【知识图谱】神经网络综述
概述
近年来随着计算机硬件的发展,神经网络作为机器学习中不可获取的一部分在预测、分类、图像分割、识别等方向得到了极其广的应用,然而其网络模型多,数学基础涉及广,使得其门槛较高。好在目前有诸如tensorflow、pytorch、sklearn等工具、拓展包的存在令各领域人员将更多的精力放在如何应用网络模型解决实际业务问题。然而虽不需要人工智能科学家那样扎实功底具备模型优化能力,仍需对整个神经网络有较直观的知识框架方能知道网络如何结合实际业务,调参也得知道各个参数大致什么意思有什么用,针对实际问题有哪些网络可以值得选择,当前这方面的研究进展才能了解其意义所在。
神经网络长什么样
人工神经网络(artificial neural network,缩写ANN),简称神经网络(neural network,缩写NN)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
神经网络主要由:输入层,隐藏层,输出层构成。当隐藏层只有一层时,该网络为两层神经网络,由于输入层未做任何变换,可以不看做单独的一层。实际中,网络输入层的每个神经元代表了一个特征,输出层个数代表了分类标签的个数(在做二分类时,如果采用sigmoid分类器,输出层的神经元个数为1个;如果采用softmax分类器,输出层神经元个数为2个),而隐藏层层数以及隐藏层神经元是由人工设定。一个基本的三层神经网络可见下图:
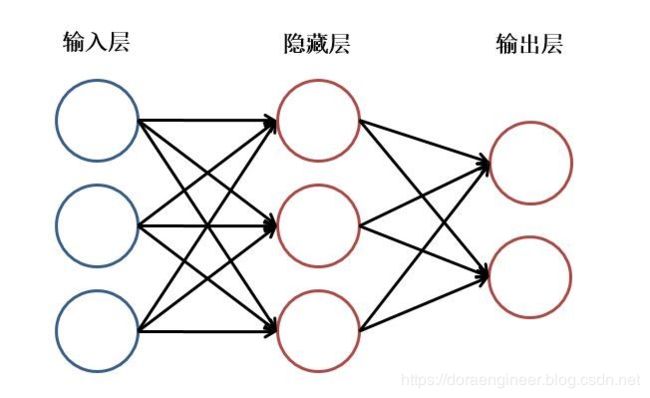
神经网络本质
在Michael Nielsen大神的著作 Neural Networks and Deep Learning的chapter 4: A visual proof that neural nets can compute any function,他论证了在通用逼近理论(universal approximation theorem)的作用下,只要神经网络足够大(隐层神经元足够多),它可以逼近任意函数(can compute any function)。
机器学习,实际上是寻找一种数学模型,让这个模型符合它所要描述的对象。比如说我们要寻找一个能区分出Figure 1中蓝色和橙色点的模型,用它可以区分现有的以及未来可能新增的点,这个数学模型就是图中的白线,即ax + b = y,只要计算出a和b,就可以用函数ax + b来解决Figure 1的分类问题。
理论上说,神经网络可以逼近任意函数,即找到解决任何难题对应的数学模型,而且隐层的神经元数越多就越逼近目标函数。
神经网络特点
1.并行分布式处理 神经网络具有高度的并行结构和并行实现能力,具有高速寻找优化解的能力,能够发挥计算机的高速运算能力,可能很快找到优化解。
2.非线性处理 人脑的思维是非线性的,故神经网络模拟人的思维也应是非线性的。这一特性有助于处理非线性问题。
3.具有自学习功能 通过对过去的历史数据的学习,训练出一个具有归纳全部数据的特定的神经网络,自学习功能对于预测有特别重要的意义。
4.神经网络的硬件实现 要使人工神经网络更快、更有效地解决更大规模的问题,关键在于其超大规模集成电路(V LSI)硬件的实现,即把神经元和连接制作在一块芯片上(多为CMOS)构成ANN,神经网络的VLSI设计方法近年来发展很快,硬件实现已成为ANN的一个重要分支。
神经网络领域
