1.配置计算调度系统Yarn和计算引擎Map/Reduce
1.1 配置mapred-site.xml
namenode上配置mapred-site.xml,默认没有mapred-site.xml文件,只有一个模版文件mapred-site.xml.template
拷贝一个重命名一下即可,
cp mapred-site.xml.template mapred-site.xml
然后配置以下内容:
mapreduce.framework.name
yarn
1.2 配置yarn-site.xml
经验:yarn-site如果是集中启动,其实只需要在管理机上配置一份即可,但是如果单独启动,需要每台机器一份,在网页上可以看到当前机器的配置,以及这个配置的来源
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
1.3 配置其他节点
配置到其他节点只需要把上面两个文件copy到其他主机即可,命令如下:
scp mapred-site.xml slave1:/usr/local/hadoop/etc/hadoop/mapred-site.xml
scp mapred-site.xml slave2:/usr/local/hadoop/etc/hadoop/mapred-site.xml
scp mapred-site.xml slave3:/usr/local/hadoop/etc/hadoop/mapred-site.xml
scp yarn-site.xml slave1:/usr/local/hadoop/etc/hadoop/yarn-site.xml
scp yarn-site.xml slave2:/usr/local/hadoop/etc/hadoop/yarn-site.xml
scp yarn-site.xml slave3:/usr/local/hadoop/etc/hadoop/yarn-site.xml
为了简单起见,把YARN的resourceManager部署在NameNode上,把YARN的NodeManager部署在DataNode上(一般情况下YARN的NM会跟HDFS的DN部署在一起,至少是在一个机架上)
2.启动YARN集群
启动yarn集群start-yarn.sh :jps观察启动结果
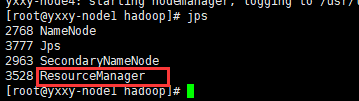
观察NodeManager情况:

启动过程:先启动自己节点中的ResourceManager,然后根据配置的slaves配置件中的slave中的NodeManager
可以使用yarn-daemon.sh单独启动resourcemanager和nodemanager
3.web观察集群
通过网页http://192.168.56.200:8088/观察集群。
如果datanode中没有配置yarn-site.xml,则网页中展示如下,没有节点信息(说明没有启动起来,启动失败)。

datanode未配置yarn-site.xml.png
如果配置了yarn-site.xml,则展示如下,含有节点配置信息
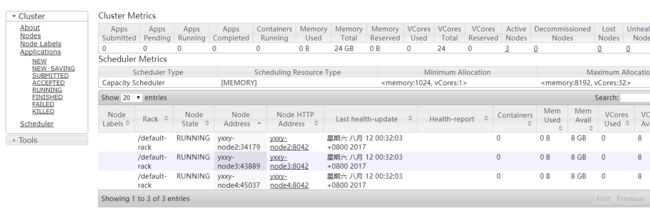
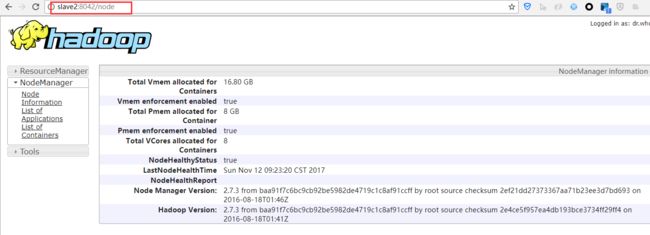
选择上面的某个节点,可以看到节点的详细信息
能够展示上面网页信息的前提是需要配置windows机上C:\Windows\System32\drivers\etc\hosts文件,如下:
192.168.56.200 master
192.168.56.201 slave1
192.168.56.202 slave2
192.168.56.203 slave3
4.测试事例
find /usr/local/hadoop -nameexample.jar 查找示例文件
通过hadoop jar xxx.jar wordcount /input /output来运行示例程序,步骤如下:
传测试文件到hdfs上
hadoop fs -put /var/tmp/test.txt /hello.txt
运行事例程序
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /hello.txt /output

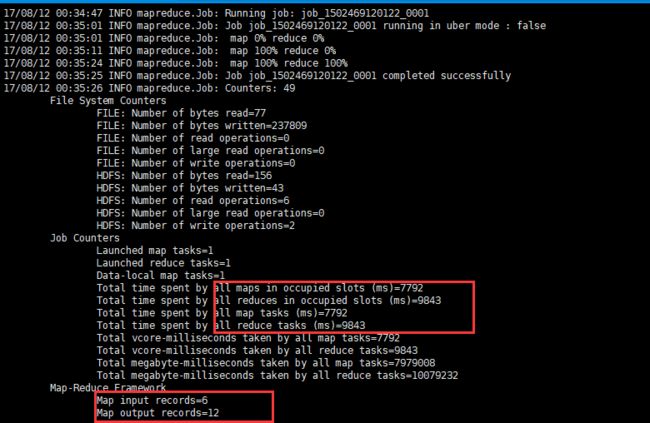
通过网页来观察该job的运行情况


运行完成,在HDFS的web管理页面可以看到输出结果,如下:

可以把part-r-00000下载下来,可以看到分词统计的结果,如下:
