基于小样本量的水下图像识别
摘要:由于海洋环境的不受限制,使得水下物体的识别成为一项具有挑战性的任务。在大数据集的背景下,深度学习方法已成功地应用于空中物体的图像识别。然而,我们发现深度神经网络(DNNs)容易在小样本数据集中发生过拟合现象。不幸的是,水下图像采集往往需要大量的人力和物力,这使得获取足够的样本图像来训练DNNs变得困难。此外,水下摄像机捕捉到的图像通常会因噪声而恶化。
这一篇文章中,我们将以活鱼识别为例,提出一种小样本环境下的水下图像识别框架。首先,利用一种改进的中值滤波器来抑制鱼的图像噪声。然后,使用世界上最大的图像识别数据库ImageNet中的图像对卷积神经网络模型进行预训练。最后,利用预处理后的鱼图像对训练后的神经网络进行微调,并对分类性能进行测试。实验结果表明,该方法具有识别鱼类的能力,为小样本环境下的识别任务提供了一种有效的方法。
一、引言
随着海洋观测的快速发展,水下物体识别在海军沿海防御任务以及渔业、水产养殖等海洋经济中发挥着越来越重要的作用。然而,由于水下环境的复杂性,水下图像具有边缘和细节退化、目标与背景对比度低、噪声污染等特点,使得图像识别成为一项非常具有挑战性的任务。传统的分类解决方案使用精心手工制作的低级特性。这些特性对于某些特定的数据和任务确实取得了很好的性能,但是有效的特性需要专门的知识,并且它们中的大多数在泛化能力上是有限的。
深度学习是模式识别领域的一个新的研究热点。它允许由多个处理层组成的模型学习具有多个抽象级别的数据表示。自21世纪初以来,卷积神经网络(ConvNets)在空中物体的图像识别中得到了成功的应用。遗憾的是,基于深度学习的水下图像识别研究还不够深入。其中一个原因可能是深度学习在图像分类中的成功在于使用了大量的训练数据,而水下目标图像的获取总是需要大量的人力和成本,这使得获取大量的样本图像变得困难。
本文的目的是在小样本量的情况下找到一种水下图像识别的方法。更具体地说,利用水下摄像机在公海捕捉到的一组鱼类图像,我们试图找到一个有效而简单的框架来解决水下活鱼识别问题。
二、背景信息
A.中值滤波
实验表明,脉冲噪声和高斯噪声通常会使摄像机捕捉到的图像质量下降。噪声的存在给图像处理带来困难,直接影响到图像的分割、特征提取、图像识别等。
中值滤波器能有效抑制脉冲噪声。中值滤波的标准算法一般采用滑动窗口获取图像局部像素的灰度值,然后用滑动窗口获取的中值替换原始图像中指定像素的值。该算法相对简单,易于硬件实现。然而,标准中值滤波器的性能受过滤窗口大小的影响很大。例如,一个小的滤波窗口可以更好的保护原始图像的细节信息,但是噪声滤波的能力会受到限制;大的滤波窗口可以增强对噪声的抑制,但会削弱原始图像的细节。上面是针对灰度图像而言,对彩色图像(多通道)同理可得。
B.用于图像识别的卷积神经网络
卷积神经网络是一种有效的分类方法,在物体识别中得到了广泛的应用。ConvNets的典型架构是由卷积层、池化层和全连接层等简单模块组成的多层堆栈。从原始输入开始,每个模块将一个级别的表示转换为一个更高、更抽象的级别。对于识别任务,更高级别的表示会放大输入的某些方面,这些方面对于识别和抑制无关的变化非常重要。
ConvNets对图像的性质(即统计数据的平稳性和像素依赖性的局部性:stationarity of statistics and locality of pixel dependencies)做出了强有力的、大多数是正确的假设。因此,与具有类似尺寸层的标准前馈神经网络相比,ConvNets的连接和参数要少得多,因此更易于训练,而理论上最好的性能可能只是稍微差一些。此外,卷积神经网络的容量可以通过改变其深度和宽度来控制。
ConvNets的一个典型模型是AlexNet,如图1所示。在2012年ImageNet大型视觉识别挑战赛(ILSVRC)中,Alex和他的团队获得了15.3%的前五名测试错误率,而第二名的测试错误率为26.2%。结果表明,一个大而深卷积神经网络能够利用纯监督学习方法在大数据集上实现高精度。
