论文笔记:RetinaNet(Focal Loss for Dense Object Detection)
文章目录
- 1、摘要
- 2、介绍
- 3、相关研究
- 3、焦点损失
- 3.1、平衡交叉熵
- 3.2、焦点损失定义
- 3.3、类不平衡和模型初始化
- 3.4、类不平衡和 two-stage 检测器
- 4、RetinaNet 检测器
- 4.1、训练
1、摘要
o n e − s t a g e one-stage one−stage 检测器对目标可能的位置进行密集采样,相比于 t w o − s t a g e two-stage two−stage 方法更简单、速度更快,但是精度稍显不足。作者发现,检测器训练过程中,背景-前景类别极端不平衡是导致这一结果的主要原因。为了解决这一问题,作者重构了标准交叉熵( C E CE CE)损失来减小分类正确的样本的损失权重。 F o c a l L o s s Focal~Loss Focal Loss 聚焦于难分样本的训练,并且减小数量较多的易分负样本的影响。
2、介绍
R − C N N R-CNN R−CNN 类检测器通过 t w o − s t a g e two-stage two−stage 串联以及启发式采样来解决类别不平衡问题。在第二分类阶段,采用启发式采样,比如固定前景-背景比( 1 : 3 1:3 1:3),或者在线难分样本挖掘( O H E M OHEM OHEM)。
o n e − s t a g e one-stage one−stage 虽然也可以采用同样的启发式采样,但是效率低下,因为训练过程仍然被易分背景样本主导。这种低效是目标检测中典型的问题,通常通过自举或者难分样本挖掘来解决。
作者提出 F o c a l L o s s Focal~Loss Focal Loss 来解决样本不平衡问题。损失函数是一个动态缩放的交叉熵损失,当正确类的置信度增加时,缩放因子为 0 0 0。
如图 1 1 1 所示。
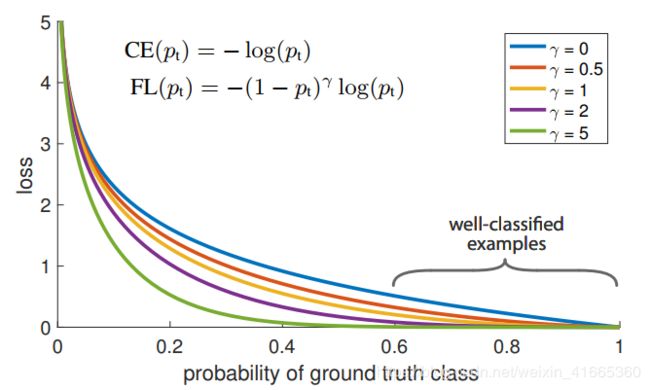
图 1. l o s s loss loss 随着 g r o u n g t r u t h groung~truth groung truth 类别置信度的变化曲线
直观上,训练时缩放因子可以急剧减小易分样本权重,关注难分样本。作者提出 F o c a l L o s s Focal~Loss Focal Loss 的具体形式并不重要。
作者设计 o n e − s t a g e one-stage one−stage 目标检测器,称之为 R e t i n a N e t RetinaNet RetinaNet,因为它在输入图像中对目标位置进行密集采样。它的设计特点是高效的特征金字塔网络并且使用锚框。
如图 2 2 2 所示,网络性能超越了之前 o n e one one 和 t w o − s t a g e two-stage two−stage 模型。
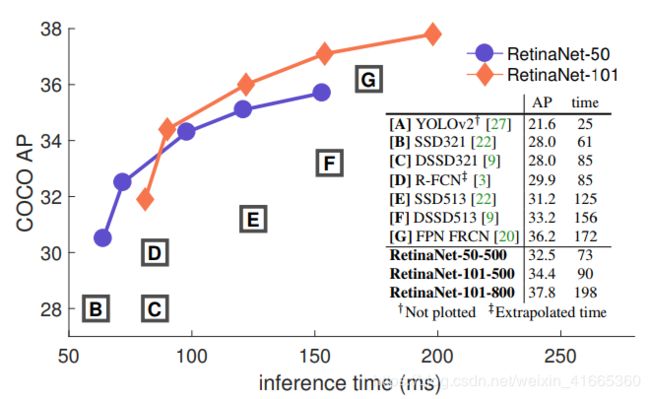
图 2. 各模型性能比较
3、相关研究
作者研究的重心在于,在相似或更快的检测速度下, o n e − s t a g e one-stage one−stage 检测器的精度是否可以匹敌甚至超越 t w o − s t a g e two-stage two−stage 检测器。作者强调, R e t i n a N e t RetinaNet RetinaNet 的顶尖的检测性能不是源于网络设计的创新,而是新的损失函数的设计。
类别不平衡
类别不平衡导致两个问题:
- 由于大部分候选位置是易分负样本,没有有用的学习信号,因此训练效率低。
- 易分负样本会抑制训练,导致模型退化。
通常的解决方法是训练时采用难分负样本挖掘,或者采用更复杂的抽样方法。作者提出 F o c a l L o s s Focal~Loss Focal Loss 来解决这一问题,不需要采样,没有易分负样本主导损失。
鲁棒损失
与鲁棒损失相反,焦点损失聚焦于一组稀疏的难分样本。
3、焦点损失
焦点损失被设计用于处理 o n e − s t a g e one-stage one−stage 目标检测器训练时存在的极端样本不平衡问题( 1 : 1000 1:1000 1:1000)。从二分类的交叉熵损失( C E CE CE)引入焦点损失。
