Centos7虚拟机 搭建 Hadoop3.1.1 教程
本次测试所用软件及环境
- Centos7
- jdk 8
- Vmware 12 pro
- hadoop 3.1.1
1、下载Hadoop
2、安装3个虚拟机实现ssh面密码登陆
2.1 安装3个虚拟机
这里使用的Linux系统是Centos7
安装三个机器,如图所示:

(我们操作时使用root用户)
使用ifconfig命令查看3台机器的ip
1)如果没有ifconfig命令可以使用ip addr命令
2) 如果查看ip的时候只显示127.0.0.1,则参考以下教程
https://blog.csdn.net/kai666ling/article/details/80361424
本次虚拟机的机器名和ip号对应为
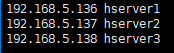
2.2 设置机器名称
为了方便使用,必须正确设置机器名称和ip对应,使用 hostname 命令,查看机器名称
![]()
观察是不是自己想要设置的机器名称,如果不是则使用 hostname (你的机器名)
例应为: hostname hserver1
再使用hostname命令,观察是否更改
类似的,更改其他两台机器hserver2和hserver3
2.3 配置/etc/hosts文件
修改3台机器的/etc/hosts文件,向文件中添加以下内容
192.168.5.136 hserver1
192.168.5.137 hserver2
192.168.5.138 hserver3IP号为自己机器名对应的IP
2.4 给三台机器生成密钥文件
使用命令 ssh-keygen -t rsa -P ''
再次单击回车出现类似内容
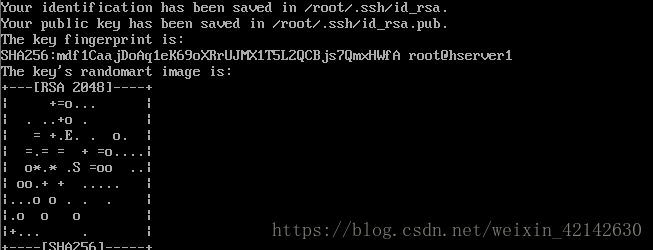
因为是root用户,密钥文件保存到了/root/.ssh/目录下,可以使用命令查看:
ls /root/.ssh/
该目录下生成两个文件文件 id_rsa 和 id_rsa.pub
2.5 在hserver1上创建authorized_keys文件
接下来将3台机器的/root/.ssh/目录下都存入一个相同文件,文件名authorized_keys,内容为刚刚生成的密钥。
- 使用命令 touch /root/.ssh/authorized_keys 生成文件
- 使用命令 ls /root/.ssh/ 查看是否生成文件
- 使用命令 vi authorized_keys 并将三个主机中的/root/.ssh/id_rsa.pub内容复制ji进去
我的 authorized_keys文件显示为
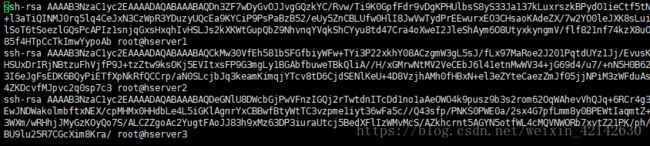
最后保存后,将hserver1中的authorized_keys文件复制到hserver2,hserver3
可以使用 xftp 工具
2.6 在hserver1上进行测试
输入命令 ssh hserver2
键入 y 后,显示如下内容则证明ssh成功

输入命令 exit 退出 ssh 远程连接
再键入 ssh hserver3
最后在server2、hserver3上进行同样的测试,保证三台机器之间可以免密登陆
3 安装Java和Hadoop
3.1 安装jdk
参考:https://www.cnblogs.com/sxdcgaq8080/p/7492426.html
3.2 安装hadoop
在opt下新建hadoop文件,并将hadoop-3.1.1.tar.gz放入
进入该目录 cd /opt/hadoop
解压该文件 tar -zxvf hadoop-3.1.1.tar.gz
注:三台机器都需要进行上述操作
![]()
3.2 修改etc/hadoop中的配置文件
注:除了个别提示,其余文件只用修改hserver1中的即可
1 修改core-site.xml
文件最后
fs.defaultFS
hdfs://hserver1:9000
hadoop.tmp.dir
/opt/hadoop/hadoop-3.1.1/data/tmp
3.2.2 修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME= 你jdk的安装路径
以下为我的设置 ![]()
该文件的配置需要三台机器都配置
3.2.3 修改hdfs-site.xml
文件最后
dfs.namenode.http-address
hserver1:50070
dfs.namenode.name.dir
/hadoop/name
dfs.replication
2
dfs.datanode.data.dir
/hadoop/data
3.2.4 修改mapred-site.xml
文件最后
mapreduce.framework.name
yarn
3.2.5 修改 workers
全部删除后加入之前设置的主机名或者ip
hserver1
hserver2
hserver3
3.2.6 修改yarn-site.xml文件
文件最后
yarn.resourcemanager.hostname
hserver1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.cpu-vcores
1
4 启动Hadoop
4.1 在namenode上初始化
因为hserver1是namenode,hserver2和hserver3都是datanode,所以只需要对hserver1进行初始化操作,也就是对hdfs进行格式化。
在hserver1中进入 /opt/hadoop/hadoop-3.1.1/bin 执行 cd /opt/hadoop/hadoop-3.1.1/bin
执行初始化脚本,也就是执行命令:./hdfs namenode -format
等待一会后,不报错返回 “Exiting with status 0” 为成功,“Exiting with status 1”为失败
4.2在namenode上执行启动命令
进入hserver中的/opt/hadoop/hadoop-3.1.1/sbin 执行cd /opt/hadoop/hadoop-3.1.1/sbin
直接执行./start-all.sh 观察是否报错,如报错执行一下内容
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在空白位置加入
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh
在空白位置加入
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
$ vim start-all.sh
$ vim stop-all.sh
TANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置完毕后执行./start-all.sh
4.3 查看Hadoop进程
输入命令 jps
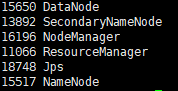
如果出现6个进程则为配置正确
输入http://192.168.5.136:50070 则可以看到
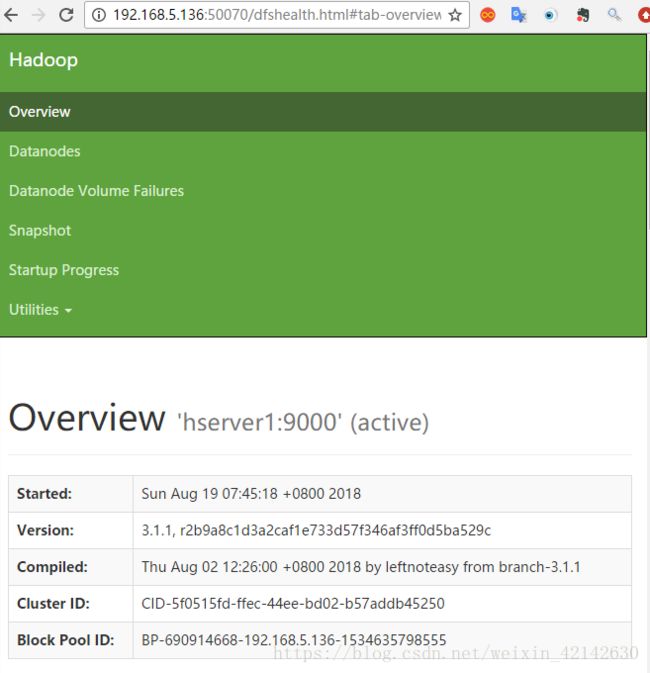
即配置成功