近些年来神经网络在众多领域得到了广泛的运用。在民用应用领域的应用,如语言识别、图像识别与理解、计算机视觉、智能机器人故障检测、实时语言翻译、企业管理、市场分析、决策优化、物资调运、自适应控制、专家系统、智能接口、神经生理学、心理学和认知科学研究等等;在军用应用领域的应用,如雷达、声纳的多目标识别与跟踪,战场管理和决策支持系统,军用机器人控制各种情况、信息的快速录取、分类与查询,导弹的智能引导,保密通信,航天器的姿态控制等。
基本概念
了解神经网络就要了解与神经网络相关的一些概念,才能看懂相关的论文。
-
神经元
神经元就是当h大于0时输出1,h小于0时输出0这么一个模型,它的实质就是把特征空间一切两半,认为两瓣分别属两个类。这个模型有点像人脑中的神经元:从多个感受器接受电信号 ,进行处理(加权相加再偏移一点,即判断输入是否在某条直线 的一侧),发出电信号(在正确的那侧发出1,否则不发信号,可以认为是发出0),这就是它叫神经元的原因。 -
容量、过拟合、欠拟合
-
泛化
机器学习的主要挑战是我们的算法必须能够在先前未观测的新输入上表现良好,而不只是在训练集上表现良好。在先前未观测到的输入上表现良好的能力被称为泛化(generalization)。 -
容量
通过调整模型的容量(capacity),我们可以控制模型是否偏向于过拟合或者欠拟合。通俗地,模型的容量是指其拟合各种函数的能力。 容量低的模型可能很难拟合训练集。 容量高的模型可能会过拟合,因为记住了不适用于测试集的训练集性质。 -
过拟合
过拟合是指训练误差和和测试误差之间的差距太大。 -
欠拟合
欠拟合是指模型不能在训练集上获得足够低的误差。
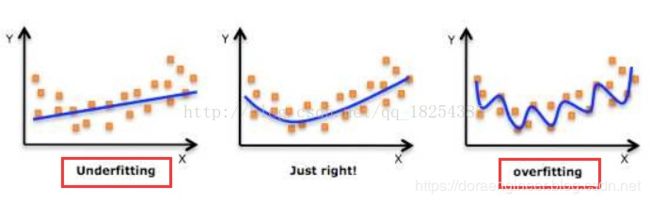
-
正则化
-
超参数
大多数机器学习算法都有超参数,可以设置来控制算法行为。超参数的值不是通过学习算法本身学习出来的(尽管我们可以设计一个嵌套的学习过程,一个学习算法为另一个学习算法学出最优超参数)。 -
参数范数惩罚
许多正则化方法通过对目标函数 J 添加一个参数范数惩罚 Ω(θ), 限制模型(如神经网络、 线性回归或逻辑回归)的学习能力。 当我们的训练算法最小化正则化后的目标函数 J~ 时,它会降低原始目标 J 关于训练数据的误差并同时减小在某些衡量标准下参数 θ(或参数子集)的规模。选择不同的参数范数 Ω 会偏好不同的解。 -
bagging
Bagging(bootstrap aggregating)是通过结合几个模型降低泛化误差的技术(Breiman, 1994)。主要想法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。这是机器学习中常规策略的一个例子,被称为模型平均(modelaveraging)。采用这种策略的技术被称为集成方法。 -
dropout
Dropout (Srivastava et al., 2014) 提供了正则化一大类模型的方法,计算方便但功能强大。在第一种近似下,Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。 -
优化
-
病态
在优化凸函数时,会遇到一些挑战。这其中最突出的是 Hessian 矩阵 H 的病态。这是数值优化、 凸优化或其他形式的优化中普遍存在的问题 病态问题一般被认为存在于神经网络训练过程中。 病态体现在随机梯度下降会‘‘卡’’ 在某些情况,此时即使很小的更新步长也会增加代价函数。 -
局部极小值
对于非凸函数时,如神经网络,有可能会存在多个局部极小值。事实上,几乎所有的深度模型基本上都会有非常多的局部极小值。 -
