练习 23 字符串,字节和字符编码
要做这个练习你需要去下载一个名为 languages.txt 的文本文件(下载地址:https://learnpythonthehardway.org/python3/languages.txt,点开,右键,“另存为” txt 格式,放在你的练习文件夹,再打开。)
这个文件列了一个人类的自然语言列表来说明一些有趣的概念:
- 现代计算机是如何储存自然语言然后显示和加工的,还有 python 3 是如何调用这些字符串的。
- 你是如何(同时也是必须)把 python 的字符串 “编码”(encode)和“解码”(decode)成字节(byte)形式的。
- 如何处理你字符串里以及字节处理过程中的错误。
- 如何阅读代码并弄明白它的意思,即使你从来都没有看到过这些代码。
此外,你还会一睹 python 3 的 if 语句以及处理一系列东西的列表。你不用马上掌握这些代码或者理解这些概念,你会在接下来的练习中有足够的练习来学习。现在你只需要尝个鲜,并且弄明白前面所述的四个问题即可。
| 警告! |
|---|
| 这个练习很难,需要你理解的信息很多,而且这些信息深入到计算机理论中。这个练习之所以很难,是因为 python 的字符串本身很复杂,很难用。我建议你在学这个练习的时候放慢节奏。写下你不明白的每一个单词,然后到网上查一查。如果你实在卡住了,也别停下,继续往后学,循序渐进,直到你慢慢领会这些东西。 |
初始研究
我准备教你如何研究一段代码来发现它的奥秘。你要用到 languages.txt 文件,所以先确保你已经下载了这个文件。这个 languages.txt 文件包含了一个人类各种语言的列表,并且是以 UTF-8 进行编码的。
输入如下代码(新东西有点多,先敲完再说):
ex23.py
1 import sys
2 script, encoding, error = sys.argv
3
4
5 def main(language_file, encoding, errors):
6 line = language_file.readline()
7
8 if line:
9 print_line(line, encoding, errors)
10 return main(language_file, encoding, errors)
11
12
13 def print_line(line, encoding, errors):
14 next_lang = line.strip()
15 raw_bytes = next_lang.encode(encoding, errors=errors)
16 cooked_string = raw_bytes.decode(encoding, errors=errors)
17
18 print(raw_bytes, "<===>", cooked_string)
19
20
21 languages = open("languages.txt", encoding="utf-8")
22
23 main(languages, encoding, error)
你肯定很好奇这个文件是用来干嘛的,可以运行它看看,以下是运行结果(注意运行时需要输入包括文件名在内的三个参数):
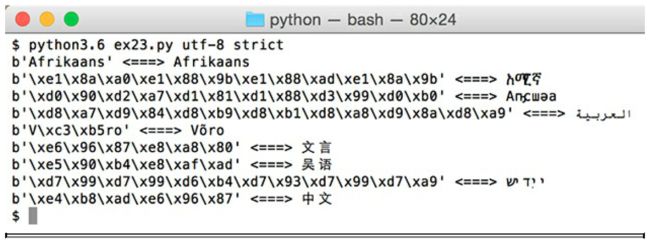
| 警告! |
|---|
| 我在这儿用了图片来展示你应该看到的内容。因为很多人的电脑不是用 UTF-8 来显示的,所以我得用图片来确保你知道我要呈现的是什么。即使是我自己的 typesetting system (LaTeX) 也处理不了这些编码,迫使我必须使用图片。如果你看不到这些,很可能是你的终端没有用 UTF-8 来显示,你得想想办法。 |
这些例子用了 utf-8 、utf-16 和 big5 编码来说明这种转换,以及你可能会遇到的错误类型。这些名字在 Python 3 中被称为 “codec”(编码器),但是你要用参数“encoding”。在这个练习的最后我列出了一个可用的编码表(encodings)以便你进行更多的练习(PDF文件里貌似没有这个编码表欸,找到的童鞋吱一声,大家也可以到网上查查)。我会在随后讲到这些东西的含义。你只用知道这些东西是如何工作的,这样我们就能在后面提及以及用到它们。
当你运行过几次之后,复习一遍你的符号列表,猜猜它们是做什么的,写下来。然后到网上找找它们的用法,是否跟你猜的一样。别担心你查不到,试试看。
