深度学习 - 理论笔记总结
深度学习笔记:
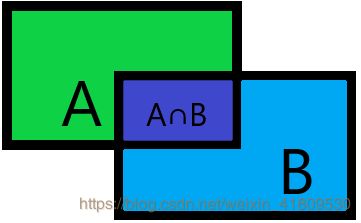
1. 描述常用3种IOU,分别针对那种情况使用?
① 交并比:交集/并集。即框和框的重叠的程度。为了删除一些同目标位置重叠的框。
② 交集/最小面积:为了删除预测框在真实框内部,且框住部分不完整的情况。
③ 最小面积/最大面积:yoloV3里作为目标位置上anchor框和真实框的置信度。
2. 描述数据增强的常用手段,yoloV4使用的手段?
数据增强:
(1) 裁剪:①中心裁剪,② 随机裁剪,③ 随机长宽比裁剪, ④ 上下左右中心裁剪, ⑤ 上下左右中心裁剪后翻转;
(2)翻转和旋转:① 水平翻转, ② 垂直翻转, ③ 随机角度翻转, ④ 随机角度旋转;
(3)遮挡: ① dropout, ② dropblock;
(4)图像变换: ① 尺寸变换, ② 标准化, ③ 填充, ④ 修改亮度、对比度、饱和度, ⑤ 转灰度图, ⑥ 线性变换, ⑦ 仿射变换, ⑧ 归一化;
(5)mosaic方法:随机裁剪多张样本的目标进行拼接。
yoloV4:
使用了mosaic和dropblock进行数据增强。
3. YOLOV3输入尺寸应该满足哪些条件,608分辨率的图片输入到yoloV3中。输出数据的尺寸是什么?
输入:416 * 416 * 3 ,32的倍数;
输出:S * S * 3 * ( cls + 4 + classnum ) ;
S 为输出尺寸的大小;(608/32=19)
3为锚框的数量;
cls为置信度,即有无目标;
4为预测框的偏移量;
classnum为网络检测的类别。
4. 描述YOLOV3的mAP指标。
(1)AP 平均精度:使用积分的方式来计算PR曲线与坐标轴围城的面积。
(2)mAP:所有类别的AP求平均。
5. dropout和dropblock的区别,分别用在什么地方?
① dropout(数据增强):随机遮盖像素点,这种遮盖对神经网络的作用很小,但是能够避免小物体被遮挡。
② dropblock:随机遮盖像素块,这种遮盖能有效增强样本数据,提高训练的难度,但是容易把小物体遮挡,造成误差。
6. L1,L2,smooth损失的优缺点?
(1)L1损失:
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向,范围是0到∞。
优点:对任何输入的数值,都有着固定的梯度,不会导致梯度暴涨,具有稳健性。
缺点:在中心点是折点,不能求导,而且会导致梯度振荡。
(2)L2损失:
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和。
优点:函数连续光滑,每个点都可以求导,具有较为稳定的解,不会造成梯度振荡。
缺点:在输入的数值较大,即较远处的时候,梯度过大,容易形成梯度暴涨的问题,不稳健。对异常点敏感。
(3)smooth L1:
smoothL1损失对离群点(异常点)更加鲁棒,相比于L2损失函数,其对离群点(指的是距离中心较远的点)、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。综合了L1,L2损失的优点,避免了它们的缺点。
7. 描述YOLOV4中使用到的网络子结构,并画出来。
① CBM = conv+BN+Mish

mish激活函数:Mish=x * tanh(ln(1+e^x))。
(ReLU和Mish的对比,Mish的梯度更平滑)
由于yoloV4比yoloV3的层次更深了,所以使用mish使得再更深层次的时候保证了网络的平滑,即准确性。
② CBL = conv+BN+LeakyRelu

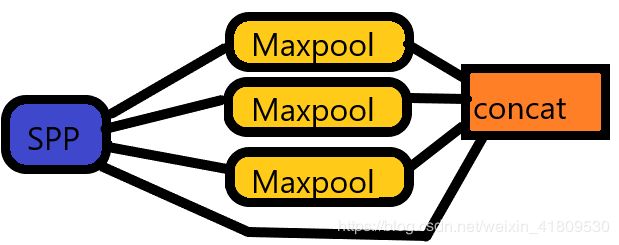
③ SPP:三个最大池化的输入再拼接concat。
