Deep Stacked Hierarchical Multi-patch Network for Image Deblurring代码解读
论文代码:https://github.com/HongguangZhang/DMPHN-cvpr19-master
论文地址:https://arxiv.org/pdf/1904.03468.pdf
论文解读:https://blog.csdn.net/weixin_42784951/article/details/106108196
文章使用 1-2-4-8 的结构模式。其中1-2-4-8 代表由粗到细网络所使用的图像块。
网络的每个层都由一对编码器/解码器组成。 通过将模糊图像输入B1分成多个不重叠的图像块块来生成每个级别的输入。 较低级别(对应于更精细的网格)的编码器和解码器的输出将被添加到较高级别(高于一个级别),以便顶层包含在较精细级别中推断出的所有信息。 请注意,每个级别的输入和输出图像块的数量是不同的,因为我们工作的主要思想是使较低级别的注意力集中在局部信息(更细的网格)上,从而为较粗的网格提供残差信息(通过级联卷积获得特征)。
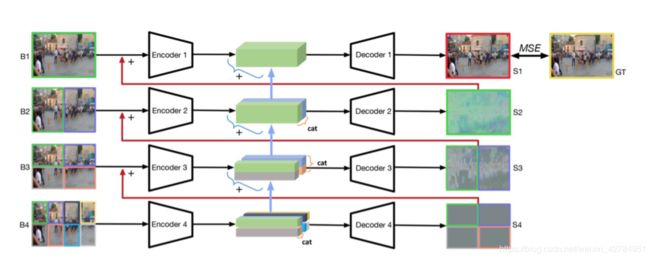
下面我们从编码器开始对论文进行解读:
如文章所述,编码器由简单卷积和激活函数组成
self.layer1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1)
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1)
)
#Conv2
self.layer5 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.layer6 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1)
)
self.layer7 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, padding=1)
)
#Conv3
self.layer9 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.layer10 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1)
)
self.layer11 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1)
)
Encoder如下 :
x = self.layer1(x)
x = self.layer2(x) + x
x = self.layer3(x) + x
#Conv2
x = self.layer5(x)
x = self.layer6(x) + x
x = self.layer7(x) + x
#Conv3
x = self.layer9(x)
x = self.layer10(x) + x
x = self.layer11(x) + x
编码器代码如上,解码器代码与编码器类似,只不过是将卷积变为去卷积。
下面是网络初始化:
print("init data folders")
#编码器层赋值
encoder_lv1 = models.Encoder()
encoder_lv2 = models.Encoder()
encoder_lv3 = models.Encoder()
#解码器层赋值
decoder_lv1 = models.Decoder()
decoder_lv2 = models.Decoder()
decoder_lv3 = models.Decoder()
#编码器层权重初始化
encoder_lv1.apply(weight_init).cuda(GPU)
encoder_lv2.apply(weight_init).cuda(GPU)
encoder_lv3.apply(weight_init).cuda(GPU)
#解码器层权重初始化
decoder_lv1.apply(weight_init).cuda(GPU)
decoder_lv2.apply(weight_init).cuda(GPU)
decoder_lv3.apply(weight_init).cuda(GPU)
#对参数进行优化
encoder_lv1_optim = torch.optim.Adam(encoder_lv1.parameters(),lr=LEARNING_RATE)
encoder_lv1_scheduler = StepLR(encoder_lv1_optim,step_size=1000,gamma=0.1)
encoder_lv2_optim = torch.optim.Adam(encoder_lv2.parameters(),lr=LEARNING_RATE)
encoder_lv2_scheduler = StepLR(encoder_lv2_optim,step_size=1000,gamma=0.1)
encoder_lv3_optim = torch.optim.Adam(encoder_lv3.parameters(),lr=LEARNING_RATE)
encoder_lv3_scheduler = StepLR(encoder_lv3_optim,step_size=1000,gamma=0.1)
decoder_lv1_optim = torch.optim.Adam(decoder_lv1.parameters(),lr=LEARNING_RATE)
decoder_lv1_scheduler = StepLR(decoder_lv1_optim,step_size=1000,gamma=0.1)
decoder_lv2_optim = torch.optim.Adam(decoder_lv2.parameters(),lr=LEARNING_RATE)
decoder_lv2_scheduler = StepLR(decoder_lv2_optim,step_size=1000,gamma=0.1)
decoder_lv3_optim = torch.optim.Adam(decoder_lv3.parameters(),lr=LEARNING_RATE)
decoder_lv3_scheduler = StepLR(decoder_lv3_optim,step_size=1000,gamma=0.1)
#判断训练好的权重是否存在
if os.path.exists(str('./checkpoints/' + METHOD + "/encoder_lv1.pkl")):
encoder_lv1.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/encoder_lv1.pkl")))
print("load encoder_lv1 success")