(1) CE ( p , y ) = { − log ( p ) if y = 1 − log ( 1 − p ) otherwise \operatorname{CE}(p, y)=\left\{\begin{array}{ll}{-\log (p)} & {\text { if } y=1} \\ {-\log (1-p)} & {\text { otherwise }}\end{array}\right.\tag1 CE(p,y)={−log(p)−log(1−p) if y=1 otherwise (1)
定义 p t p_t pt 为:
(2) p t = { p if y = 1 1 − p otherwise p_{\mathrm{t}}=\left\{\begin{array}{ll}{p} & {\text { if } y=1} \\ {1-p} & {\text { otherwise }}\end{array}\right.\tag2 pt={p1−p if y=1 otherwise (2)
将 C E ( p , y ) CE(p,y) CE(p,y) 重写为: C E ( p , y ) = C E ( p t ) = − log ( p t ) \mathrm{CE}(p, y)=\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\log \left(p_{\mathrm{t}}\right) CE(p,y)=CE(pt)=−log(pt)
C E CE CE 损失可以看做图 1 1 1中蓝色曲线(上)。这一损失有一个显著特性,即使是正确分类的样本,也会有一个不小的损失函数值。当把易分样本的损失值相加,其损失值会压倒稀有类别。
3.1、平衡交叉熵
一种简单的处理方法是为类别 1 1 1 引入权重因子 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1],为类别 0 0 0 引入权重因子 1 − α 1-\alpha 1−α。实际上, α \alpha α 可以通过逆类频率来设置,或者作为超参数通过交叉验证来设置。为了便于说明,以类似于定义 p t p_t pt 的方式来定义 α t \alpha_t αt。将 α t \alpha_t αt 平衡的损失写成:
(3) C E ( p t ) = − α t log ( p t ) \mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)\tag3 CE(pt)=−αtlog(pt)(3)
3.2、焦点损失定义
尽管 a l p h a alpha alpha 能够平衡正负样本,但是不能够区分易分/难分样本。作者提出新的设计方案,减少易分样本权重,聚焦难分负样本的训练。
通过增加权重模块 ( 1 − p t ) γ \left(1-p_{\mathrm{t}}\right)^{\gamma} (1−pt)γ 来实现,可调聚焦参数 γ ≥ 0 \gamma\ge0 γ≥0。
(4) F L ( p t ) = − ( 1 − p t ) γ log ( p t ) \mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)\tag4 FL(pt)=−(1−pt)γlog(pt)(4)
图 1 1 1 展示了 γ ∈ [ 0 , 5 ] \gamma\in[0,5] γ∈[0,5] 时的变化曲线。 F o c a l L o s s Focal~Loss Focal Loss 展示了两个特性:
- 当样本被误分类,并且 p t p_t pt 很小时,模块因子接近于 1 1 1,对损失影响不大。当 p t → 1 p_{\mathrm{t}} \rightarrow 1 pt→1,因子趋于 0 0 0,正确分类的样本权重减小。
- 平滑地调整聚焦参数 γ \gamma γ,易分样本权重减小。当 γ = 0 \gamma=0 γ=0 时, F L FL FL 等于 C E CE CE,并且随着 γ \gamma γ 因子的增加,模块因子的效果也同样增加(实验中, γ = 2 \gamma=2 γ=2 工作得最好)。
模块因子减小了易分样本对损失的影响,并且扩展了样本产生低损失的范围。比如, γ = 2 \gamma=2 γ=2 时,样本分类 p t = 0.9 p_t=0.9 pt=0.9 产生的损失比 C E CE CE 得到的损失小 100 100 100 倍,当 p t ≈ 0.968 p_{\mathrm{t}} \approx 0.968 pt≈0.968 时,产生的损失比 C E CE CE 得到的小 1000 1000 1000 倍。这相应地增加了纠正误分类样本的重要性(当 γ = 2 \gamma=2 γ=2, p t ≤ 0.5 p_t\le0.5 pt≤0.5 时,最大缩小 4 4 4 倍)。