模型可辨认性
如果一个足够大的训练集可以唯一确定一组模型参数,那么该模型被称为可辨认的。带有潜变量的模型通常是不可
辨认的,因为通过相互交换潜变量我们能得到等价的模型。 -
悬崖
多层神经网络通常存在像悬崖一样的斜率较大区域,如图 8.3 所示。这是由于几个较大的权重相乘导致的。遇到斜率极大的悬崖结构时,梯度更新会很大程度地改变参数值,通常会完全跳过这类悬崖结构。 悬崖结构在循环神经网络的代价函数中很常见,因为这类模型会涉及到多个因子的相乘,其中每个因子对应一个时间步。因此,长期时间序列会产生大量相乘。 -
长期依赖
由于变深的结构使模型丧失了学习到先前信息的能力,让优化变得极其困难。深层的计算图不仅存在于前馈网络,还存在于之后介绍的循环网络中(在第十章中描述)。因为循环网络要在很长时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,这使问题更加凸显。 -
梯度消失与梯度爆炸
梯度消失与爆炸问题(vanishing and exploding gradient problem)是指该计算图上的梯度也会因为 diag(λ)t 大幅度变化。 梯度消失使得我们难以知道参数朝哪个方向移动能够改进代价函数,而梯度爆炸会使得学习不稳定。之前描述的促使我们使用梯度截断的悬崖结构便是梯度爆炸现象的一个例子。 -
自适应学习率
-
激活函数
在神经网络中,网络解决问题的能力与效率除了与网络结构有关外,在很大程度上取决于网络所采用的激活函数。激活函数的选择对网络的收敛速度有较大的影响,针对不同的实际问题,激活函数的选择也应不同。
1.阈值函数
该函数通常也称为阶跃函数。当激活函数采用阶跃函数时,人工神经元模型即为MP模型。此时神经元的输出取1或0,反应了神经元的兴奋或抑制。
2.线性函数
函数可以在输出结果为任意值时作为输出神经元的激活函数,但是当网络复杂时,线性激活函数大大降低网络的收敛性,故一般较少采用。
3.对数S形函数
对数S形函数的输出介于0~1之间,常被要求为输出在0~1范围的信号选用。它是神经元中使用最为广泛的激活函数。
4.双曲正切S形函数
双曲正切S形函数类似于被平滑的阶跃函数,形状与对数S形函数相同,以原点对称,其输出介于-11之间,常常被要求为输出在-11范围的信号选用。
当前较成熟的两类神经网络
卷积神经网络
卷积网络(CNN)是一类尤其适合计算机视觉应用的神经网络,因为它们能使用局部操作对表征进行分层抽象。有两大关键的设计思想推动了卷积架构在计算机视觉领域的成功。第一,CNN 利用了图像的 2D 结构,并且相邻区域内的像素通常是高度相关的。因此,CNN 就无需使用所有像素单元之间的一对一连接(大多数神经网络都会这么做),而可以使用分组的局部连接。第二,CNN 架构依赖于特征共享,因此每个通道(即输出特征图)是在所有位置使用同一个过滤器进行卷积而生成的。
-
卷积层
多层网络通常是高度非线性的,而整流(rectification)则通常是将非线性引入模型的第一个处理阶段。整流是指将点方面的非线性(也被称为激活函数)应用到卷积层的输出上。这一术语借用自信号处理领域,其中整流是指将交流变成直流。这也是一个能从生物学和理论两方面都找到起因的处理步骤。计算神经科学家引入整流步骤的目的是寻找能最好地解释当前神经科学数据的合适模型。另一方面,机器学习研究者使用整流的目的是为了让模型能更快和更好地学习。有趣的是,这两个方面的研究者往往都认同这一点:他们不仅需要整流,而且还会殊途同归到同一种整流上。 -