开关、惯例(conventions)和编码
在我深入讲解这些代码的含义之前,你需要学习一些关于数据是如何存储在计算机中的基本知识。现代计算机非常复杂,但是核心就是大量的电灯开关。计算机用电来切换开关。这些开关可以以“开”代表 1,以“关”代表 0。以前有各种各样奇怪的计算机做的不只是 1 和 0 的事情,但现在所有的计算机都是一堆 1 和 0。1 代表着运行、有电、开着、进行、存在。0 代表着结束、完成、消失、关机、没电。我们把这些 1 和 0 叫做 “比特”(bits)。
但是,一个只能让你用 1 和 0 操作的计算机将会非常低效和无聊。计算机接收了这些 1 和 0 之后,会用它们来编码更大的数字,比如用 8 个 1 和 0 来编码 256 个数(0-255)。那么编码到底是什么意思?它其实就是一个关于比特序列如何表示数字的公认标准,比如人们约定 00000000 就代表数字 0,11111111 就代表数字 255,00001111 就代表数字 15。即便是在计算机诞生早期的世界级战争中,计算机也是用这些约定的 1 和 0 来做大规模计算的。
现在我们把一个“字节”(byte)称为 8 个比特(1 和 0)的序列。过去每个人都有他们自己对于字节的惯例(convention),所以你还是会遇到一些人说,这项规定应该灵活一些,比如可以是 9 个、7 个或者 6 个字节序列。但是现在我们都说一个字节是 8 个比特,这是我们的惯例,它定义了我们对于字节的编码。当然还有用 16、32、64 甚至更多个比特来给字节编码的。
一旦你有了字节,你就可以开始存储和显示文本了,不过要用另一种惯例来让数字映射(map)成文字。在计算机发展的早期,有很多关于映射的惯例,有 8 个比特的,7 个比特的(或者更多或更少)。但是最终美国信息交换标准编码(即 ASCII 码)成为最流行的惯例。这个标准建立了从一个数字到一个字母的映射,比如 90 是 Z,用比特的话就是 1011010,对应到计算机里面的 ASCII 码表。
你可以在 Python 里面试试这个(Windows 系统下在 Powershell 输入 python ,然后回车,就会出现 >>>,MacOS 输入 Python3.6):
>>> 0b1011010
90
>>> ord ( ' Z ' )
90
>>> chr ( 90 )
' Z '
>>>
首先,我用二进制写了数字 90,然后我基于字母 'Z' 得到了对应的数字,接着我把这个数字转化成字母 'Z' 。你不用记这些内容,我用 python 用了这么长时间好像只写过两次这个东西。
一旦我们有了 ASCII 惯例来用 8 个比特(即一个字节)给一个字符编码,我们就可以把它们“串”(string)在一起来组成单词。比如如果我想写我的名字“Zed A. Shaw”,我只需要用 [90, 101, 100, 32, 65, 46, 32, 83, 104, 97, 119] 这样一系列字节就行了。大多数计算机上的早期文本都是存在存储器里的字节序列,计算机用它们把文字呈现给人看。同样的,这件事情的本质还是一些约定俗成的开关转换。
不过 ASCII 有一个问题,它只能编码英文以及一些相似的语言,而且一个字节只能表示 256 个数字(0-255,或者 00000000-11111111)。很显然,世界上正在使用的语言远远超过 256 个字符。因此不同国家创建了针对他们自己语言的编码惯例,虽然这些都管用,但是它们只适用一种语言。这就意味着,如果你想把一本英语书的书名放在一个泰语句子中,就会比较麻烦,你就需要一个泰语编码和一个英语编码。
为了解决这个问题,一群人创建了 Unicode,也就是针对所有人类语言的“统一编码”(Universal encoding)。Unicode 提供的解决方案跟 ASCII 码表类似,但是相比之下,前者更大。你可以用 32 个比特来编码一个 Unicode 字符,这比我们能找到的所有字符可能都要多。一个 32 位比特的数字意味着我们可以存储 4,294,967,295 个字符(2^32), 这对任何一种人类语言,甚至外星语言来说,都够用了。现在我们用多余的空间来表示一些重要的东西,比如 emoji 表情。
我们现在有了针对任何字符的编码协定,但是 32 比特是 4 个字节,这就意味着对于大多数我们想要编码的文本会浪费很多空间。我们也可以用 16 比特(2 个字节),但仍然很浪费。因此后来出现了一种很妙的惯例:用 8 个比特来编码大多数通用字符,然后当我们需要编码更多字符的时候再使用更多的数字。这意味着我们有了一种压缩(compression)编码惯例,使得用 8 个比特来编码大多数常用字符,并在需要时切换成 16 或 32 个比特这件事成为可能。
