街景字符编码识别项目学习笔记(三)torchvision中的数据增强方法
内容简介
本文介绍torchvision当中有关数据增强方法的使用以及其在街景字符编码识别项目起到的效果。
基本方法总结如下表
| 方法 | 效果 |
|---|---|
| transforms.Resize((m,n)) | 将原始图像进行resize |
| transforms.RandomCrop((m,n)) | 将原始图像进行随机剪裁 |
| transforms.CenterCrop((m.n)) | 取图像中心处进行一定大小的剪裁 |
| transforms.ColorJitter(a,b,c,d) | 调整原始图像有关颜色对比度等参数 |
| transforms.Grayscale(num_output_channels) | 将原始图像变为灰度图 |
| transforms.RandomHorizontalFlip(p) | 对原始图像进行随机水平翻转 |
| transforms.RandomVerticalFlip(p) | 对原始图像进行随机竖直翻转 |
| transforms.RandomRotation(a) | 随机使图像旋转一定的角度 |
| transforms.RandomErasing(p,scale,ratio,value,inplace) | 对原始图像进行仿射变换 |
| transforms.Pad(padding,fill,padding_mode) | 对原始图像周围进行元素补充 |
以下是对上述方法针对本次项目的应用,同时包含对函数中参数设置的详细说明。
应用效果
选取一张图片并进行读取
im = Image.open('D:/dawhale_cv1/input/train/000011.png')

对一张图片进行resize操作 输入参数为一个tuple 代表resize之后的图片大小
im_resize = transforms.Resize((100,100))(im) #resize

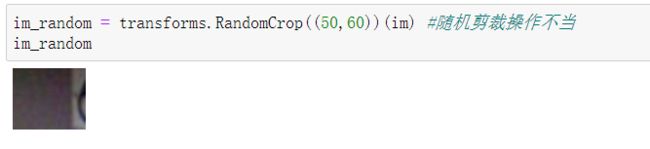
对一张图片进行随机剪裁操作,输入参数同上。当随机剪裁得当的时候,为下图效果
im_random = transforms.RandomCrop((60,100))(im)

可以看到如果选择一个较为准确得size来对原始图像进行剪裁,则能够获得较为突出的特征,这样有助于网络进行特征提取。如果选取的size出现的过小,则可能会导致获得的图片不足以让网络获得正确的含有数字的图片信息。如下图所示:
以一张图片的中心为基准,截取一定size的图片。输入变量同上。
im_center = transforms.CenterCrop((60.60))(im)

对图片从对比度,亮度等参数进行调整。brightness 参数为亮度调整因子 取值为a时 从[max(0,1-a),1+a]当中随机选择,conttrast 为对比度参数,saturation为饱和度参数,取值范围brightness。hue为色相参数 当为a时 从[-a,a]中选择参数 0<=a<=0.5
im_light = transforms.ColorJitter(brightness=0.8,contrast=0.8,saturation=0.9,hue=0.2)(im)

将图片转换为灰度图。num_output_channels为输出通道的数目,只能为1或3。
im_gray = transforms.Grayscale(num_output_channels=3)(im)

将图片随机进行水平翻转,p为设置的翻转的概率。因为本次的项目为识别数字,如6,9这样的数字,经过水平翻转之后识别到的数字和正常的数字不一致,因此本次项目不适合用这样的数据增强方式。
im_H = transforms.RandomHorizontalFlip(p=0.5)(im)

将图片随机进行竖直翻转,p为设置的翻转的概率。本次项目不适合用这样的数据增强方式,原因如上。
im_V = transforms.RandomVerticalFlip(p=0.5)(im)

对图像进行随机的旋转。旋转范围为-10-10
im_rotation = transforms.RandomRotation(10)(im)

对原始图像进行随机遮挡操作。因为很容易遮挡到图片中数字,因此本次项目中同样不采用这样的方式。p为执行该变化的概率,scale为设置的遮挡区域占总区域大小的比率,ratio为遮挡区域的长宽比,value为设置的遮挡区域的像素值,(R,G,B)输入或者是单灰度值。 im_erase为tensor,im_1同样需要为tensor对象
im_erase = transforms.RandomErasing(p=1,scale=(0.03,0.12),ratio=(0.3,0.7),value=0,inplace=False)(im_1)
对原始图像的周围进行像素扩充,即padding操作。padding取a的时候,则图片的上下左右均填充n个元素,当输入为(a,b)时,上下两个方向填充b个元素,左右方向填充a个元素。当为(a,b,c,d)时,上下左右四个方向分别填充a,b,c,d四个元素。padding_mode填充模式,有constant,edge,reflect,symmetric四种模式。fill变量设置填充的像素值,(R,G,B)或者是(gray)
im_pad = transforms.Pad(padding=20,fill=(125,24,87),padding_mode = 'constant')(im)

多种数据增强方法的集成
torchvison同样提供了能够进行一组transform操作的方式。以下分别进行说明:
每一个transforms方法在应用时的形式如以下所示:
[
# 缩放到固定尺寸
transforms.Resize((64, 128)),
# 随机颜色变换
transforms.ColorJitter(0.2, 0.2, 0.2),
# 加入随机旋转
transforms.RandomRotation(5),
# 将图片转换为pytorch 的tesntor
transforms.ToTensor(),
# 对图像像素进行归一化
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]
需要从一些列的transforms方法当中随机挑选一个时,操作如下所示:
transforms.RandomCoice([transforms1,transforms2...])
当需要依据概率随机进行一组transforms操作时
transforms.Rondom.RondomApply([transforms1,transforms2...]}
当我们希望对一组transforms操作的顺序进行打乱的时候
transforms.RondomOrder([transforms1,transforms2...])
在实际的应用当中,我们需要对输入的图片进行一系列的方法按照顺序来进行,为此我们可以利用Compose方法对这些操作进行统一的集成,按本节最开始的例子,操作如下所示:
transforms.Compose([
# 缩放到固定尺寸
transforms.Resize((64, 128)),
# 随机颜色变换
transforms.ColorJitter(0.2, 0.2, 0.2),
# 加入随机旋转
transforms.RandomRotation(5),
# 将图片转换为pytorch 的tesntor
transforms.ToTensor(),
# 对图像像素进行归一化
ransforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
我们把这样一个Compose加入到定义的dataset当中,就完成了对dataset的数据增强操作啦。
data = SVHNDataset(train_path, train_label,transforms.Compose([.......])
一点理解:实际上如果从最基本的transforms方法来看,这样的数据增强方法并不是在我们的训练集当中加入一张经过特定处理的图片,而是在数据输入到神经网络当中训练的时候,对其进行transforms方法变换,从而实现了数据增强的效果,而我们这样实现数据增强的话,网络在更多时候难以获得最开始的图片。如果说我们希望更加准确得扩充数据集,个人感觉似乎对每一张图片进行处理,然后存储到本地,再对标签进行扩增,这样会不会好一些?可能,也差不多。
参考资料
https://www.pythonheidong.com/blog/article/147611/