知识融合之dedupe
目录
前言:
几个比较重要的网址
下载安装:
1)dedupe安装:
2)Unidecode安装:
3)future安装:
实践
一 csv_example
1) 数据简介
2) 训练模型
3) 模型评价
4) 模型的保存和加载
二 record_linkage_example
1) 数据简介
2) 训练模型
3) 模型评价
三 patent_example
1) 数据简介
2) 训练模型
3) 模型评价
四 五 六 mysql_example/pgsql_big_dedupe_example/pgsql_example
总结
前言:
dedupe是一个python 包,在知识融合领域有着重要作用!主要就是用来实体匹配
dedupe是一个用于fuzzy matching, record deduplication 和 entity-resolution的python库。它基于active learing的方法,只需用户标注它在计算过程选择的少量数据,即可有效地训练出复合的blocking方法和record间相似性的计算方法,并通过聚类完成匹配。dedupe支持多种灵活的数据类型和自定义类型。
几个比较重要的网址
dedupe 论文:http://www.cs.utexas.edu/~ml/papers/marlin-dissertation-06.pdf
dedupe 源码:https://github.com/dedupeio/dedupe
dedupe demo: https://github.com/dedupeio/dedupe-examples
dedupe 中文网站:http://www.openkg.cn/tool/dedupe
dedupe 官方网站:https://docs.dedupe.io/en/latest/
dedupe API说明:https://dedupe.readthedocs.io/en/latest/API-documentation.html
在使用过程中比较重要的是Variable Definitions的数据类型定义,具体含义,主要就是定义一个字典
https://dedupe.readthedocs.io/en/latest/Variable-definition.html
可选的变量类型有:
String, Exact, Text, Custom, Price, LatLong, DateTime, Set, Exists, Categorical, ShortString,Interaction可选的变量:
Address,Name,Fuzzy Category缺省值
has missing除此之外,其还支持同一个字段使用多种变量类型进行对比以及可以选择使用字符串的条件随机字段距离度量。这个度量可以给你更准确的结果,但是比默认的编辑距离要慢得多。
[
{'field': 'name', 'type': 'String'},
{'field': 'name', 'type': 'Text'}
]{'field': 'name', 'type': 'String', 'crf': True}下面实践中遇到会具体说
下载安装:
其就是一个python包,直接安装dedupe即可,这里为了便于快速开始,我们直接先下载其demo:
git clone https://github.com/dedupeio/dedupe-examples.git然后安装所需的所有依赖包(包括了dedupe)
pip install -r requirements.txt注意:但是由于安装过慢,所以指定一些国内pip安装源比较好,但是这里会有一个问题,因为requirements.txt中其实就3个依赖包
dedupe
Unidecode==0.4.16
future其中一些国内pip安装源网站没有dedupe,如清华的就没有,但是阿里有,另外Unidecode版本要求0.4.16,一时找不到等等会报错(装一个其他相近版本也OK),所以这里就分别手动安装了一下3个包
1)dedupe安装:
下载dedupe包(这里是linux x64,py35,不是的话找到对应环境包下载)
wget http://mirrors.aliyun.com/pypi/packages/79/4a/d70dc62f6efd6c1d440fc4074b6b02eb331c547f63b1531afe43ba3ee7a5/dedupe-1.9.7-cp35-cp35m-manylinux1_x86_64.whl#sha256=83718d408a262c789c1720fd189ab669804b4aba23a2ae20629aedf1c766a681安装
pip install dedupe-1.9.7-cp35-cp35m-manylinux1_x86_64.whl2)Unidecode安装:
下载Unidecode包(这里是linux x64,py35,不是的话找到对应环境包下载)
wget http://mirrors.aliyun.com/pypi/packages/ec/d8/97c4c7ed5ad3cd2511d8896b2973b1f403110e07b38ea310f8703ba8485f/Unidecode-0.04.16.tar.gz#sha256=4cd218737d1a807bbaba9a6534fc3c80d129cff76cf7d7fdbd71e744d836657b解压,安装
tar -xzvf Unidecode-0.04.16.tar.gzcd Unidecode-0.04.16python setup.py install3)future安装:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple future实践