整流
多层网络通常是高度非线性的,而整流(rectification)则通常是将非线性引入模型的第一个处理阶段。整流是指将点方面的非线性(也被称为激活函数)应用到卷积层的输出上。 -
归一化
这些网络中存在级联的非线性运算,所以多层架构是高度非线性的。除了前一节讨论的整流非线性,归一化(normalization)是 CNN 架构中有重要作用的又一种非线性处理模块。 -
池化
池化运算的目标是为位置和尺寸的改变带来一定程度的不变性以及在特征图内部和跨特征图聚合响应。使用最广泛的两种池化函数分别是平均池化和最大池化。
循环神经网络
- 循环神经网络(recurrent neural network)或 RNN (Rumelhart et al., 1986c)是一类用于处理序列数据的神经网络。就像卷积网络是专门用于处理网格化数据X(如一个图像)的神经网络, 循环神经网络是专门用于处理序列 x(1); : : : ; x(τ ) 的神经网络。正如卷积网络可以很容易地扩展到具有很大宽度和高度的图像,以及处理大小可变的图像, 循环网络可以扩展到更长的序列(比不基于序列的特化网络长得多)。大多数循环网络也能处理可变长度的序列。
- 计算图
计算图是形式化一组计算结构的方式,如那些涉及将输入和参数映射到输出和损失的计算。 - 双向RNN
在许多应用中,我们要输出的 y(t) 的预测可能依赖于整个输入序列。例如,在语音识别中,由于协同发音,当前声音作为音素的正确解释可能取决于未来几个音素,甚至潜在的可能取决于未来的几个词,因为词与附近的词之间的存在语义依赖:如果当前的词有两种声学上合理的解释,我们可能要在更远的未来(和过去)寻找信息区分它们。
双向RNN结合时间上从序列起点开始移动的RNN和另一个时间上从序列末尾开始移动的RNN。图10.11展示了典型的双向RNN,其中 h(t) 代表通过时间向前移动的子RNN的状态,g(t)代表通过时间向后移动的子 RNN 的状态。这允许输出单元o(t)能够计算同时依赖于过去和未来且对时刻t的输入值最敏感的表示,而不必指定t周围固定大小的窗口(这是前馈网络、 卷积网络或具有固定大小的先行缓存器的规RNN所必须要做的)。
其他较为出名的网络模型
| 模型 | 时间 | 概述 | 略图 |
|---|---|---|---|
| M-P神经网络模型 | 1943 | 在模型中,通过把神经元看作个功能逻辑器件来实现算法,从此开创了神经网络模型的理论研究。 | |
| Hebb规则 | 1949 | 提出了突触连接强度可变的假设。这个假设认为学习过程最终发生在神经元之间的突触部位,突触的连接强度随之突触前后神经元的活动而变化。这一假设发展成为后来神经网络中非常著名的Hebb规则。这一法则告诉人们,神经元之间突触的联系强度是可变的,这种可变性是学习和记忆的基础。 | |
| 感知器模型(P) | 1957 | 感知器模型具有现代神经网络的基本原则,并且它的结构非常符合神经生理学。这是一个具有连续可调权值矢量的MP神经网络模型,经过训练可以达到对一定的输入矢量模式进行分类和识别的目的,它虽然比较简单,却是第一个真正意义上的神经网络。 |  |
| 前馈神经网络(FF或FFNN) | 20世纪60年代 | 它的工作原理通常遵循以下规则:1.所有节点都完全连接2.激活从输入层流向输出,无回环3.输入和输出之间有一层(隐含层)在大多数情况下,这种类型的网络使用反向传播方法进行训练。 | 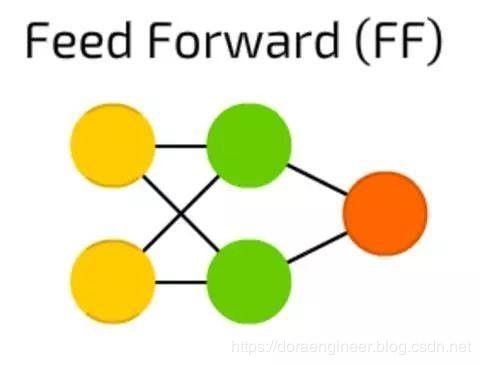 |
