变化,例如在室外正午和夜间的跨时间定位与地图构建,其工作稳定性不如高端室外多线激光雷达。近年来,光照模型修正和基于深度学习的高鲁棒性特征点被广泛应用于视觉SLAM的研究中,体现出良好的效果,应当说VSLAM随着这些技术的进步将会在光照变化的环境中拥有更稳定的表现。
影响稳定工作的因素
激光SLAM不擅长动态环境中的定位,比如有大量人员遮挡其测量的环境,也不擅长在类似的几何环境中工作,比如在一个又长又直、两侧是墙壁的环境。由于重定位能力较差,激光SLAM在追踪丢失后很难重新回到工作状态。而视觉SLAM在无纹理环境(比如面对整洁的白墙面),以及光照特别弱的环境中,表现较差。
定位和地图构建精度
在静态且简单的环境中,激光SLAM定位总体来讲优于视觉SLAM;但在较大尺度且动态的环境中,视觉SLAM因为其具有的纹理信息,表现出更好的效果。在地图构建上,激光SLAM的特点是单点和单次测量都更精确,但地图信息量更小;视觉SLAM特别是通过三角测距计算距离的方法,在单点和单次测量精度上表现总体来讲不如激光雷达,但可以通过重复观测反复提高精度,同时拥有更丰富的地图信息。
累计误差问题
激光SLAM总体来讲较为缺乏回环检测的能力,累计误差的消除较为困难。而视觉SLAM使用了大量冗余的纹理信息,回环检测较为容易,即使在前端累计一定误差的情况下仍能通过回环修正将误差消除。
传感器成本
激光雷达事实上有许多档次,成本都高于视觉传感器。最昂贵如Velodyne的室外远距离多线雷达动辄数十万元人民币,而室外使用的高端中远距离平面雷达如SICK和Hokuyo大约在数万元人民币的等级。室内应用较广的中低端近距离平面激光雷达也需要千元级—,其价格相当于比较高端的工业级摄像头和感光芯片。激光雷达量产后成本可能会大幅下降,但能否降到同档次摄像头的水平仍有一个大大的问号。
传感器安装和稳定性
目前常见的激光雷达都是旋转扫描式的,内部长期处于旋转中的机械结构会给系统带来不稳定性,在颠簸震动时影响尤其明显。而摄像头不包含运动机械结构,对空间要求更低,可以在更多的场景下安装使用(图3)。不过,固态激光雷达的逐步成熟可能会为激光SLAM扳回这项劣势。

图3 激光雷达和视觉系统的安装应用。谷歌无人车上的多线激光雷达

DJI精灵4上的视觉系统。
算法难度
激光SLAM由于其研究的成熟以及误差模型的相对简单,在算法上门槛更低,部分开源算法甚至已经被纳入了ROS系统成为了标配。而反观视觉SLAM,首先图像处理本身就是一门很深的学问,而基于非线性优化的地图构建上也是非常复杂和耗时的计算问题。现在已经有许多优秀的开源算法(如ORB-SLAM[2]、LSD-SLAM[3]),但在实际环境中优化和改进现有的视觉SLAM框架,比如加入光照模型、使用深度学习提取的特征点、以及使用单双目及多目融合视角等技术,将是视觉SLAM进一步提升性能和实用性的必由之路。这些技术的算法门槛也远远高于激光SLAM。
计算需求