实际中使用 α \alpha α 平衡 f o c a l l o s s focal~loss focal loss:
(5) F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) \mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)\tag5 FL(pt)=−αt(1−pt)γlog(pt)(5)
相比于非 α \alpha α 平衡,这有微小的性能提升。最后,损失层的实现将用于计算 p p p 的 s i g m o i d sigmoid sigmoid 运算与损失计算相结合,获得更好的数值稳定性。
3.3、类不平衡和模型初始化
二分类模型默认初始化对输出 y = − 1 o r y = 1 y=-1~or~y=1 y=−1 or y=1 是等概率的。但是,这种初始化下,在训练早期,由于类别不平衡,样本多的类别会主导损失并导致训练不稳定。为了应对这种情况,作者引入了“先验”的概念,即在训练开始时,模型为稀有类(前景)估计 p p p 值。以 π \pi π 定义先验,并使模型为稀有类别样本估计的 p p p 值较小,如: 0.01 0.01 0.01。这是模型初始化的改变,不是损失函数的改变。作者发现这样能够在严重类别不平衡时提升交叉熵和焦点损失的训练稳定性。
3.4、类不平衡和 two-stage 检测器
t w o − s t a g e two-stage two−stage 检测器通常有两种机制来处理类不平衡问题。
- t w o − s t a g e two-stage two−stage 串联:第一阶段区域提议大大减小可能的目标位置,而且由于是可能的目标位置,可以筛除大多数易分负样本
- 偏重采样:第二阶段训练时,通常采用偏重采样,比如正负样本比 1 : 3 1:3 1:3。
4、RetinaNet 检测器
R e t i n a N e t RetinaNet RetinaNet 由一个主骨网络和两个特定任务的子网络组成。主骨网络负责计算整幅图的卷积特征。第一个子网络负责对主骨网络的输出进行目标分类。第二个子网络负责边界框回归。
网络的结构如图 3 3 3 所示。
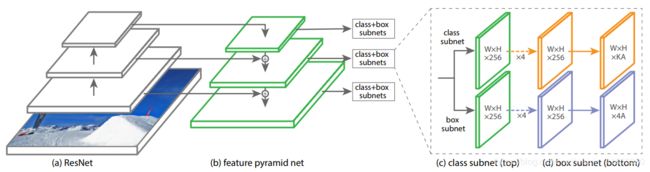
图 3. 在 R e s N e t ResNet ResNet 顶部使用 F P N FPN FPN 的 R e t i n a N e t RetinaNet RetinaNet 网络结构
FPN
F P N FPN FPN 通过自顶向下路径和横向连接来增强卷积网络,从而有效地从单个分辨率输入图像构建丰富的多尺度特征金字塔。特征金字塔的每一层可以用于检测不同尺度的目标。
作者在 R e s N e t ResNet ResNet 的头部建立 F P N FPN FPN。作者建立了 p 3 p_3 p3 到 p 7 p_7 p7 层金字塔, l l l 表示金字塔层( p l p_l pl 层的分辨率比输入图像分辨率低 2 l 2^l 2l)。所有的金字塔层有 C = 256 C=256 C=256 个通道。
Anchors
作者使用平移不变性的 a n c h o r anchor anchor。 a n c h o r anchor anchor 的面积从 3 2 2 32^2 322 到 51 2 2 512^2 5122 对应金字塔 p 3 p_3 p3 到 p 7 p_7 p7 层。每一层的 a n c h o r anchor anchor 有三个长宽比设计 [ 1 : 2 , 1 : 1 , 2 : 1 ] [1:2,1:1,2:1] [1:2,1:1,2:1]。作者添加了大小为原始三个长宽比 a n c h o r anchor anchor 的 { 2 0 , 2 1 / 3 , 2 2 / 3 } \{2^0,2^{1/3},2^{2/3}\} {20,21/3,22/3} 倍的 a n c h o r anchor anchor。因此,每一层 a n c h o r anchor anchor 数量为 9 9 9。相对于输入图像,它们的尺度覆盖了 32 − 813 32-813 32−813 像素。
