【论文阅读】Three scenarios for continual learning
文章目录
- 题目:2019_Three scenarios for continual learning
- 1. 论文的总体介绍
- 2. 论文提出的 benchmark: 三种场景
- 2.1. 三种场景的定义如下:
- 2.2. split task protocols 下的三种场景
- 2.3. permuted task protocols 下的三种场景
- 3. CL策略/方法/算法
- 4. 实验设计
- 4.1 任务 protocols 定义(即三个场景的数据集准备)
- 4.2 对算法的相关设置(之后会根据论文给出更加具体的说明)
- 完
题目:2019_Three scenarios for continual learning
1. 论文的总体介绍
论文链接:https://arxiv.org/abs/1904.07734
代码链接:https://github.com/GMvandeVen/continual-learning
论文的动机:针对当前 CL(continual learning) 领域,因为不同的人提出了不同的解决方案,这些方法都不是在同一个benchmark 下进行比较的,无法公平地比较各种方法的优劣,所以作者提出了一种新的 benchmark 用于评估 CL 方案的性能。
论文的方案:这个 benchmark 包含三种场景,每种场景包含两种任务协议(protocols)。
这三种场景可以组成任意复杂的任务。
这三个场景是通过定义两个判断点(是否提供任务 id 和 是否需要推断任务 id )来确定的:
1.测试时,如果提供任务id,就定义为场景1.
2.测试时,如果不提供任务id,且不需要推断出任务id,就定义为场景2.
3.测试时,如果不提供任务id,且需要推断出任务id,就定义为场景3.
两种任务协议(protocols):
1. split task protocols。
2. permuted task protocols。
论文的贡献:
- 提出了一个 benchmark 。
- 在这个 benchmark 下,对比了几个 CL 方案。
论文的结论:在场景3中, 基于正则化方法(regularization-based approaches)的效果不好,基于数据经验重放方法(replay-based approaches)的效果较好。
2. 论文提出的 benchmark: 三种场景
2.1. 三种场景的定义如下:

说明如下:
| 场景 | 测试时的要求 | 特点 | |
|---|---|---|---|
| 场景1 | Task-IL(incremental learning) | 提供任务 id | 该场景下的网络结构通常有一个 “multi-head” output layer,即每个任务都有一个 own output units,网络的其他部分是共享的。 |
| 场景2 | Domain-IL | 不提供任务 id,不需要推断出任务 id | 这种场景通常是不同任务之间的结构是相同的,但是不同任务中的“输入分布”却改变了。 |
| 场景3 | Class-IL | 不提供任务 id,需要推断出任务 id | 、、 |
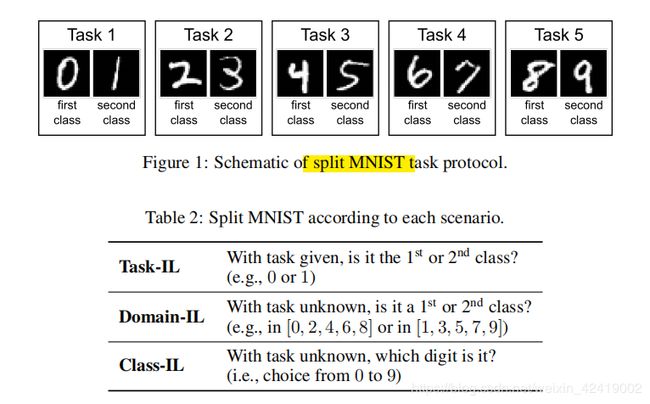
2.2. split task protocols 下的三种场景
MNIST 数据集一共有10个数字,每个任务分2个类别的数据。训练时会先后提供这个5个任务的数据给网络训练。测试时在三种场景下测试。
1.场景1,提供任务id之后。给一个数据和数据所属的任务id,然后判断的这个数据是给定任务id中的第一类或第二类。
2.场景2,不提供任务id,不需要推断出任务id。给一个数据,不提供数据所属的任务id,然后判断这个数据是第几类。
3.场景3,不提供任务id,需要推断出任务id。给一个数据,不提供数据所属的任务id,然后判断这个数据具体是哪一个任务的第几类。
2.3. permuted task protocols 下的三种场景
理解了 split 任务就能很容易的理解 permuted 任务了。permuted task protocols 是在 split task protocols 的基础上,将任务数从5扩展到了10,同时将每个任务的类别从2扩展到了10,其中 permutation 2 到10 的9个任务的数据是由 permutation 1 中的数据根据9种随机乱序方式构建的。

3. CL策略/方法/算法
作者将现有的CL策略分成了四个大类,分别是:
| 序号 | 类别 | 代表算法 | 算法思想 | 算法优点 | 算法缺点 |