可以在dedupe-examples-master文件夹下看到,这里有多个demo,下面说明其中几个。
一 csv_example
这是一个去重的例子,数据来源于10个不同的芝加哥早期儿童教育网站,
1) 数据简介
原始数据是两个csv文件即:
csv_example_input_with_true_ids.csv : 还有label的训练集
csv_example_messy_input.csv : 训练集首先来直观的看一下csv_example_input_with_true_ids.csv:

其中True Id就是label,即重复数据的True Id是相同的
特征的话主要就是用到了Site name,Address,Zip,Phone
再来看下csv_example_messy_input.csv:

需要注意的是该csv中是没有True Id和Id这两列的,该文件中样本的顺序是按照csv_example_input_with_true_ids.csv中Id的顺序给出的,所以csv_example_messy_input.csv的第一条样本对应的就是csv_example_input_with_true_ids.csv中Id为0的样本,后面评价函数就是这么来应用的
2) 训练模型
直接运行即可
python csv_example.py其是一个Active learning模型,所以在运行的过程中,其会将其不能做出判断的样本打印出来让人工来判断,说白啦就是模型不确定这两条数据是不是重复?,让我们来看看,其中我们可以给出3种结果即y(是重复),n(不是重复),u(不确定)
模型会不断的给出其不能判断的样本对,如果我们想结束可以直接输入f即可
如下是判断的其中2个样本对:
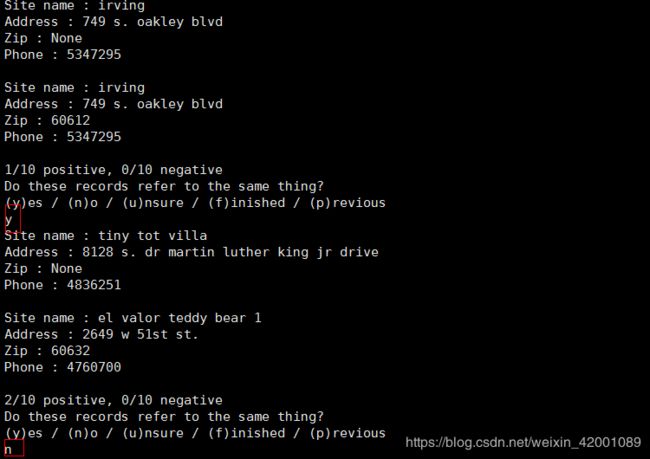
判断了几条,笔者就停止啦,注意这里显示现在已经判断了其中两条,且都判断为正样本对

运行完后会生成csv_example_learned_settings,csv_example_training.json, csv_example_output.csv 这3个文件。
其中 csv_example_output.csv就是预测结果,大概就是:

其中重复数据的Cluster ID号预测相同
###########################下面结合csv_example.py代码进行分析,可以不看##############################
其中有两个函数readData,preProcess很简单其中前者就是读取数据,数据预处理(包括去除引号等等)
接着就是判断settings_file文件是否存在(即结果中的csv_example_learned_settings,其可以简单看出训练好的模型),如果存在的话,就直接加载模型,就不再会进行训练过程啦,否则才会训练。
训练部分首先要定义模型需要注意的字段(特征):这部分很重要
fields = [
{'field' : 'Site name', 'type': 'String'},
{'field' : 'Address', 'type': 'String'},
{'field' : 'Zip', 'type': 'Exact', 'has missing' : True},
{'field' : 'Phone', 'type': 'String', 'has missing' : True},
]
deduper = dedupe.Dedupe(fields)对于String这种类型,模型是采用 affine gap string distance.去对比的
Exact是看两者是否完全一样来判断的
has missing 表示该字段下是否有缺省值的情况
喂入数据,抽样
deduper.sample(data_d, 15000),这里需要注意,模型需要抽取一部分数据进行训练,具体方法是抽取一部分随机样本的记录对,然后从中选择有可能是重复的记录对,当然这里也可以通过参数blocked_proportion设置取样记录对的比例,而不是随机选择的对。默认为0.5即
deduper.sample(data_d, 15000,0.5)接下来是判断是否有已训练的训练数据(即结果中的csv_example_training.json),有的话可以加载,没有就算啦,其实就是相当于:假设我们上次训练了部分数据,这次我们还可以接着上次训练,如果这里想从头训练,那么当前文件夹下不应该有csv_example_training.json文件
接着进行Active learning:
dedupe.consoleLabel(deduper)这里对应的步骤就是模型抛出不确定的样本对让我们判断
最后就是训练啦
deduper.train()训练完后就保存
第一个保存的就是上述说的训练数据
第二个保存的就是谓语和权重,其实就是训练好的模型参数
with open(training_file, 'w') as tf:
deduper.writeTraining(tf)
with open(settings_file, 'wb') as sf:
deduper.writeSettings(sf)接着是判断出最好的阈值:
threshold = deduper.threshold(data_d, recall_weight=1)这里采用了准确率和回归率来综合判断(类似于常说的F1), recall_weight代表的意思看重回归率的程度,当为2时,就是回归率重要程度是准确率的2倍
有了阈值之后,就是聚类啦,将相同的重复数据聚为一类