在 Python 中编码文本的惯例叫做“utf-8”,即“Unicode Transformation Format 8 Bits”,它是一个把 Unicode 字符编码成字节序列(字节即比特序列,比特序列又即开关转换序列)的惯例。你也可以用其他编码惯例,但是 utf-8 是目前的标准。
分解输出结果
我们现在可以再看一下上面命令的输出结果。先看前面几行结果:
ex23.py 脚本其实就是把字节写在 b' ' 里面,然后把它们转换成 UTF-8 编码(或者其他你设定的编码)。左边是每一个 utf-8 字节对应的数字,右边是 utf-8 实际输出的字符。之所以这样呈现,是为了让你明白 <===> 左边是 Python 用来存储字符串的数字字节或者“原始”(raw)字节,设置 b' ' 是为了告诉 Python 这是“字节”(bytes)。这些原始字节之后被“加工”(cooked)然后显示在右边,以便让你看到你的终端呈现出来的真正的字符。
分解代码
我们已经对字符串和字节序列有了一定的理解。在 Python 中,一个字符串就是一个 UTF-8 编码的字符序列,用来显示或者进行文本操作。而字节是一些“原始”的字节序列,Python 用来存储这些 UTF-8 字符串并以 b' 开头来告诉 python 你正在处理原始字节。这些都基于 python 对于文本操作的惯例。
这是一个关于如何编码字符串和解码字节的 Python 会话展示:

你需要做的就是记住如果你有原始字节,那你必须用 .decode() 来获取字符串。原始字节没有相关惯例,它们只是一些没有意义的数字组成的字节序列。所以你必须告诉 Python“把这些解码成 utf 字符串”。
如果你有一个字符串,并且想要发送、保存、分享它,或者对它做一些其它的操作,通常情况下都可行,但是有时 Python 会扔出一个错误说它不知道如何编码。其实,Python 知道它内部的惯例,它只是不知道你需要的是哪个。在这种情况下,你必须用 .encode() 来获取你需要的字节。
记住这些的方法(虽然我其实都是每次要用才查的)就是记住 “DBES” 这个记忆符号,它代表“Decode Bytes Encode Strings”(解码字节,编码字符串),当你思考如何转换字节和字符串的时候,可以在脑子里默念“迪拜斯”(DBES 发音),有字节要字符串,解码字节,有字符串要字节,编码字符串。
把这个放进脑子里之后,咱们来一行一行分解一下 ex23.py 的代码:
ex23.py
1 import sys
2 script, encoding, error = sys.argv
3
4
5 def main(language_file, encoding, errors):
6 line = language_file.readline()
7
8 if line:
9 print_line(line, encoding, errors)
10 return main(language_file, encoding, errors)
11
12
13 def print_line(line, encoding, errors):
14 next_lang = line.strip()
15 raw_bytes = next_lang.encode(encoding, errors=errors)
16 cooked_string = raw_bytes.decode(encoding, errors=errors)
17
18 print(raw_bytes, "<===>", cooked_string)
19
20
21 languages = open("languages.txt", encoding="utf-8")
22
23 main(languages, encoding, error)
第 1-2 行: 以通常的命令行参数开始,这个你已经学过了。
第 5 行: 我把这段代码的主体部分定义为一个叫“main"的函数,这个函数会在脚本最后运行东西的时候被调用。
第 6 行:这个函数所做的第一件事就是从给出的 languages 文件中读取一行。你之前已经做过这个操作了,所以这儿没什么新内容,就像以前一样读取文本文件即可。