| ADALINE网络模型 | 1959 | 自适应线性元件(Adaptive linear element,简称Adaline)和Widrow-Hoff学习规则(又称最小均方差算法或称δ规则)的神经网络训练方法是一种连续取值的自适应线性神经元网络模型,可以用于自适应系统。 | 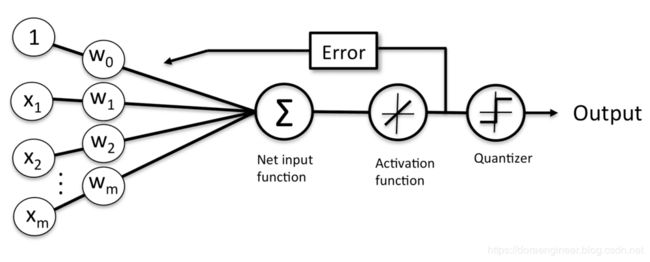 |
| 1969年发表了轰动一时《Perceptrons》一书,指出简单的线性感知器的功能是有限的,它无法解决线性不可分的两类样本的分类问题,如简单的线性感知器不可能实现“异或”的逻辑关系等。这一论断给当时人工神经元网络的研究带来沉重的打击。 | |||
| 自组织神经网络模型(SOM) | 1972 | SOM网络是一类无导师学习网络,主要用于模式识别﹑语音识别及分类问题。它采用一种“胜者为王”的竞争学习算法,与先前提出的感知器有很大的不同,同时它的学习训练方式是无指导训练,是一种自组织网络。这种学习训练方式往往是在不知道有哪些分类类型存在时,用作提取分类信息的一种训练。 |  |
| 自适应共振理论(ART) | 1976 | 其学习过程具有自组织和自稳定的特征。 | |
| Hopfield模型(HN) | 1982 | 提出了一种离散神经网络,即离散Hopfield网络,从而有力地推动了神经网络的研究。在网络中,它首次将李雅普诺夫(Lyapunov)函数引入其中,后来的研究学者也将Lyapunov函数称为能量函数。证明了网络的稳定性。Hopfield神经网络是一组非线性微分方程。Hopfield的模型不仅对人工神经网络信息存储和提取功能进行了非线性数学概括,提出了动力方程和学习方程,还对网络算法提供了重要公式和参数,使人工神经网络的构造和学习有了理论指导 |  |
| Boltzmann机模型(BM) | 1983 | 1984年,Hinton与年轻学者Sejnowski等合作提出了大规模并行网络学习机,并明确提出隐单元的概念,这种学习机后来被称为Boltzmann机。Hinton和Sejnowsky利用统计物理学的感念和方法,首次提出的多层网络的学习算法,称为Boltzmann 机模型。 |  |
| 限制玻尔兹曼机(RBM) | 1986 | 限制玻尔兹曼机(RBM)与BM非常相似,也与HN类似。BM和RBM之间的最大区别是,RBM有更好的可用性,因为它受到更多的限制。RBM不会将每个神经元连接到每个其他神经元,但只将每个神经元组连接到每个其他组,因此没有输入神经元直接连接到其他输入神经元,也不会有隐藏层直接连接到隐藏层。RBM可以像FFNN一样进行训练,而不是将数据向前传播然后反向传播。 |  |
| BP神经网络模型 | 1986 | 在多层神经网络模型的基础上,提出了多层神经网络权值修正的反向传播学习算法----BP算法(Error Back-Propagation),解决了多层前向神经网络的学习问题,证明了多层神经网络具有很强的学习能力 |  |
| 并行分布处理理论 | 1986 | 建立了并行分布处理理论,主要致力于认知的微观研究,同时对具有非线性连续转移函数的多层前馈网络的误差反向传播算法即BP算法进行了详尽的分析,解决了长期以来没有权值调整有效算法的难题。可以求解感知机所不能解决的问题。 | |