clustered_dupes = deduper.match(data_d, threshold)
到此就结束啦,后面的代码主要就是将聚类结果写进csv_example_output.csv,有兴趣的可以自行阅读
3) 模型评价
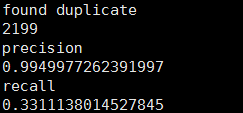
直接运行
python csv_evaluation.py结果:发现2199个重复样本,准确率0.9949977,回归率0.33
#############下面结合csv_evaluation.py代码进行分析看看这些指标具体是怎么定义的,可以不看#####################
这里主要定义了evaluateDuplicates,dupePairs两个函数
dupePairs函数是将同一聚类下所有样本两两组合
假设Cluster ID=4这一类下有样本为2,3,4那么返回的结果就是(2,3),(2,4),(3,4)
def dupePairs(filename, rowname) :
dupe_d = collections.defaultdict(list)
with open(filename) as f:
reader = csv.DictReader(f, delimiter=',', quotechar='"')
for row in reader:
dupe_d[row[rowname]].append(row['Id'])
if 'x' in dupe_d :
del dupe_d['x']
dupe_s = set([])
for (unique_id, cluster) in viewitems(dupe_d) :
if len(cluster) > 1:
for pair in itertools.combinations(cluster, 2):
dupe_s.add(frozenset(pair))
return dupe_s所以先分别加载预测数据和真实数据(csv_example_output.csv、csv_example_input_with_true_ids.csv),然后进行分别组合配对
manual_clusters = 'csv_example_input_with_true_ids.csv'
dedupe_clusters = 'csv_example_output.csv'
true_dupes = dupePairs(manual_clusters, 'True Id')
test_dupes = dupePairs(dedupe_clusters, 'Cluster ID')为了看结果,我们就打印一下看看
print(len(test_dupes))
print(test_dupes)
函数evaluateDuplicates就很简单啦,就是通过计算预测值和真实值(test_dupes,true_dupes)的交集和差集个数进而计算准确率和回归率
def evaluateDuplicates(found_dupes, true_dupes):
true_positives = found_dupes.intersection(true_dupes)
false_positives = found_dupes.difference(true_dupes)
uncovered_dupes = true_dupes.difference(found_dupes)
print('found duplicate')
print(len(found_dupes))
print('precision')
print(1 - len(false_positives) / float(len(found_dupes)))
print('recall')
print(len(true_positives) / float(len(true_dupes)))定义好啦,直接调用就可以输出我们一开始看到的结果啦
evaluateDuplicates(test_dupes, true_dupes)当然啦,可以看到回归率不是很高,可以在人工判断那里多判断几条来提高
4) 模型的保存和加载
这里单独说一下模型的保存和加载,后面实践中不再累述该部分
保存:
with open(settings_file, 'wb') as sf:
deduper.writeSettings(sf)后续使用的话先直接加载
with open(settings_file, 'rb') as f:
deduper = dedupe.StaticDedupe(f)然后直接聚类待处理的数据就可以啦
deduper.match(data_d)二 record_linkage_example
这是一个知识连接的例子,另外一个知识连接的例子是gazetteer_example其使用的是 Gazetteer 接口,这里就通过对第一个例子分析看看怎么做的,如果对gazetteer_example感兴趣可以自行阅读
1) 数据简介
这里首先要说明的是,待连接的两个数据集中每个数据集都不应包含重复的数据集。来自第一个数据集的记录最多且只能匹配来自第二个数据集的一个记录或者不匹配,即要么不匹配要么只能匹配一个,所以如果一个数据集下有重复数据,可以先通过上述的实践一进行去重。
该实践涉及到两个待合并的数据集AbtBuy_Abt.csv,AbtBuy_Buy.csv,数据格式一模一样,都包含四个字段
unique_id title description price

需要说明的是unique_id字段,它的含义是两个样本是不是同一东西的标示,即有可能两个样本的unique_id相同,如:
![]()