三个池化采样不同的核进行尺寸(通过步长和padding控制一样的输出尺寸,便于concat)
“加入了SPP block,能够显著地改善感受域大小,而且速度几乎没有什么下降。”
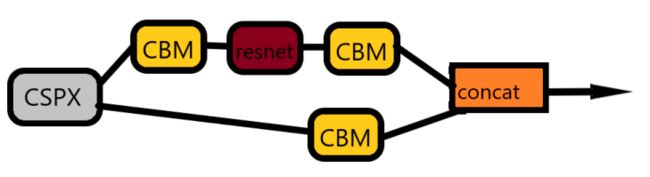
④ ResNet:两个CBM,一个用1 * 1卷积核,一个用3 * 3卷积核,再做残差。

⑤ CSPX:CBM+残差+CBM 再和输入的CBM做concat(v5是和输入的conv做concat)
8. 描述NMS的整个过程。
在物体检测中NMS(Non-maximum suppression)非极大抑制应用十分广泛,其目的是为了消除多余的框,找到最佳的物体检测的位置。
nms步骤:
① 所有框按照置信度的值从大到小排序;
② 选取置信度最大的框出来,与其他框做IOU;
③ 按一定阈值,将②中IOU大于该阈值的框删去,保留剩下的框,在按其置信度从大到小排序;
④ 重复第二步,直到所有框都筛选完。
9. YOLOV3的建议框怎么来的。
yoloV3的建议框选择:每个像素块中心有三个anchor框;
anchor框根据自己的数据集进行选择;
① 通过聚类算法,对数据集中的所有真实框进行聚类得到三个不同方向大小的anchor框;(适用于训练集很大的情况)
② 通过自己数据集目标真实框的位置、大小、方向,自定义三个anchor框。(适用于训练集少的情况)
10. 描述UNET的大致结构。
UNET:先下采样再上采样的编解码结构。(保留每一次下采样的特征,在上采样的同时进行裁剪拼接。)
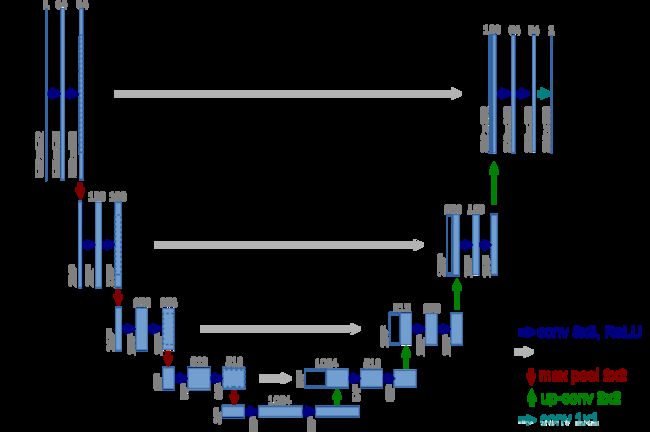
11. 描述MTCNN侦测的大致流程。
MTCNN侦测步骤:
① 输入图片进行图像金字塔,得到一组不同尺寸的图片。分别放入P网络进行侦测;
② 输入P网络侦测,对图像进行粗略侦测,尽可能保留所有有目标的框。(低置信度阈值,并通过nms去掉部分重叠框)还要通过反算得到框的实际位置(给后面两个网络裁剪、缩放后侦测)
③ 将P网络筛选后的框,输入R网络进行侦测,进一步做筛选,尽可能筛选掉没有目标的框以及部分目标和重叠的框。(nms)
④ 将R网络筛选后的框放入O网络侦测,(较高的置信度阈值,利用mns通过交并比删去大量重叠框,和再用最小比并集删去在目标内部不完整的框。)
⑤ 反算输出O网络最终筛选的侦测结果。
12. 描述为什么需要量化,量化的流程是啥?
量化的原理:一般来讲,我们神经网络输入的数值精度都是比较高的,因此就会计算比较的慢,所以我们可以量化一般值到INT8,即把权重映射到INT8的范围之间,计算速度快。
基本流程:
① 网络打包分块(将一个网络子块进行打包后,一起量化。例如:conv + BN + Relu糅合成一个模块。)——这里注意要使用量化支持的板块。
② 准备评估工具。(例如:top1、top5精确度、耗时、存储大小……)
③ 对原始网络进行训练。(先训练,后量化)
④ 开始量化。(量化前和量化后的评估指标作对比)
⑤ 做QAT伪训练。(量化后可能精确度下降,根据性能要求,再做训练)
13. 描述剪枝的种类,最常用的剪枝是哪种,为什么?
剪枝种类:
① 根据某种规则,按像素位置随机剪枝。
② 根据某种规则,按向量随机剪枝。
③ 再卷积核上做剪枝。(根据卷积核模的大小,判定剪枝位置)
④ 直接随机减去通道。
⑥ 剪枝分为:结构式剪枝和非结构式剪枝。
剪枝一般直接随机减去通道,对神经元进行剪枝。由于矩阵操作的并行化,减去单个像素或者向量并不能减少计算量。即有的硬件并不支持稀疏矩阵的运输,所以一般剪枝操作是直接减去整个神经元。
14. 描述蒸馏的原理。
蒸馏的原理:先预训练一个大模型,用大模型教小模型(大模型的结果在神经元的级别上作为小模型的先验),使得小模型有大模型的精度,性能又比大模型高。
15. 常用部署有哪些硬件端?