| 径向基函数(RBF) | 1988 | 径向基函数(RBF)网络就是以径向基函数作为激活函数的FFNN网络。但是RBFNN有其区别于FFNN的使用场景(由于发明时间问题大多数具有其他激活功能的FFNN都没有自己的名字) |  |
| 支持向量机、维数等概念(SVM) | 90年代初 | 用于二元分类工作,无论这个网络处理多少维度或输入,结果都会是“是”或“否”。SVM不是所有情况下都被叫做神经网络。 |  |
| 深度前馈神经网络(Deep Feed Foward,DFF) | 在训练传统的前馈神经网络时,我们只向上一层传递了少量的误差信息。由于堆叠更多的层次导致训练时间的指数增长,使得深度前馈神经网络非常不实用。直到00年代初,我们开发了一系列有效的训练深度前馈神经网络的方法; 现在它们构成了现代机器学习系统的核心,能实现前馈神经网络的功能,但效果远高于此。 | 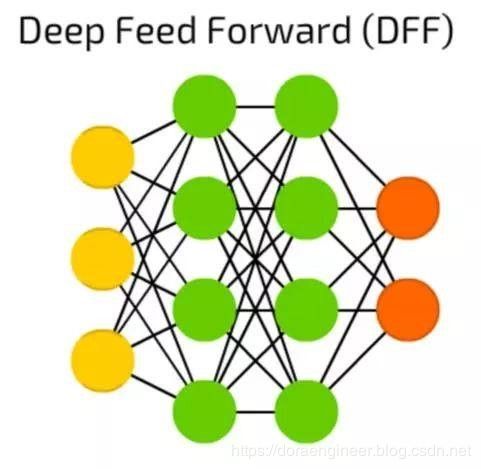 |
|
| 深度学习(Deep Learning,DL)由Hinton等人于2006年提出,是机器学习的一个新领域。深度学习本质上是构建含有多隐层的机器学习架构模型,通过大规模数据进行训练,得到大量更具代表性的特征信息。深度学习算法打破了传统神经网络对层数的限制,可根据设计者需要选择网络层数。 | |||
| 循环神经网络(Recurrent neural networks , RNN) | 20世纪90年代 | 循环神经网络(Recurrent neural networks , RNN)是考虑时间的前馈神经网络:它们并不是无状态的;通道与通道之间通过时间存在这一定联系。神经元不仅接收来上一层神经网络的信息,还接收上一通道的信息。这就意味着你输入神经网络以及用来训练网络的数据的顺序很重要:输入”牛奶“、”饼干“和输入”饼干“、”牛奶“会产生不一样的结果。 | 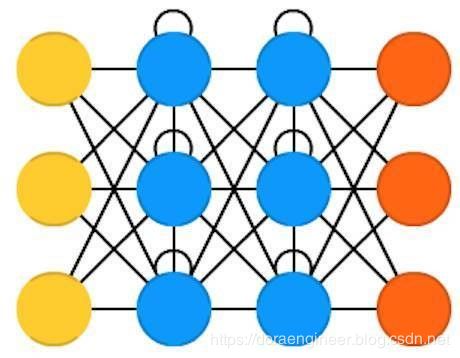 |
| 长短时记忆网络(Long / short term memory , LSTM) | 通过引入门结构(gate)和一个明确定义的记忆单元(memory cell)来尝试克服梯度消失或者梯度爆炸的问题。每个神经元有一个记忆单元和是三个门结构:输入、输出和忘记。这些门结构的功能是通过禁止或允许信息的流动来保护信息。输入门结构决定了有多少来自上一层的信息被存储当前记忆单元。 | 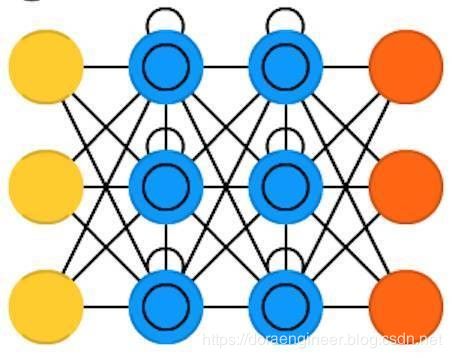 |
|
| 双向循环神经网络(Bidirectional recurrent neural networks, BRNN) | 因为它们看起来和相应的单向网络是一样的。不同之处在于这些网络不仅联系过去,还与未来相关联。比如,单向长短时记忆网络被用来预测单词”fish“的训练过程是这样的:逐个字母地输入单词“fish”, 在这里循环连接随时间记住最后的值。比如,在图像处理中,它并非扩展图像的边界,而是可以填补一张图片中的缺失。 | 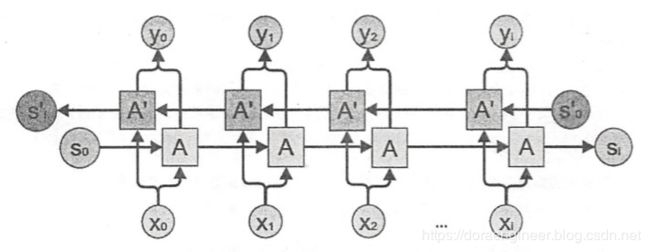 |
|
| 门控循环单元(Gated recurrent units , GRU) | GRU是具有不同门的LSTM。听起来很简单,但缺少输出门可以更容易基于具体输入重复多次相同的输出,目前此模型在声音(音乐)和语音合成中使用得最多。实际上的组合虽然有点不同:但是所有的LSTM门都被组合成所谓的更新门(Update Gate),并且复位门(Reset Gate)与输入密切相关。它们比LSTM消耗资源少,但几乎有相同的效果。 |  |
