一些概念
关系、元组、属性
在关系数据库理论中, 关系 (relation)对应于数据库技术的表 (table), 元组 (tuple)对应于行 (row), 属性 (attribute)对应于列 (column)
元组的 元 (arity)为属性数量,即列的数量,一元unitary,二元binary,三元ternary等
关系的 势 (cardinality)为关系中的元组数量,即行数
Projection operator 投影运算
即选取仅选取部分列的查询
Materialized view 物化视图
即被高速缓存的视图
RAID
Redundant Array of Independent Disks,廉价磁盘冗余阵列。利用拆分(striping)提高性能,使用冗余提高可靠性。参考RAID on wikipedia
RAID0
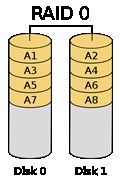
RAID0块级拆分,没有冗余。拆分的文件支持并发存取,但任何一块磁盘损坏将导致所有文件损坏
RAID1

RAID1仅做冗余,没有拆分。支持并发读取,提高了读取性能,写入时需要同时写入多块磁盘
RAID2
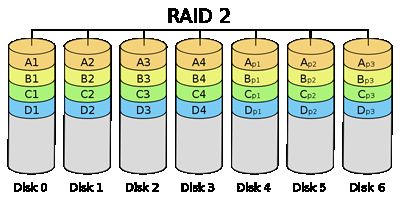
RAID2字节级拆分(文件相邻的字节均被拆分存储到不同磁盘中),有一块或多块奇偶校验盘(图中的Disk 4, 5, 6)用于容错
RAID3
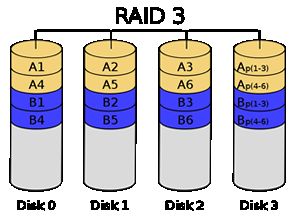
RAID3字节级拆分,有一块独立的奇偶校验盘(图中的Disk 3)
RAID4
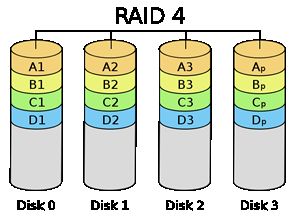
RAID4块级拆分,有一块独立的奇偶校验盘。任何一块磁盘损坏不会造成数据丢失,2块盘损坏时将丢失数据
RAID5
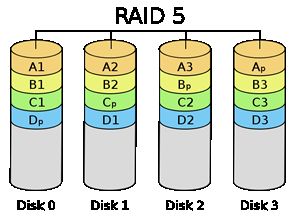
RAID5块级拆分,具备奇偶校验,但没有独立的奇偶盘,奇偶校验与文件数据一起被拆分在多个盘中。任何一块磁盘损坏不会造成数据丢失,2块盘损坏时将丢失数据
RAID6
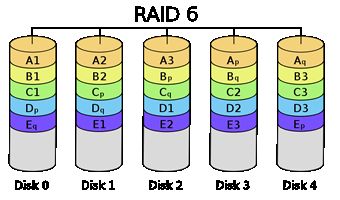
RAID6块级拆分,有2块奇偶盘,最多在2块磁盘损坏时不会造成数据丢失
存储
堆文件 heap file:记录无序,仅在末尾添加,删除记录时不释放空间,不适合查询
顺序文件 sorted file:按某些列的顺序存放,可运用二分查找等优化算法
填充因子 fill factor:每页预留空间供插入操作,预留空间满了以后使用溢出链overflow chain支持插入操作
索引
集成索引 integrated index:索引条目跟数据记录集成在一起
聚集索引 clustered index:对于有序索引(B+ tree等),如果索引条目与数据记录都是按照相同的search key排序的,则为聚集索引,集成索引是一种聚集索引;对于散列(hash)索引,如果散列索引条目就是数据记录则为聚集的,此时hash bucket本身就是数据文件的存储结构,数据文件就是hash bucket的序列
聚集索引通常又称为main index,非聚集索引又称为secondary index
稠密索引 dense idnex:索引条目与数据记录一一对应
稀疏索引 sparse index:索引条目与数据页一一对应(与数据记录为一对多关系)
ISAM: Indexed Sequential Access Method
ISAM结构示意图:
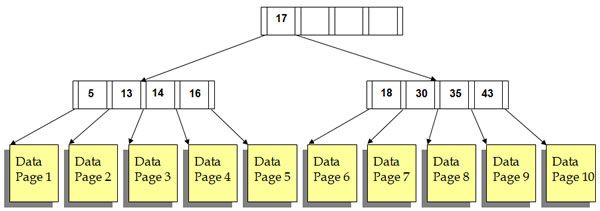
ISAM结构示意图非页节点称为分隔符级,一个分隔符节点示意图如下:

ISAM分隔符节点示意图其中Pn为指向下一级节点的指针,Kn为搜索码的值。Pi-1指向的K值
ISAM的分隔符级节点一旦创建便不再更改,因此ISAM被称为静态索引。叶子页中的条目被除时其空间不会释放,相关的分隔符级也不会更新,即可能出现分隔符级页中出现的某些search key在叶子节点上没有对应条目。插入时叶子页使用fill factor和overflow chain
ISAM对相对静态的表有效,动态表通常不用ISAM索引
B+ Tree
B+ tree结构示意图:
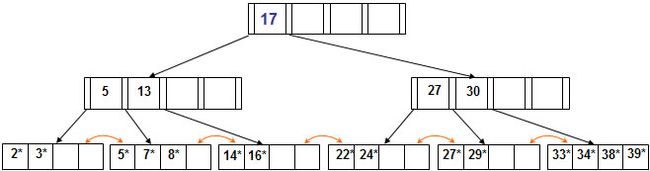
B+ tree结构示意图根节点到达任何一个叶子页的级数是一样的。叶子页添加了兄弟指针,方便range search,支持范围搜索、等值搜索、部分码搜索方式
叶子页至少包含(n-1)/2个值,最多包含n-1个值。维护B+ Tree结构(插入、删除操作等)算法复杂
节点与ISAM类似:

B+ tree节点示意图
Hash索引
只能等值搜索,这种情况下比B+ tree更有效
也需要使用overflow chain
有静态散列算法、动态散列算法(包括可扩展散列、线性散列)
Bit map 位图索引
位图索引一般用于低势属性(取值范围很小的属性)
为每一个取值建立一个位图向量,每一位对应于数据的某一行。例如有PERSON表SEX列,取值范围为(MALE, FEMALE),数据4000行,则将建立2个位图向量V(male)、V(female),每个向量有4000位。如果V(male)i=1则表示第i 行记录SEX列取值MALE
现在假如有这样一个查询:SEX='MALE' AND SMOKE='YES',如果这2个列都有位图索引,则可以用V(sex-male) & V(smoker-yes)这个运算(位AND运算)得到满足条件的行
位图索引存在空间浪费,但特定情况下效率很高。另外位图索引的维护成本比较高,因此不适合频繁插入、更新的表
查询优化器
Rule based optimizer:基于既定的规则优化查询计划
Cost-based optimizer:在RBO的基础上增加统计信息,结合评估成本与既定规则优化查询计划
事物
有关事务的部分内容可以参考 事物、锁、隔离等级
在数据库理论中检验事物正确性以完全串行化执行结果为基准,考虑并发处理后采用两阶段封锁协议(two-phase locking protocol, 2PL),访问资源(读、写)时先申请锁
考虑并发性能问题,锁分成不同的粒度,典型的为表级锁、页级锁、行级锁
为什么需要意向锁?
因为有不同粒度的锁存在,为了优化锁冲突的判断处理而设计出意向锁
比如事物t1更新了某条记录,对这条记录加了写锁。而事物t2需要读取这个表的所有记录,需要对表加读锁。事物控制器如何确定这2个事物的加锁请求是否冲突?
有了意向锁之后,事物t1在更新记录时,对这个表加意向排他锁IX(如果有页锁,则对数据记录所在页也加IX锁);事物t2申请这个表上的共享锁S时,就只需要检测表(以及页)上面已存在的锁是否与S锁冲突,而IX与S是冲突的,所以t2只有等待。这样避免了锁冲突判断时需要理解并处理加锁对象的类型以及之间的关系
意向锁类型
IS, Intention Shared, 意向共享锁:对行取读锁S时,则必须获取表的IS锁
IX, Intention Exclusive, 意向排他锁:要更新某一行,则必须先获取该表的IX锁
SIX, Shared Intention Exclusive, 共享意向排他锁:例如要更新某些行,但必须执行表扫描才能确定具体需要更新的行,则加SIX锁,它是共享锁与意向排他锁的结合
先写式日志 Write-ahead log
更新记录 update record:用于确保事物的原子性、持久性机制,事物终止(rollback)时可以根据更新记录回滚。更新日志中包含before image,即记录被更新之前的状态,因此可以用它来撤销更改。因此更新记录也被称为undo record
日志示意图:

数据库日志示意图 Ui:事物Ti的更新记录 update record
Bi:事物Ti的开始记录 begin record
Ci:事物Ti的开始记录 commit record
Ai:事物Ti的开始记录 abort record
CK:Check Point
1. 终止事物时,在日志中反向扫描处理到该事物的begin record就完成了
2. 系统崩溃时需要将当时所有活动事物全部回滚(系统崩溃时内存信息已经丢失,只能根据日志操作),所以用commit record、abort record标识那些已经结束了的事物
另外,除非反向扫描完整个日志文件,否则无法确定崩溃时哪些事物为活动事物,因此在日志中定期记录check point record,用来记录检查点时刻系统中所有活动的事物id。这样崩溃恢复时只需要反向扫描到任何一个check point record就有方法确定扫描的终止条件
更新数据时,先更新数据文件还是先写日志?
如果先更新数据文件,在日志文件还没有写入时发生崩溃,则这个数据可能无法恢复;如果先写日志,在数据未更新时发生崩溃,则恢复处理不会造成数据错误。因此叫做write-ahead log
除了before image外,日志可能还包括after image,即记录更新之后的状态,用于重做事物,因此也叫redo record。例如某时刻数据库损坏,则可以用之前的某个备份加上redo log恢复到崩溃之前的某个状态,将损失降到最低