PC端:① 计算机、② 服务器;
移动端:① SDK、② HTTP、③ Android、④ IOS;
IOT部署: ① 英伟达Jetson:支持cuda、② 华为海思、 ③ 瑞芯微、 ④ 树莓派(cpu)……
16. 画出MobileV2的主要子结构。
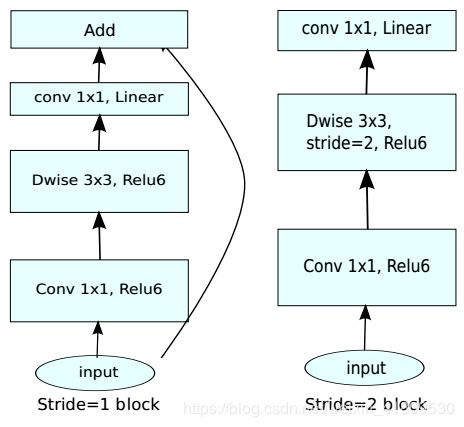
17. 跨层连接有哪些方法,这些方法的区别是什么?
(1)残差网络ResNet:将输入的信息,与输出时候相加。减少网络层次加深时候,信息的丢失。
(2)密集网络DenseNet:将输入的信息,与后面每一层的输入相加。使得网络形成对特征更丰富的描述和判别,但是这样会大大增大计算量。
(3)反馈网络RNN:将这一次输出的结果加入到反向传播后第二次输入中,使得前后信息得到关联。
18. BatchNormal的执行步骤,为什么需要BatchNormal?
BatchNormal的执行步骤就是,神经网络在每轮训练的时候,当前轮次中,对同批样本相应位置进行归一化处理。
BatchNormal能可以把训练数据集打乱,防止训练发生偏移;有效的避免过拟合,但是它对BatchSize的大小敏感。
- 没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,但是使用了BN,就不用小心的调参了,较大的学习率极大的提高了学习速度,
- Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等
- BN算法像卷积层,池化层、激活层一样也输入一层。BN层添加在激活函数前,对输入激活函数的输入进行归一化。这样解决了输入数据发生偏移和增大的影响。
19. 至少用3种视角描述过拟合的原因,哪些图像能发现过拟合,如何解决过拟合。
描述:
(1)从数据的角度看,训练样本太少,导致神经网络很容易就提取出训练样本的相同的特征,使得神经网络的输出结果在训练集上效果很好,但是在测试集上达不到想要的效果。
(2)从网络结构来看,由于模型过度复杂,使得模型对训练数据拟合较好,但同时拟合了噪声或者与目标不相关的信息导致了过拟合。
(3)例如,同一张试卷,我做了十遍上百遍,答案都倒背如流,但是换了一张试卷我就蒙圈了。这也就是说,我们在训练神经网络的时候,数据集的泛化能力越大越好。我们考试不也是题目刷得越多,各种各样的题目都刷,考试得能力就越强。
不同类型下的图像能够发现过拟合,例如我们在训练人脸侦测网络时候,训练集全是黄种人样本。导致侦测的时候侦测不到白种人和黑种人。
解决:
(1) 数据:① 增大数据集(这里要更多的提供各种不同样式的数据集,尽量提高数据集的泛化能力);② 数据增强(本质也是扩增数据集);③ 减少特征:删除与目标不相关特征,如一些特征选择方法。
(2)网络优化:①正则化:在损失函数中引入正则化项来降低模型的复杂度,从而有效的防止模型发生过拟合现象。② dropout(随机丢掉一些神经元,使网络变笨。)③迁移学习,可以解决由于训练数据较小引起的过拟合。
20. 描述梯度弥散原因,如何发现梯度弥散,如何解决梯度弥散。
原因:
随着神经网络的层次加深,特征会越来越抽象化,信息也会随着层次慢慢丢失,这样就会导致神经网络训练变得困难,而导致梯度弥散。我们知道深度学习就是利用反向传播,更新权重。当梯度消失的时候,权重就得不到更新。
发现:
① 看损失,某时刻训练时候,损失降不下去;② 看权重,某时刻某层神经网络的权重消失或者不再更新;③ 看梯度,某时刻某层神经网络的梯度变为0。
解决:
① 加残差Resnet;② 网络内部提高梯度;③ 更改激活函数,使用不饱和的激活函数。(例如LeakyRelu)