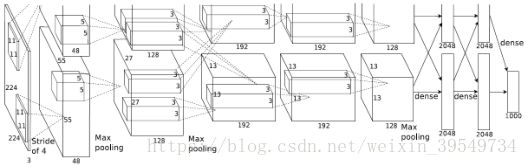
图1 AlexNet的总体架构。net包含8个权重层,前5个是卷积层,剩下的3个是全连接层。最后一个全连接层的输出被输入到Softmax分类器中,该分类器生成1000个类标签的分布。
三、提出框架
A.改进的中值滤波器
与处理图像所有像素的标准中值滤波器不同,我们改进的中值滤波器只处理被脉冲噪声污染的像素。算法分为两个主要步骤:
(1)第一步:检测被脉冲噪声污染的图像像素。根据先验知识,噪声像素的值与周围的无噪声像素值相差很大。
(a)脉冲噪声主要是将像素值更改为0或255,所以我们只关心那些值为0或255的像素,其他的都属于无噪声像素。
(b)用5×5标准中值滤波器来处理整个原始图像,得到一个粗糙的图像。分别从原始图像中减去处理后的图像的像素值,取结果的平均值作为阈值,确定我们感兴趣的像素是否为噪声像素。具体来说,如果减法结果的像素值大于阈值,则该像素将被划分为噪声像素,反之亦然。
(2)第二步:处理噪声像素。被脉冲噪声干扰的像素将被5×5标准中值滤波器处理。
为了定量描述去噪效果,将采用一种经典的方法。用标准公式计算了RGB图像的峰值信噪比(PSNR,该值越大,去噪效果越好):
x:二维空间坐标,属于图像域X⊂Z2
c∈{ R,G,B }:下标,颜色通道
y:原始图像
yˆ :去噪图像
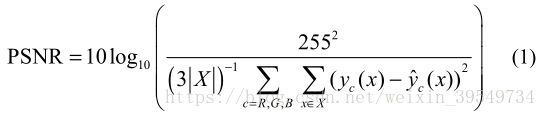
B.小样本量下的深度学习策略
深度神经网络通常有数百万个连接和权重。虽然ConvNets利用本地连接和共享权,但仍需要训练大量的权值。当ConvNets应用于大型数据集时,他们将获得惊人的结果。然而,我们发现ConvNets在小样本量的情况下容易发生过拟合,即训练集精度高,测试集结果差。对于水下图像识别任务,一个实际的问题是如何获得足够的样本图像来训练ConvNets。基于深度信念网络(deep belief network, DBN)的训练过程,我们提出了一种在小样本情况下的水下图像识别方法。更具体地说,通过一小组鱼的图像,我们解决了水下活鱼的识别问题。
小样本量情况下的水下图像识别过程主要分为三个阶段:
(1)第一阶段:使用大型图像数据集ImageNet对ConvNets进行预训练。ConvNets不仅是一个分类器,还是一个特征提取器。卷积神经网络的隐藏层学习以一种易于预测目标输出的方式来表示网络的输入。卷积神经网络的训练阶段完成后,预训练的卷积神经网络将对图像的颜色、纹理和边缘等信息比较敏感。由于自然图像彼此之间有一定的共性,所以对一个卷积神经网络进行预训练是合理的。
ImageNet为我们提供了这么大的图像数据集,它有超过1500万张标记为高分辨率的图像,属于大约22000个类别。每个概念的图像都是有质量控制和人为注释的。
(2)第二阶段:使用我们的小样本图像对预训练的ConvNet进行微调。通过随机梯度下降法可以进一步训练多层结构,利用图像标签中非常有限的信息对训练前的权重进行微调。
(3)第三阶段:测试经过训练的ConvNets的性能。卷积神经网络可以用于图像识别,精度满足应用要求。
四、图像识别实验
A.鱼类识别数据
本文使用的鱼类识别数据来自Fish4Knowledge。图2显示了从一个实时视频数据集中获得的图像(一共2120张图像),在10个代表性鱼类品种下面分别是名称和数量。数据不平衡,最常见的物种是最少的物种(只有90幅图像)的5倍多,直接使用深度学习方法很难获得高的识别准确率。

![]()
图2 十种代表性鱼类。每幅图片代表10个鱼群中的一个鱼种,它们的名字和数量都标在下面。显示的图像是理想的,因为数据集中的许多其他图像质量较差。
B.图像去噪
图像去噪可以使后续的鱼识别任务更加容易。为了克服标准中值滤波器的缺点,采用改进的中值滤波器抑制图像噪声。图3分别展示了用标准中值滤波器和改进的方法分别处理有噪声的鱼图像的结果。