那岂不是该数据下有重复数据?是的,我猜应该是这样:毕竟实践一并不能理想化的去除所有重复数据,我们得到的只不过是一个相对来说的不重复数据集而已
来自两个csv表的样本如果其unique_id号相同,那么其属于同一样东西,这算是后面评价函数用到的label。
这里稍微有点疑问就是,“同一样东西”是怎么衡量的?应该不是同一产品的意思,因为unique_id号相同的样本我们可以看到其价钱是有可能是不一样的,所以觉得这里应该指的是同一类产品
![]()
![]()
2) 训练模型
直接运行
python record_linkage_example.py 同“实践一”一样其也是一个Active learning模型,所以在运行的过程中,其会将其不能做出判断的样本打印出来让人工来判断,
这里主要就是判断来自两个表的这一样本对是不是属于同一种知识

################################我是小插曲#####################################################
笔者英文较差,也对这些产品不是很熟悉,所以这里很难做出准确判断,就依照感觉瞎乱判断了几个,也许做了错误选择,所以导致后面评价结果也不是太好,反正流程就是这样,具体应用到自己实际项目中,这里注意一下就OK啦
##################################################################################################
运行完后会生成 data_matching_learned_settings,data_matching_training.json, data_matching_output.csv这3个文件。
具体含义其实和实践一相同
其中 data_matching_output.csv就是预测结果,大概就是这个样子:
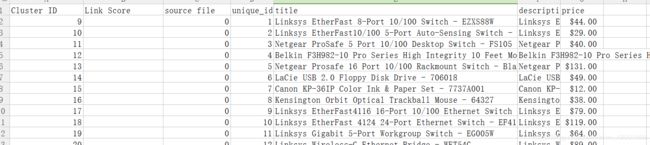
Cluster ID:是否属于同一知识的标示
source file:来源的数据集,如果来源与第一个csv即0,否则1
unique_id:就是原csv中的unique_id
####################下面结合record_linkage_example.py 代码进行分析,可以不看###############################
其实套路和实践一大体一样
两个函数readData,preProcess,不再累述
主要就是看一下fields的定义
fields = [
{'field' : 'title', 'type': 'String'},
{'field' : 'title', 'type': 'Text', 'corpus' : descriptions()},
{'field' : 'description', 'type': 'Text',
'has missing' : True, 'corpus' : descriptions()},
{'field' : 'price', 'type' : 'Price', 'has missing' : True}]这里出现了Text类型的使用,其适用的场景是:比较包含长块文本的字段,例如产品描述或文章摘要,其方法就是使用余弦相似性度量对文本类型字段进行比较。这是两个文件所共有的单词量的度量。由于稀有词的重叠比普通词的重叠更重要,所以这个方法可以更有用。如果提供了一系列的示例字段(即语料库),那么Dedupe将为您学习这些权重,例如这里通过descriptions()函数提供了语料库,其定义如下:
def descriptions() :
for dataset in (data_1, data_2) :
for record in dataset.values() :
yield record['description']可以看到其是一个生成器,即这里所谓的语料库就是使用两个表的description字段下的文本作为语料库
当然也可以不用语料库,即这样也是OK的:
{'field' : 'title', 'type': 'Text'},再者注意:这里是对文本进行余弦相似度计算(https://www.cnblogs.com/airnew/p/9563703.html)
而该方法需要分词(对中文来说需要,英文不存在),所以dedupe的Text类型是否能够处理中文?,因为当前没有相关中文数据集这里也没试过,如果不能可以考虑做一步预处理即先将中文句子进行分词,还有一个解决的思路就是:dedupe允许自定义比较器即这里通过Custom自定义了sameOrNotComparator比较器
def sameOrNotComparator(field_1, field_2) :
if field_1 and field_2 :
if field_1 == field_2 :
return 0
else:
return 1
{
'field': 'Zip',
'type': 'Custom',
'comparator': sameOrNotComparator
}
所以我们可以自定义一个中文余弦相似度比较器(就是一个python函数)
具体该函数怎么写,那就是先用分词工具分词然后调用余弦相似度函数,该函数可参考
https://www.cnblogs.com/airnew/p/9563703.html
至于语料库,对应到这里其实就是在分词过程中用到的分词工具,需要重新训练用到语料库
这里还出现了Price类型,其主要处理价格这种数据,即正的、非零的数字,注意值必须为正浮点类型,如果值为0或负数,则会引发异常。
除此之外我们还可以看到title字段通过不同的方式被使用了两次!!!