if os.path.exists(str('./checkpoints/' + METHOD + "/encoder_lv2.pkl")):
encoder_lv2.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/encoder_lv2.pkl")))
print("load encoder_lv2 success")
if os.path.exists(str('./checkpoints/' + METHOD + "/encoder_lv3.pkl")):
encoder_lv3.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/encoder_lv3.pkl")))
print("load encoder_lv3 success")
if os.path.exists(str('./checkpoints/' + METHOD + "/decoder_lv1.pkl")):
decoder_lv1.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/decoder_lv1.pkl")))
print("load encoder_lv1 success")
if os.path.exists(str('./checkpoints/' + METHOD + "/decoder_lv2.pkl")):
decoder_lv2.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/decoder_lv2.pkl")))
print("load decoder_lv2 success")
if os.path.exists(str('./checkpoints/' + METHOD + "/decoder_lv3.pkl")):
decoder_lv3.load_state_dict(torch.load(str('./checkpoints/' + METHOD + "/decoder_lv3.pkl")))
print("load decoder_lv3 success")
if os.path.exists('./checkpoints/' + METHOD) == False:
os.system('mkdir ./checkpoints/' + METHOD)

接下来就是迭代训练的过程,如上图所示,本文为 1-2-4三个尺度,在三个尺度中分别将输入的模糊图像分成1、2、4部分,再分别送入三个尺度的编码器解码器网络,代码如下:
for iteration, images in enumerate(train_dataloader):
#损失函数初始化
mse = nn.MSELoss().cuda(GPU)
#对图像及图像尺寸进行初始化
gt = Variable(images['sharp_image'] - 0.5).cuda(GPU)
H = gt.size(2)
W = gt.size(3)
#第一尺度图像输入---输入全部图像
images_lv1 = Variable(images['blur_image'] - 0.5).cuda(GPU)
#第二尺度图像输入---按照高度输入两部分
images_lv2_1 = images_lv1[:,:,0:int(H/2),:]
images_lv2_2 = images_lv1[:,:,int(H/2):H,:]
#第三尺度图像输入---按照宽度对第二尺度的两个部分再进行分割变为四部分
images_lv3_1 = images_lv2_1[:,:,:,0:int(W/2)]
images_lv3_2 = images_lv2_1[:,:,:,int(W/2):W]
images_lv3_3 = images_lv2_2[:,:,:,0:int(W/2)]
images_lv3_4 = images_lv2_2[:,:,:,int(W/2):W]
#由于文章是由细到粗,先输入第四尺度,将输入图像四个部分分别输入第四层编码器网络
feature_lv3_1 = encoder_lv3(images_lv3_1)
feature_lv3_2 = encoder_lv3(images_lv3_2)
feature_lv3_3 = encoder_lv3(images_lv3_3)
feature_lv3_4 = encoder_lv3(images_lv3_4)
#将第三个尺度的进行合并后送入解码器
feature_lv3_top = torch.cat((feature_lv3_1, feature_lv3_2), 3)
feature_lv3_bot = torch.cat((feature_lv3_3, feature_lv3_4), 3)
feature_lv3 = torch.cat((feature_lv3_top, feature_lv3_bot), 2)
residual_lv3_top = decoder_lv3(feature_lv3_top)
residual_lv3_bot = decoder_lv3(feature_lv3_bot)
#第二个尺度的输入为第三个尺度输出与原始图像分割成的两个部分合并之后再送入网络
feature_lv2_1 = encoder_lv2(images_lv2_1 + residual_lv3_top)
feature_lv2_2 = encoder_lv2(images_lv2_2 + residual_lv3_bot)
feature_lv2 = torch.cat((feature_lv2_1, feature_lv2_2), 2) + feature_lv3
residual_lv2 = decoder_lv2(feature_lv2)
#第一个尺度的输入为第二个尺度输出合并与原始图像合并再送入网络
feature_lv1 = encoder_lv1(images_lv1 + residual_lv2) + feature_lv2
deblur_image = decoder_lv1(feature_lv1)
#损失函数
loss_lv1 = mse(deblur_image, gt)
loss = loss_lv1
#参数优化调整
encoder_lv1.zero_grad()
encoder_lv2.zero_grad()
encoder_lv3.zero_grad()
decoder_lv1.zero_grad()
decoder_lv2.zero_grad()
decoder_lv3.zero_grad()
loss.backward()
encoder_lv1_optim.step()
encoder_lv2_optim.step()
encoder_lv3_optim.step()
decoder_lv1_optim.step()
decoder_lv2_optim.step()
decoder_lv3_optim.step()