每个 a n c h o r anchor anchor 被分配了一个长度为 K K K 的分类目标的 o n e − h o t one-hot one−hot 向量,其中 K K K 是目标类别数量,以及一个长度为 4 4 4 的目标边界向量。当交并比超过阈值 0.5 0.5 0.5 时, a n c h o r anchor anchor 被分配给 G T GT GT; I o U IoU IoU 在 [ 0 , 0.4 ) [0,0.4) [0,0.4) 时, a n c h o r anchor anchor 被分配给背景类。由于每个锚框最多分配给一个目标框,将它的长度为 K K K 的标签向量中的相应条目设置为 1 1 1,并将所有其他条目设置为 0 0 0。若一个 a n c h o r anchor anchor 没有被分配给目标框或者背景(当 I o U ∈ [ 0.4 , 0.5 ) IoU\in[0.4,0.5) IoU∈[0.4,0.5) 时),训练时忽略它。边界框回归目标被计算为每个 a n c h o r anchor anchor 和它分配的目标框之间的偏移,如果没有分配则忽略。
分类子网络
分类子网络在 F P N FPN FPN 的每一层使用小 F C N FCN FCN 来实现;子网络参数在金字塔各层实现共享。给定特征层的输入特征图有 C C C 个通道,子网络使用四个 3 × 3 3\times3 3×3 卷积层,每层有 C C C 个卷积核,使用 R e L U ReLU ReLU 激活,后面连接一个有 K A KA KA 个 3 × 3 3\times3 3×3 卷积核的卷积层。最后,使用 S i g m o i d Sigmoid Sigmoid 激活在每个空间位置输出 K A KA KA 个二进制预测。
边界框回归子网络
边界框回归子网络在 F P N FPN FPN 的每一层使用小 F C N FCN FCN 对每个 a n c h o r anchor anchor 到最近的 G T GT GT 框进行回归来实现。边界框回归子网络的设计和分类子网络的设计一致,除了输出为每个空间位置长度为 4 A 4A 4A 的线性输出。每个空间位置的每个 a n c h o r anchor anchor 的 4 4 4 个输出预测了 G T GT GT 框和 a n c h o r anchor anchor 的相对偏移量(使用 R − C N N R-CNN R−CNN 中标准框参数)。作者使用未知类边界框回归器,使用更少的参数,有同样的效果。尽管回归子网络和分类子网络有相同的结构,但是使用单独的参数。
4.1、训练
每个 F P N FPN FPN 层在经过检测置信度阈值 0.05 0.05 0.05 筛选后,最多只取置信度前 1 k 1k 1k 的预测框。结合所有层结果,采用阈值为 0.5 0.5 0.5 的非最大抑制产生最终预测。
焦点损失
图像的总焦点损失计算为所有 100 k 100k 100k 个锚框的焦点损失之和,由分配给 G T GT GT 框的锚框数量进行归一化。通过分配的锚框的数量而不是锚框的总数来进行归一化,是因为绝大多数锚框是易分样本,并且在焦点损失下产生的损失值可以忽略不计。最后注意到,赋给稀有类的权重 α \alpha α 也有一个稳定的范围,但它与 γ \gamma γ 相互作用,因此有必要一起选择两个参数(如表 1 a 1a 1a、 1 b 1b 1b)。一般来说,随着 γ \gamma γ 增大, α \alpha α 应该略微减小( γ = 2 , α = 0.25 \gamma=2,\alpha=0.25 γ=2,α=0.25 最佳)。
R e t i n a N e t RetinaNet RetinaNet 和 F o c a l L o s s Focal~Loss Focal Loss 切除实验结果如表 1 1 1 所示。
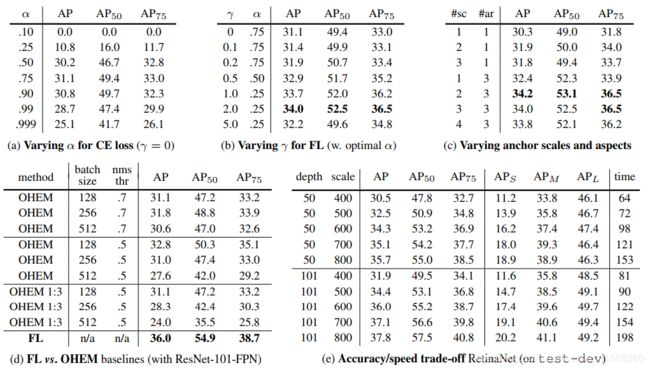
表 1. R e t i n a N e t RetinaNet RetinaNet 和 F o c a l L o s s Focal~Loss Focal Loss 切除实验结果
初始化
分类子网络的最后一层卷积偏置初始化为 b = − l o g ( ( 1 − π ) / π ) b=-log((1-\pi)/\pi) b=−log((1−π)/π), π \pi π 表示训练开始时, a n c h o r anchor anchor 以置信度 π \pi π 标记为前景。作者设置 π = 0.01 \pi=0.01 π=0.01。这样可以避免由于训练初始有大量的背景锚框产生大的、不稳定的损失值。