第 8 行: 现在我用了一些新东西。你将会在这本书的后半部分学到相关内容,所以把这里当作一个尝鲜吧。这是一个 if 语句,它让你在 Python 代码中做决定。你可以“测试”一个变量的真假,基于其真假,运行或者不运行这段代码。在本例中,我测试了一行中是否有内容。当 readline 函数到达文件末尾的时候,它会返回空字符串,if 这一行就是为了测试这个空字符串。只要 readline 给了我们一些东西,结果就会是 true ,后面的代码就会运行(比如缩进的 9-10 行),当结果是 false 的时候, python 就会跳过 9-10 行。
第 9 行: 然后我调用了一个单独的函数来做这一行的真正打印。这简化了我的代码,并且让我更容易理解。如果我想学习这个函数的作用,我可以跳到那儿进行学习。一旦我知道了 print_line 是做什么的,我就可以把我的记忆附到 print_line 这个名称下,然后忘掉细节。
第 10 行: 我在这儿写了一小段非常神奇的代码。我在 main 函数内部又调用了 main 函数。其实也不神奇,因为在编程里面没有真正神奇的东西,所有你需要的信息都在那儿。这里我在一个函数里面又调用了它,好像看上去不太合理。但是问问你自己,为什么不合理?其实没有技术原因,如果一个叫 main 的函数只是跳到顶部,而我在这个函数的底部调用它,它就会回到顶部然后再次运行,这样就会形成一个循环(loop)。现在看第 8 行,你会看到 if 语句避免了这个函数无限循环。仔细研究研究这块内容,因为它是一个很重要的概念,不过如果你一下子理解不了也不用担心。
第 11 行 现在我开始定义 print_line 函数,它用来编码 languages.txt 文件中的每一行内容。
第 13 行 现在我终于获得了从 languages.txt 中收到的语言,并把它们编码成原始字节。还记得“DBES”这个辅助记忆词吗?“Decode Bytes, Encode Strings”,解码字节,编码字符串。next_lang 变量是一个字符串,因此要获得原始字节,我必须对它调用 .encode() 函数来“编码字符串”。我把我想要的编码以及如何处理错误传递给 encode() 。
第 14 行 然后我做了额外一步,通过从 raw_bytes 创建一个 cooked_string 变量来逆向展示第 15 行。记住,“DBES”说的是“解码字节”,raw_bytes 是字节,所以我对它调用了 .decode() 来获取一个 python 字符串。这个字符串应该和 next_lang 变量是一样的。
第 15 行 我已经定义完了所有函数,现在我想打开 languages.txt 文件。
第 16 行 在这个脚本的结尾只是用所有正确的参数运行了 main 函数,以保证一切正常运行,避免循环。记住这个之后会跳转到第 5 行 main 函数被定义的地方,然后在第 10 行又被调用了一次,会造成它的循环。不过第 8 行的 if 语句又会阻止它无限循环。
深入了解编码
我们现在可以用我们的小脚本去探索其他的编码。下面是我针对其他不同编码所做的一些操作,看看如何分解它们:
(注:英文版PDF中这里貌似把图片贴错了,贴的还是前面“分解代码”那一部分的图,所以这里大家就开下脑洞自己想象吧=.=)
首先,我做了一个简单的 UTF-16 编码,以便你了解和 UTF-8 比起来,它是如何变换的。你也可以用 “utf-32” 来看看它有多大,以及如何用 UTF-8 来节省空间。之后我尝试了 Big5,你会看到 Python 一点儿也不喜欢它。它扔了一个错误说 ’big6’ 无法在位置 0 上解码部分字符(我也不知道为什么是 6)。一个办法是告诉 Python 取代 Big5 编码下任何不好搞的字符。这是下一个例子,你会看到它在任何无法匹配 Big5 编码的地方放了一个 ? 符号。
拆解
你可以试试做以下事情:
- 找到其他编码方式编码的文本字符串,然后把它们放到
ex23.py文件中,看它如何分解。- 给一个不存在的编码方式,看看会发生什么。
- 额外挑战:重新用 b'' 字节来写,不用 UTF-8 字符串,有效转换这个脚本。
- 如果你可以做到上面这个,你也可以把这些字节通过移除部分的方式分解开,看看会发生什么。你需要移除多少来让 Python 分解?你能够移除多少来破坏字符串输出结果但是又能通过 Python 的解码系统。
- 用你在第 4 点中学到的东西看看你能不能破坏这个文件。你得到的错误信息是什么?你能在文件通过 Python 的解码系统下带来多少破坏?