毫无疑问,激光SLAM的计算性能需求大大低于视觉SLAM。主流的激光SLAM可以在普通ARM CPU上实时运行,而视觉SLAM基本都需要较为强劲的准桌面级CPU或者GPU支持。但业界也看到了这其中蕴藏的巨大机会,为视觉处理定制的ASICS市场已经蠢蠢欲动。一个很好的例子是Intel旗下的Movidius,他们设计了一种特殊的架构来进行图像、视频与深度神经网络的处理,在瓦级的超低功耗下达到桌面级GPU才拥有的吞吐量。DJI的精灵4系列产品就是使用这类专用芯片,实现了高速低功耗的视觉计算,为无人机避障和近地面场景导航提供根据。
多机协作
视觉主要是被动探测,不存在多机器人干扰问题。而激光雷达主动发射,在较多机器人时可能产生干扰。尤其是固态激光雷达的大量使用,可能使得场景中充满了信号污染,从而影响激光SLAM的效果。
未来趋势
激光SLAM和视觉SLAM各擅胜场,单独使用都有其局限性,而融合使用则可能具有巨大的取长补短的潜力。例如,视觉在纹理丰富的动态环境中稳定工作,并能为激光SLAM提供非常准确的点云匹配,而激光雷达提供的精确方向和距离信息在正确匹配的点云上会发挥更大的威力(图4)。而在光照严重不足或纹理缺失的环境中,激光SLAM的定位工作使得视觉可以借助不多的信息进行场景记录。
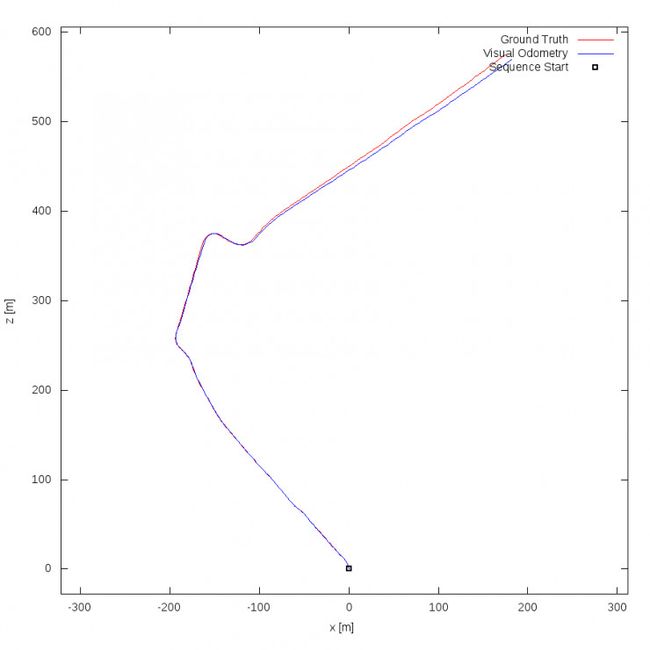
图4,KITTI数据集视觉里程计。ORB-SLAM[2],双目视觉。
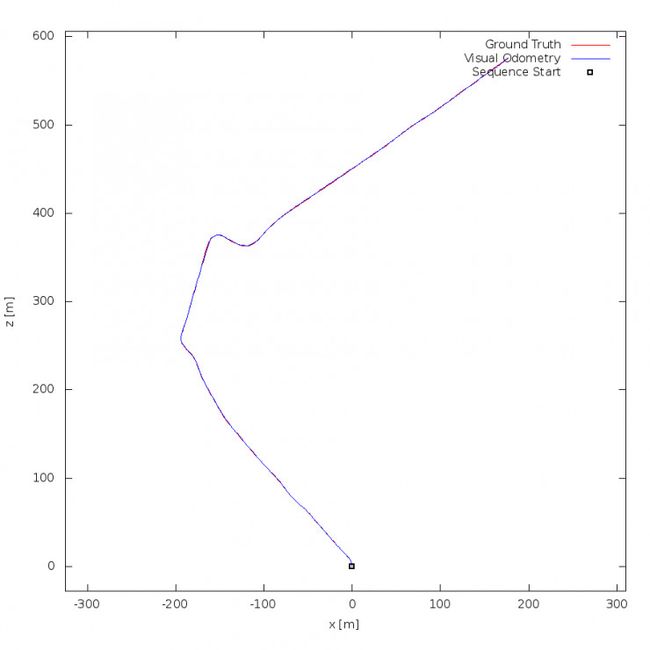
V-LOAM[4],视觉引导激光修正。
现实中的激光与视觉SLAM系统几乎都会配备惯性元件、轮机里程计、卫星定位系统、室内基站定位系统等辅助定位工具,而近年来SLAM系统与其他传感器的融合成为了一大热点。不同于以往基于卡尔曼滤波的松耦合融合方法,现在学界的热点是基于非线性优化的紧耦合融合。例如与IMU的融合和实时相互标定,使得激光或视觉模块在机动 (猛烈加减速和旋转) 时可以保持一定的定位精度,防止跟踪丢失,极大的提高定位与地图构建的稳定性。
激光点云信息本身也仍有潜力可挖。在高端的远距离多线激光雷达上,返回的点云除了包含方向和距离信息,还可以加入目标点的反射率信息。当线数较多较密时,由反射率信息构成的数据可以视为一种纹理信息,因此可以在一定程度上享受视觉算法和纹理信息带来的重定位等方面的优势。这些信息一旦融入到高精度地图中,高精度地图就可以在点云\纹理两种形式间无缝切换,使得利用高精度地图的定位可以被只拥有廉价摄像头的自动驾驶汽车分享。这也是目前国外一些团队的研究方向([5])。
同时,视觉所依赖的投影模型,蕴含着非常丰富的“混搭”玩法。长、短基线的单双目结合,可以在保证大尺度定位水平的同时提高中近距离的障碍探测和地图构建精度;广角鱼眼和360度全向摄像头与标准单双目的结合,使得VSLAM的覆盖范围可以进一步提升,特别适合对场景按照距离的远近进行不同精度不同速度的定位。被动视觉与深度相机的结合,催生了RGB-D SLAM,而深度相机量程的逐步扩大,将给这种特殊VSLAM带来更大的应用空间。
