python 并行化:加快数据的处理
最近在做一个项目,遇到一个比较棘手的问题,那就是在用python 处理数据的时候效率非常低,在查阅了相关问题的同时,学习到不少小窍门,先记录一下供学习。
先给出一些方法,最后结合笔者自己的一个例子看一下实际效果
第一招:
numba神器
相关资料:https://www.jianshu.com/p/69d9d7e37bc5
第二招:
多进程的使用,不得不说的是为什么不使用多线程,因为多线程其实在python 里面是个表象,其本质上还是切分时间片,所以要想更好的利用其多核cpu,Python的话还是推荐多进程
主要就是使用了multiprocessing这个包,关于该包的使用网上资料多多,这里就不再多述大家可以查看便是
实际应用的话主要就是使用了pool池,一般模板的话就是:
import multiprocessing
import time
import os
print("温馨提示:本机为",os.cpu_count(),"核CPU")
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
if __name__ == "__main__":
#这里开启了4个进程
pool = multiprocessing.Pool(processes = 4)
for i in xrange(4):
msg = "hello %d" %(i)
pool.apply_async(func, (msg, ))
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print "Successfully"--------------------------------------------------------------------------------------------------------------------------------------------------------------------
在用python 处理数据的时候,经常需要使用pandas,尤其是需要操作dataframe这个数据结构,比如在机器学习特征工程的时候,需要对某一列(某个特征)做某一种操作(时间转化等等),其实这时候问题就是:
df.map(func) 而我们知道这种形式其实是非常适合做并行处理的(主要我们这里强调的是并行不是并发),那么就以笔者当前做的事情为例:
背景:我是要对一个生物分子提取指纹,说白了就是对'ROMol'这一字段下的数据做一定操作
如果什么优化方法也不加,即使用单进程做的话,大概需要多长时间呢(以处理50个分子为例):
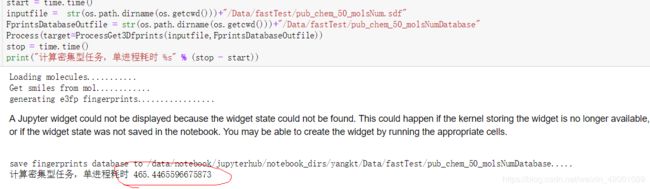
可以看到大概需要465秒,其实当前待处理的数据量大概是40万,这样算下去的话,大概要。。。。。。。。。呵呵
那么使用多进程呢?首先将50个分子分片成了10个小文件,即每个文件下有5个分子,然后为每个文件开启一个进程进行处理,相当于开启了10个进程,实验结果如下:
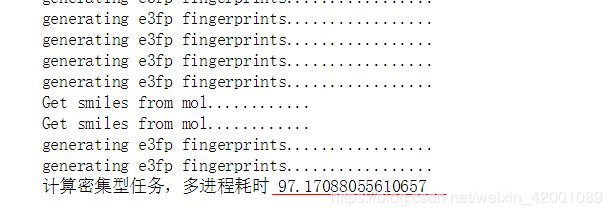
按理论计算的话,效率应该是提升10被吧,但是这里仅仅提高了大约4.7倍的样子
------------------------------------------------------------------------------------------------------------------------------------------------------------------
效果呢还是有的,但是上面这样貌似还是太麻烦了,还得对文件进行划分,最后使用多进程处理完了得到的应该也是一堆小文件,还得进行合并,尽管拆分和合并的过程很容易就可以写出来
那么有没有别的方法,就是说直接在dataframe上面进行多线程呢?肯定是有的啦
这里给出一个讨论:https://stackoverflow.com/questions/26187759/parallelize-apply-after-pandas-groupby
大家可以看一下
笔者将最关键的部分写出来:
import pandas as pd
from sklearn.externals.joblib import Parallel, delayed
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
df = pd.read_csv(inputfile)
df = df.groupby(df.index)
retlist = Parallel(n_jobs=jobNum)(delayed(youFunc)(group,Funcarg1,Funcarg12) for name, group in tqdm(df))
df = pd.concat(retlist)首先tqdm就是一个进度条,不用多理会
讨论区使用的源joblib即
from joblib import Parallel, delayed两则用法本无区别,但有时候sklearn继承的Parallel更优化
jobNum就是要开启的进程数目,youFunc就是自己定义的处理数据函数
比如说
def youFunc(df,ops):
if ops=='add':
df['c'] = df['a'] + df['b']
else:
df['c'] = df['a'] - df['b']
return df这里的df = df.groupby(df.index)
就是就是为了Parallel中的迭代,当然啦,讨论区也给出了直接使用multiprocessing这个包的做法,大家可以参考
在使用了这一种方法后,笔者的实验结果大概是1min6s 相比于97秒还是又提了不少。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
题外话:
为什么没有成倍的提高效率呢?答案多种多样,网上解释的也是天花烂醉,因为笔者这里的资源是12核,按1:1的话开了12个进程看了下效果:
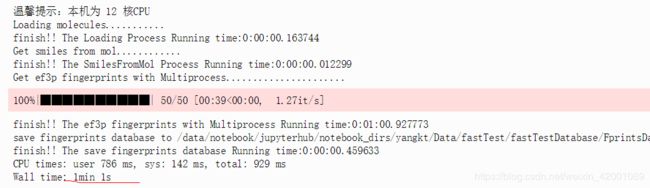
大概是61秒的样子,那么随着数据量的增大,带来的效率是不是会更好点呢?