实践一的目的是去重使用的接口是
deduper = dedupe.Dedupe(fields)这里对应使用的是
linker = dedupe.RecordLink(fields)接下来大部分都是相同的套路啦,即抽样,训练,聚类啥的,这里不再重复说了
3) 模型评价
直接运行
python record_linkage_example_evaluation.py 结果:
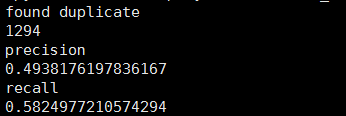
这里的1294的意思两个表有1294个样本属于同一知识
#########下面结合record_linkage_example_evaluation.py 代码进行分析看看这些指标具体是怎么定义的#############
设计到两个linkPairs,evaluateDuplicates
其中evaluateDuplicates和实践一相同
linkPairs其实做的工作和实践一类似即将同一聚类下所有样本两两组合
我们知道data_matching_output.csv表格中unique_id是真实标签,Cluster ID是预测标签,那么就依据这两2列对其下的样本两两组合
def linkPairs(filename, rowname) :
link_d = {}
with open(filename) as f:
reader = csv.DictReader(f, delimiter=',', quotechar='"')
for i, row in enumerate(reader):
source_file, link_id = row['source file'], row[rowname]
if link_id:
if link_id not in link_d:
link_d[link_id] = collections.defaultdict(list)
link_d[link_id][source_file].append(i)
link_s = set()
for members in link_d.values():
for pair in itertools.product(*members.values()):
link_s.add(frozenset(pair))
return link_s
clusters = 'data_matching_output.csv'
true_dupes = linkPairs(clusters, 'unique_id')
test_dupes = linkPairs(clusters, 'Cluster ID')最后计算准确率,回归率
evaluateDuplicates(test_dupes, true_dupes)三 patent_example
这是一个消除歧义的例子,用到的是一个专利记录的数据集
1) 数据简介
这里有两个csv表格patstat_input.csv,patstat_reference.csv
其中patstat_input.csv有如下字段
person_id Lat Lng Coauthor Name Class
person_id : 表示人的id
Lat Lng : 发明者的地址(经纬度)
Coauthor :合著者,以**分隔开来
Name : 发明人名字
Class : 分配给该发明人的专利上的4位数ipc技术代码,以**分隔开来

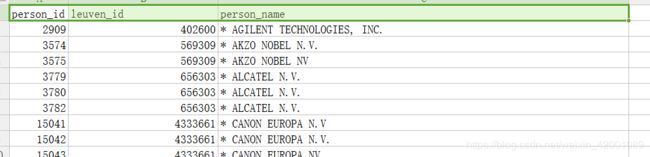
其中patstat_reference.csv有如下字段
person_id leuven_id person_name
其中leuven_id是人物关系组id,说的直白点就是如果person_id的leuven_id相同那么就是一类,这其实就是label,后面评价的时候用到
2) 训练模型
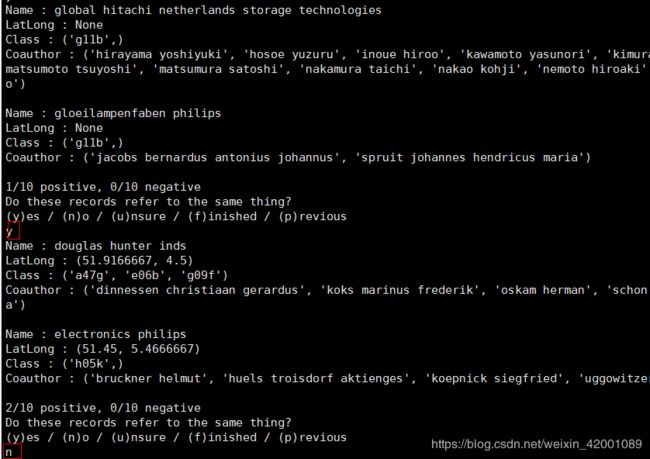
直接运行
python patent_example.py同“实践一”一样其也是一个Active learning模型,所以在运行的过程中,其会将其不能做出判断的样本打印出来让人工来判断,
运行结果同样生成了3个文件patstat_settings.json,patstat_training.json,patstat_output.csv
其中patstat_output.csv就是消除歧义结果文件:

##############################下面结合patent_example.py 代码进行分析###############################
套路还是那个套路,老规矩,看不同处
fields = [
{'field' : 'Name',
'variable name' : 'Name',
'type': 'String',
'has missing' : True},
{'field' : 'LatLong',
'type' : 'LatLong',
'has missing' : True},
{'field' : 'Class',
'variable name' : 'Class',
'type': 'Set',
'corpus' : classes(data_d),
'has missing' : True},
{'field' : 'Coauthor',
'variable name' : 'Coauthor',
'type': 'Set',
'corpus' : coauthors(data_d),
'has missing' : True},
{'field' : 'Name',
'variable name' : 'Name Text',