VSLAM的另一个也许更宏大的扩展在AI端。端到端的深度学习所带来的图像特征,已经在识别和分类领域大大超越了人类手工选择的SIFT/SURF/ORB等特征。我们可以很安全的说,未来在低纹理、低光照等环境下,深度学习所训练出的提取、匹配和定位估算等方法,也一定会超越目前VSLAM领域最先进的手工方法。更不用说,图像本身所大量携带的信息,可以广泛用于场景理解、场景分类、物体识别、行为预测等重要方面。一个很可能的情况是,未来视觉处理系统将直接包含定位、地图构建、运动规划、场景理解以及交互等多个功能模块,更紧密的联合带来更加智能的机器人行动能力。
如果想深入了解SLAM技术的过去、现在和未来趋势,我们推荐文献[6]。
结语
SLAM技术将赋予为机器人和智能体前所未有的行动能力。作为当前SLAM框架的主要类型,激光SLAM与视觉SLAM必将在相互竞争和融合中发展,必将带来机器人技术和人工智能技术的真正革命,也将使得机器人从实验室和展示厅中走出来,真正服务和解放人类。
引用参考:
[1] Cartographer https://github.com/googlecartographer
[2] ORB-SLAM2 R. Mur-Artal and J. D. Tardos, “ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,” IEEE Transactions on Robotics (2017).
[3] LSD-SLAM J. Engel, J. Stuckler, and D. Cremers, “Large-scale direct SLAM with stereo cameras,” Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015
[4] V-LOAM J. Zhang and S. Singh, “Visual-lidar odometry and mapping: Low-drift, robust, and fast,” Robotics and Automation (ICRA), 2015 IEEE International Conference on. IEEE, 2015.
[5] G. Pascoe, W. Maddern, and P. Newman, “Direct visual localization and calibration for road vehicles in changing city environments,” Proceedings of the IEEE International Conference on Computer Vision Workshops, 2015.
[6] C. Cadena, et. al. “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,” IEEE Transactions on Robotics 32.6 (2016): 1309-1332.