于是乎又试了下150个分子:
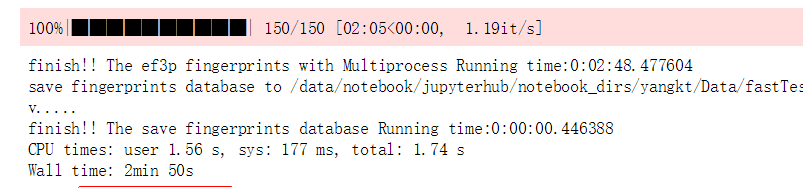
貌似是会更好点,按50个需要1min计算的话,大概还是会需要5天半,这是何等的。。。。。。。
其实笔者问题的根源是fun函数中提取指纹这一函数的问题,看了一下,有的分子需要2秒,有的分子居然需要20秒,
二者有区别吗:
哈哈哈,扯远了扯远了,,
--------------------------------------------------------------------------------------------------------------------------------------------------------------
总结一下本文主题和核心:
import pandas as pd
from sklearn.externals.joblib import Parallel, delayed
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
df = pd.read_csv(inputfile)
df = df.groupby(df.index)
retlist = Parallel(n_jobs=jobNum)(delayed(youFunc)(group,Funcarg1,Funcarg12) for name, group in tqdm(df))
df = pd.concat(retlist)所以使用这种方法的关键在于怎么构建一个类似迭代器的东西,在daatframe上面是使用了groupby
-----------------------------------------------------------------------------------------------------------------------------------------
多说一句:
这里是对index索引进行了分组,显然index是唯一的,分组之后没有意义,但是带来的好处就是其构成了迭代器,但是有的时候我们可以在此基础上进一步优化,比如现在dataframe有一列特征是动物类别【狗,猪,兔】,假设我们现在的处理是对一种类别进行同一种处理操作,假设对遇到狗时我们进行的特征操作是A,遇到猪时进行的操作是B,试想假如还是上面的代码跑的话,我们是不是重复了很多操作,即有很多都是狗,本来我们只需要进行一次A操作即可,而因为现在是单独对每一个样本都进行处理即相当于重复了很多次A操作,所以我们可以这样优化:
首先我们处理特征的函数是Transanimal:
def Transanimal(animal):
if animal=='dog':
return A(animal)
if animal=='pig':
return B(animal)
比如该对应动物列特征的column 名字是animal,我们现在需要的是通过Transanimal转化,新生产一列假如叫做animal_values吧
没有优化前:
import pandas as pd
from sklearn.externals.joblib import Parallel, delayed
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
def youFunc(name,df):
df['animal_values'] = Transanimal(df['animal'])
return df
df = pd.read_csv(inputfile)
df = df.groupby(df.index)
retlist = Parallel(n_jobs=jobNum)(delayed(youFunc)(group) for name, group in tqdm(df))
df = pd.concat(retlist)
优化后
import pandas as pd
from sklearn.externals.joblib import Parallel, delayed
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
def youFunc(name,df):
animal_values = Transanimal(name)
df['animal_values'] = animal_values
return df
df = pd.read_csv(inputfile)
df = df.groupby(df['animal'])
retlist = Parallel(n_jobs=jobNum)(delayed(youFunc)(name,group) for name, group in tqdm(df))
df = pd.concat(retlist)两则对比:
后者对animal分组后,会将很多是同一组的聚集在一次,而这些数据只需要进行一次Transanimal函数即可
假设一共有8组,也就是说进行了8次Transanimal
而没有优化前呢,有多少数据就进行了多少次Transanimal,
极端一点来说,假设所有数据都是狗这一种类,Transanimal处理过程需要1min,现在样本数是10000条
那么优化前需要10000min,优化后1min,当前这样计算时间是不准确的,这里仅仅为了对比一下
Transanimal需要的运行时间越长,组数越小,样本数越多
这种优化带来的效果越明显
-----------------------------------------------------------------------------------------------------------------------------------------
更一般的情况比如说我们处理的数据不是dataframe呢?
怎么构建一个迭代器呢?
这时候可能就要相当python中的yield
假设现在是读一个文件,然后对每一行进行T_T操作
def _read_file(file_name):
while True:
line = file_name.readline()
if not line:
break
yield T_T(line)那么
df = _read_file('animal.txt')那么此时df就是一个迭代器啦,有了这个东西我们就又可以愉快的并行化啦:
retlist = Parallel(n_jobs=jobNum)(delayed(youFunc)(name,group) for name, group in tqdm(df))到这里基本就讲完了,切记使用并行化的前提是顺序不重要,比如dataframe,原始的样本索引是0,1,2,3,4这样的
但处理完后完全有可能变成2,3,0,4,1 所幸的是我们在处理数据尤其是处理特征的时候,我们大多时候是不在乎这样顺序的。