'type' : 'Text',
'corpus' : names(data_d),
'has missing' : True},
{'type' : 'Interaction',
'interaction variables' : ['Name', 'Name Text']}
]这里首先出现了variable name,这就是个简单的字段标示,用来定位当前字段的
LatLong类型,这是专门用来进行经纬度比较的类型,其具体方法是用了 Haversine Formula.,latlong类型字段必须由与纬度和经度相对应的浮点元组组成(这在预处理阶段已经做好了,可以具体看代码中的readData函数)
Set类型, 其是用于比较元素列表的,如关键字或客户端名称。集合类型与文本类型非常相似。他们使用相同的比较函数,所以可以通过提供语料库来了解哪些术语是常见的或罕见的。在记录中,集合类型字段必须是可解的序列,如 tuples 或者frozensets.类型,同理不提供语料库也是可以滴,这里在合著者列表和专利号序列两个字段都使用了这种类型,并使用了语料库,各自的语料库就是两个生成器
def classes(data) :
for record in viewvalues(data) :
yield record['Class']
def coauthors(data) :
for record in viewvalues(data) :
yield record['Coauthor']Interaction类型,这是一个交互字段,其将多个变量的值相乘。交互变量字段必须是在变量定义中定义的其他字段的变量名序列。当两个预测因子的作用不是简单的加性时,相互作用是好的,这里可以看到将['Name', 'Name Text']当做了交互字段
这里还是使用了同实践一相同的接口:
deduper = dedupe.Dedupe(fields, num_cores=2)其他的一些基本都相同,且比较简单,有兴趣自行阅读即可
3) 模型评价
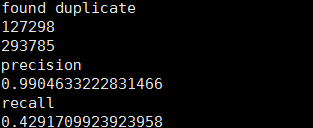
直接运行
python patent_evaluation.py结果
#########下面结合record_linkage_example_evaluation.py 代码进行分析看看这些指标具体是怎么定义的#############
套路一模一样,就是将同一聚类下所有样本两两组合,预测标签个真实标签分别是:
patstat_output.csv下的Cluster ID
patstat_reference.csv下的leuven_id
所以首先加载数据集,然后两两组合
def dupePairs(filename, colname) :
dupe_d = collections.defaultdict(list)
with open(filename) as f:
reader = csv.DictReader(f, delimiter=',', quotechar='"')
for row in reader:
dupe_d[row[colname]].append(row['person_id'])
if 'x' in dupe_d :
del dupe_d['x']
dupe_s = set([])
for (unique_id, cluster) in dupe_d.items():
if len(cluster) > 1:
for pair in itertools.combinations(cluster, 2):
dupe_s.add(frozenset(pair))
return dupe_s
dedupe_clusters = 'patstat_output.csv'
manual_clusters = 'patstat_reference.csv'
test_dupes = dupePairs(dedupe_clusters, 'Cluster ID')
true_dupes = dupePairs(manual_clusters, 'leuven_id')最后计算准确率和回归率
evaluateDuplicates(test_dupes, true_dupes)四 五 六 mysql_example/pgsql_big_dedupe_example/pgsql_example
该部分实践没有什么大的难点,核心东西没有变,主要就是讲了一下怎么结合数据库
相应demo文件夹下面基本都有两个python 文件,
一个是类似mysql_init_db文件,即初始化数据库,然后下载相应数据写入
一个是类似mysql_example.py即对于实践一的csv_example.py
里面的代码套路还是一模一样,只不过将读取处理csv表格的readData,preProcess函数换成了连接,读取数据库,原先生成的结果csv文件,现在是将结果写进数据库
除此之外都没有边,这里就不再累述啦,感兴趣的自行阅读
运行流程就是先运行第一个文件初始化
然后再运行第二个即可
总结
1)其实不论dedupe做的哪个实践,其实本质上都是“去重”,其核心方法就是通过各种数据类型(fields中的数据类型)来对样本进行比较计算相似度,然后通过聚类,进而达到将重复的数据(叫做同一类也好)聚集到同一类下,最终实现去重的目的,可以将这一思想应用的各个方面,类如包括连接两个表,专利消除歧义等等吧
2) Active learning阶段人工判断部分至少要做出一对结果的判断,即不能一开始就f,再者该部分对最终模型训练的好坏影响至关重要,多判断几条和少判断几条对于结果的准确率和回归率有很大的影响(笔者做过实验)