图3 分别采用标准中值滤波和改进中值滤波对噪声图像进行处理。(a)原始图像。(b)3×3标准中值滤波的结果。(c)5×5标准中值滤波的结果。(d)改进的中值滤波结果。
从图3可以看出,该方法在保留原始图像细节的同时,能有效抑制噪声。
为了进行定量比较,我们根据公式(1)计算了三种不同方法处理的图像的PSNR, PSNR的改善可以从表I中看出(通过比较最后一列中的数值和其他两列中的任何一列中的数值);可以观察到,这种改善是显著的,通常大于2dB。
TABLE I PSNR OF STANDARD FILTER AND IMPROVED FILTER

C.卷积神经网络的体系结构
利用自然信号特性的ConvNets背后有四个关键思想:本地连接、共享权重、池化和多层使用。我们使用的ConvNets的总体架构如图4所示,与AlexNet几乎相同。每个卷积层的权值都是从0均值高斯分布初始化的,标准差为0.01。
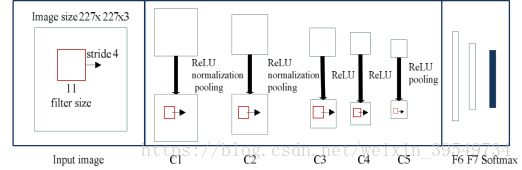
图4 使用的ConvNets架构,显示了不同层的定义。前五层为卷积层,其余三层为全连通层,最后一层输出的数量在不同的训练阶段会发生变化。
D.卷积神经网络的训练与测试
网络的训练分为两个阶段。
第一阶段:模型在从ImageNet获得的数据集上进行预训练,在1000个类别中每个类别大约有1000个图像。经过预处理后,ConvNets的权值进行了适当的初始化,其中大部分信息来自图像建模。
第二阶段:我们使用Caffe框架实现了体系结构。图像预处理的鱼都调整到227×227,鱼图像分为三个子集:500张图片(10类图像,每类50张)作为训练集,200张图片(10类图像,每类20张)作为验证集,剩下的1420张测试集。
最后一层的输出数量从1000变化到10,并被发送到Softmax分类器,这将生成10个类标签的分布。采用batch=40的随机梯度下降法,通过对分类误差的反向传播,对训练好的神经网络进行微调。学习率设置为0.001,同时权重衰减为0.005,动量项为0.9。前七层的学习率相同,但最后一层的学习率是前七层的10倍。当训练迭代的整数倍为1000时,学习率降低了2倍。
经过5000次迭代,验证准确率达到85.50%,测试准确率达到85.08%。图5为训练损失与训练迭代图,图6为验证精度与训练迭代图,证明了我们提出的框架对于小样本情况下的图像识别是有效的。
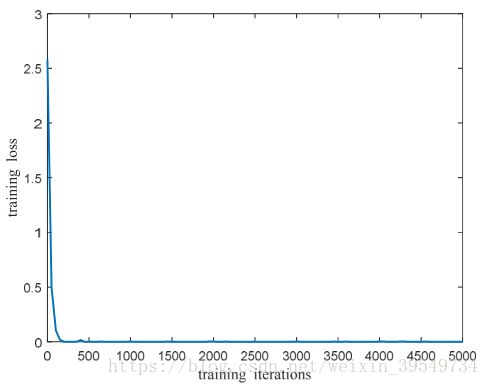
图5 Training loss vs. training iterations of the second training stage.Training loss declines sharply and tends to be 0 after about 500 iterations.
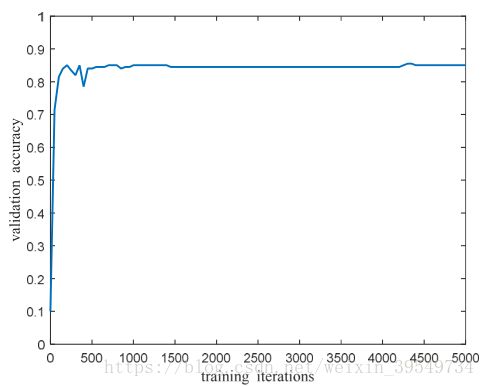
图6 Validation accuracy vs. training iterations of the second training stage.Validation accuracy rises quickly at the first 200 iterations and tends to bestable after about 1000 iterations.
五、总结
本文提出了一种改进的中值滤波器和一种有效的基于卷积神经网络的水下鱼类识别框架,可方便地推广到其他的识别应用中。这些特征是从训练数据中学习到的,所以不需要专门的鱼知识。在此框架下,我们希望能够推进水下图像识别研究的深度学习研究,特别是在样本图像较少的情况下。它可以有利于海洋防御,以及商业应用,如渔业和水产养殖。
更多AI资源请关注公众号:大胡子的AI

欢迎各位AI爱好者加入群聊交流学习:882345565(内有大量免费资源哦!)
版权声明:本文为博主原创文章,未经博主允许不得转载。如要转载请与本人联系。