|---|---|---|---|---|---|
| 1 | Task-specific Components | XdG、 | 任务 id 给定型:新增加一个任务时,就为网络添加个一个针对该任务的结构(Task-specific Components),训练时不是训练整个网络,而是只训练网络的部分结构。 | 因为这个算法需要提供任务 id 来确定 Task-specific Components,所以这类算法只适用于场景1 | |
| 2 | Regularized Optimization | EWC、Online EWC、SI | 正则优化型:学习新任务时,要根据当前所有参数对之前任务的重要性来更新参数。对之前任务越重要的参数越要减小更新。任务id 不提供时,为每一个任务训练网络的不同部分。 | 每一个任务都是在前面任务的基础上对网络进行优化的,最终的解不是全局最优解。 | |
| 3 | Modifying Training Data | LwF、DGR、DGR+distill | 数据重放型:除了主网络模型之外,还需要一个网络用于实现数据的重放,通常是使用GAN中的生成器来实现,这里称之为 Deep Generative Replay(DGR)。同时也就可以和知识蒸馏(distill)相结合,这样就称之为 ”DGR+distill“ | 1.数据重放,涉及隐私问题。 2.多次数据重放后存在数据偏移问题 | |
| 4 | Using Exemplars | iCaRL | 样例保存型: 算法需要保存一些典型的样例,用于实现CL学习。通过一个特征提取网络提取不同类别数据的特征,再使用 nearest-class-mean rule 来实现分类。 | 存储了样例,违反了CL的定义 |
4. 实验设计
在三种场景,2个任务 protocols 上测试不同算法的表现结果。
4.1 任务 protocols 定义(即三个场景的数据集准备)
论文只使用了MNIST数据集进行实验,设置的需要连续学习的任务数量最多是10,所以之后的其他论文添加了其他的数据集,用于评估算法在长序列任务下的学习能力。
| task protocols | 任务数量 | 每个任务中的类别数 | 图片大小 | 说明 |
|---|---|---|---|---|
| split MNIST | 5 | 2 | 28x28 pixel grey-scale images | 总共 10 类数字,每个类别有 6000个图片用于训练,1000个用于测试。 |
| permuted MNIST | 10 | 10 | zero-padded to 32x32 pixels | 总共 100 类数字,每个类别有 6000个图片用于训练,1000个用于测试。 |
4.2 对算法的相关设置(之后会根据论文给出更加具体的说明)
为了公平比较,所有方法都使用相同的神经网络架构。split MNIST 使用2个隐藏层实现,每层 400节点。permuted MNIST 使用2个隐藏层实现,每层 1000节点。激活函数使用 ReLU,除了iCaRL,最后一层是softmax输出层。
在场景1中,所有的方法都使用 multi-headed output layer 实现,即每个任务都有一个指定的输出单元,只有需要适应当前任务id对应的输出单元时,该单元才会被使用到,其他情况下(训练或测试),该单元都不会处于不被使用的状态。
在场景2中,所有的方法都使用 single-headed output layer 实现,即所有的任务都通过这一个单头输出层实现。训练不同的任务时,这个单头会一直处于工作状态(一直被使用)。单头输出层的每个单元(输出)对应任务中的一个类别。
在场景3中,每个类别都有其自己的输出单元,当前任务前的所有单元都应该一直处于激活状态。
| 序号 | 算法名称 | 算法设置 | 算法特点 | |
|---|---|---|---|---|
| 1 | XdG | 因为这个算法测试时,必须要使用到任务id , 所以只适用于 场景1 | ||
| 2 | EWC / Online EWC / SI: | |||
| 3 | LwF / DGR / DGR+distill | |||
| 4 | iCaRL |
后续将仔细分析这四类算法中的每一个算法。除了这四个算法之外,还需要引入两个算法用于对比:
1.None(fine-tuning): 即不采取任何策略,只使用当前数据集来训练当前任务。这个作为 a lower bound(算法下界)。
2.Offline(joint training): 即使用之前所有的数据集一起来训练当前任务。这个作为 an upper bound(算法上界)