|
| 自编码器(Autoencoders, AE) | 1988 | 当您训练前馈(FF)神经网络进行分类时,您主要必须在Y类别中提供X个示例,并且期望Y个输出单元格中的一个被激活。 这被称为“监督学习”。自动编码器可以在没有监督的情况下进行训练。它们的结构 - 当隐藏单元数量小于输入单元数量(并且输出单元数量等于输入单元数)时,并且当自动编码器被训练时输出尽可能接近输入的方式,强制自动编码器泛化数据并搜索常见模式。 | 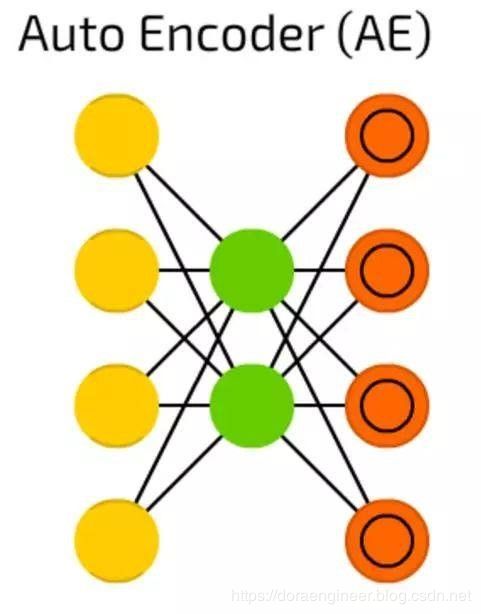 |
| 卷积网络卷积神经网络(Convolutional neural networks, CNN) | 20世纪90年代 | 大多数其他网络完全不同。它们主要用于图像处理,但也可用于其他类型的输入,如音频。卷积神经网络的一个典型应用是:将图片输入网络,网络将对图片进行分类。 | 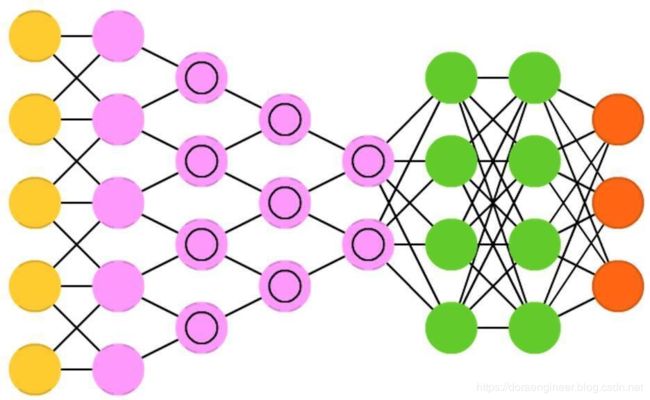 |
| AlexNet | 2012 | AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速。 |  |
| GoogLeNet | 2014 | 在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。 | 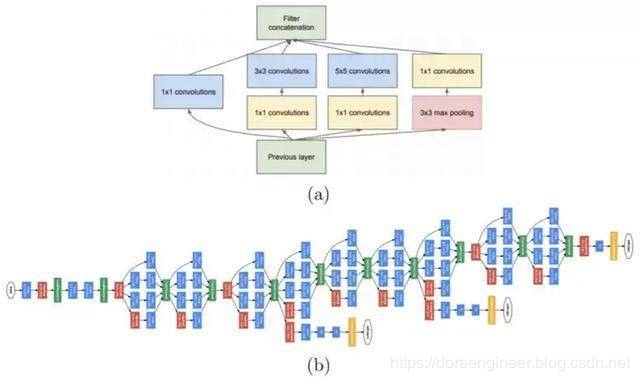 |
| ResNet | 2015 | 正是受制于此不清不楚的问题,VGG网络达到19层后再增加层数就开始导致分类性能的下降。而Resnet网络作者则想到了常规计算机视觉领域常用的residual representation的概念,并进一步将它应用在了CNN模型的构建当中,于是就有了基本的residual learning的block。它通过使用多个有参层来学习输入输出之间的残差表示,而非像一般CNN网络(如Alexnet/VGG等)那样使用有参层来直接尝试学习输入、输出之间的映射。实验表明使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射要容易得多(收敛速度更快),也有效得多(可通过使用更多的层来达到更高的分类精度)。 | 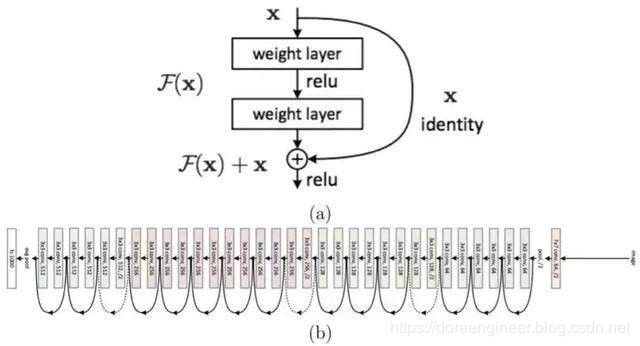 |
| DenseNet | 2017 | DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:(1) 相比ResNet拥有更少的参数数量.(2) 旁路加强了特征的重用.(3) 网络更易于训练,并具有一定的正则效果.(4) 缓解了gradient vanishing和model degradation的问题. | 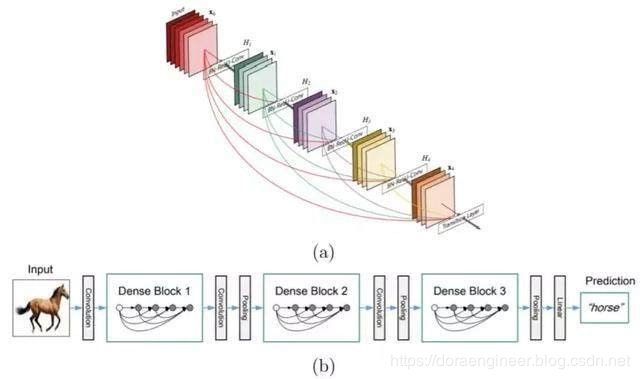 |
| 去卷积网络(Deconvolutional networks, DN) | 是将DCN颠倒过来。DN能在获取猫的图片之后生成像(狗:0,蜥蜴:0,马:0,猫:1)一样的向量。DNC能在得到这个向量之后,能画出一只猫。 |  |
|
| 深度卷积逆向图网络(Deep convolutional inverse graphics networks , DCIGN) | 事实上它们是变分自编码器(VAE),只是在编码器和解码器中分别有卷积神经网络(CNN)和反卷积神经网络(DNN)。这些网络尝试在编码的过程中对“特征“进行概率建模,这样一来,你只要用猫和狗的独照,就能让网络学会生成一张猫和狗的合照。同样的,你可以输入一张猫的照片,如果猫的旁边有一只恼人的邻居家的狗,你可以让网络将狗去掉。实验显示,这些网络也可以用来学习对图像进行复杂转换,比如,改变3D物体的光源或者对物体进行旋转操作。这些网络通常用反向传播进行训练。 |  |
|
| 液体状态机(Liquid state machines ,LSM) | 是一种稀疏的,激活函数被阈值代替了的(并不是全部相连的)神经网络。只有达到阈值的时候,单元格从连续的样本和释放出来的输出中积累价值信息,并再次将内部的副本设为零。是一种稀疏的,激活函数被阈值代替了的(并不是全部相连的)神经网络。只有达到阈值的时候,单元格从连续的样本和释放出来的输出中积累价值信息,并再次将内部的副本设为零。 |  |
|
| 极端学习机(Extreme learning machines , ELM) | 是通过产生稀疏的随机连接的隐藏层来减少FF网络背后的复杂性。它们需要用到更少计算机的能量,实际的效率很大程度上取决于任务和数据。 |  |
|
| 回声状态网络(Echo state networks , ESN) | 是重复网络的细分种类。数据会经过输入端,如果被监测到进行了多次迭代(请允许重复网路的特征乱入一下),只有在隐藏层之间的权重会在此之后更新。 |  |
|
| 深度残差网络(Deep residual networks , DRN) | 具有非常深度的前馈神经网络,除了邻近层之间有连接,它可以将输入从一层传到后面几层(通常是2到5层)。深度残差网络并非将一些输入(比如通过一个5层网络)映射到输出,而是学习将一些输入映射到一些输出+输入上。 |  |
|
| 生成对抗网络(Generative adversarial networks , GAN) | 2014 | 生成对抗网络(GAN)由两个互相竞争的模块或子网络构成,即:生成器网络和鉴别器网络。网络是成对出现的:两个网络一起工作。生成式对抗网络可以由任何两个网络构成(尽管通常情况下是前馈神经网络和卷积神经网络配对),其中一个网络负责生成内容,另外一个负责对内容进行判别。判别网络同时接收训练数据和生成网络生成的数据。判别网络能够正确地预测数据源,然后被用作生成网络的误差部分。这形成了一种对抗:判别器在辨识真实数据和生成数据方面做得越来越好,而生成器努力地生成判别器难以辨识的数据。 |  |
| 迁移学习(Transfer Learning) | 迁移学习TL(Transfer Learning)是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习,可以将已经学到的模型参数通过某种方式来分享给新模型从而加快并优化模型的学习效率。 |  |
参考
特点作用
什么是人工神经网络?有什么特点和应用?
历史发展
神经网络简史
人工神经网络综述
概念
94页论文综述卷积神经网络:从基础技术到研究前景
计算机视觉知识点总结
李宏毅课程书籍
模型分类
模型那么多,该怎么选择呢?没事,这里有27种神经网络的图解
转型人工智能,你需要掌握的八大神经网络
常见的神经网络模型大总结
多图|一文看懂25个神经网络模型
- Doraengineer’s blog说明