Python数据分析实战:上海二手房价分析
1 数据搜集
使用 urllib 库中的request 模块爬取赶集网发布的上海二手房信息,包括包括户型、面积、单价等,再使用BeautifulSoup 库解析爬取的HTML数据,最终将数据保存到CSV文件中。
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
#爬取数据
def request_Data(url):
#创建requests对象
req = urllib.request.Request(url)
page_data_list = []
with urllib.request.urlopen(req) as response:
data = response.read()
htmlstr = data.decode()
L = parse_HTMLData(htmlstr)
page_data_list.extend(L)
return page_data_list
#解析数据
def parse_HTMLData(htmlstr):
sp = BeautifulSoup(htmlstr,'html.parser')
#获得房子信息列表
house_list = sp.select('#f_mew_list > div.f-main.f-clear.f-w1190 > div.f-main-left.f-fl.f-w980 > div.f-main-list > div > div')
#当前页中的记录列表
page_list = []
for house in house_list:
#每一行数据
rows_list = []
#获得房子标题
title = house.select('dl > dd.dd-item.title > a')
title = (title[0].text).strip()
rows_list.append(title)
#获得房子信息
infos = house.select('dl > dd.dd-item.size > span')
# 获得房子户型
house_type = (infos[0].text).strip()
rows_list.append(house_type)
# 获得房子面积
house_area = (infos[2].text).strip()
rows_list.append(house_area)
# 获得房子面积
house_face = (infos[4].text).strip()
rows_list.append(house_face)
# 获得房子楼层
house_floor = (infos[6].text).strip()
rows_list.append(house_floor)
#获得房子所在城区
addr_dist = house.select('dl > dd.dd-item.address > span > a.address-eara')
addr_dist = (addr_dist[0].text).strip()
rows_list.append(addr_dist)
#获得房子所在小区
addr_name = house.select('dl > dd.dd-item.address > span > a > span')
addr_name = (addr_name[0].text).strip()
rows_list.append(addr_name)
#获得房子总价
total_price = house.select('dl > dd.dd-item.info > div.price')
total_price = (total_price[0].text).strip()
rows_list.append(total_price)
#获得房子单价
price = house.select('dl > dd.dd-item.info > div.time')
price = (price[0].text).strip()
rows_list.append(price)
page_list.append(rows_list)
return page_list
url_temp = 'http://sh.ganji.com/ershoufang/pn{}/'
data_list = []
for i in range(1,71): #总共70页
url = url_temp.format(i)
print(url)
print('+++++第{}页++++++'.format(i))
try:
L = request_Data(url)
data_list.extend(L)
except Exception as e:
#不再循环
print('不再有数据,结束循环')
break
print(data_list)
#保存数据
#列名
colsname = ['标题', '户型', '面积', '朝向', '楼层', '城区', '小区名', '总价', '单价']
df = pd.DataFrame(data_list, columns = colsname)
df.to_csv('data/house_data.csv',index = False,encoding='gbk')
2 数据清洗
import pandas as pd
import numpy as np
house_df = pd.read_csv('data/house_data.csv',encoding='gbk')
house_df.rename(columns={'标题': 'title', '户型': 'type', '面积': 'area',
'朝向': 'face', '楼层': 'floor', '城区': 'addr_dist',
'小区名': 'addr_name', '总价': 'total_price', '单价': 'price'},inplace=True)
house_df.head()

2.1 处理缺失值
house_df.isnull().sum()
没有缺失值,工作量减轻
2.2 删除重复数据
删除重复行
house_df.duplicated().sum()
有832条重复数据
house_df2 = house_df.copy()
house_df2.drop_duplicates(inplace = True)
house_df2.count()
去重后剩余2626条数据
删除重复列
总价与单价重复,因此删除总价
house_df3 = house_df2.copy()
house_df3.pop('total_price')
2.3 统一数据格式
去掉面积的单位:m2,去掉单价的单位:元/m2
house_df4 = house_df3.copy()
house_df4['area'] = house_df4['area'].map(lambda x : float(x[0:-1]))
house_df4['price'].map(lambda x : float(x[0:-3])).head()
house_df5['price'] = house_df5['price'].map(lambda x : float(x[0:-3]))
2.4 过滤数据
过滤掉地址为“上海周边”的房源记录
house_df6 = house_df5[house_df5['addr_dist'] != '上海周边']
house_df6.count()
数据清洗后剩余2484条数据
保存数据
house_df6.index = list(range(1,2485))
house_df6.to_csv('data/house_info.csv',encoding='gbk')
3 数据分析
house_df = pd.read_csv('data/house_info.csv',encoding='gbk')
house_df.pop('Unnamed: 0')
house_df.head()
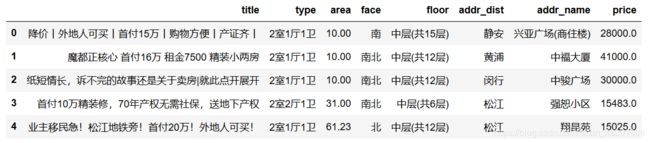
3.1 数据分组和聚合
grouped_house_df = house_df.groupby(['addr_dist'])
grouped_house_df.mean()

各区房屋平均面积、单价
3.2 数据透视
各区不同朝向的房屋平均单价
house_df.pivot_table(index = ['addr_dist'], columns = ['face'], values='price',fill_value=0)
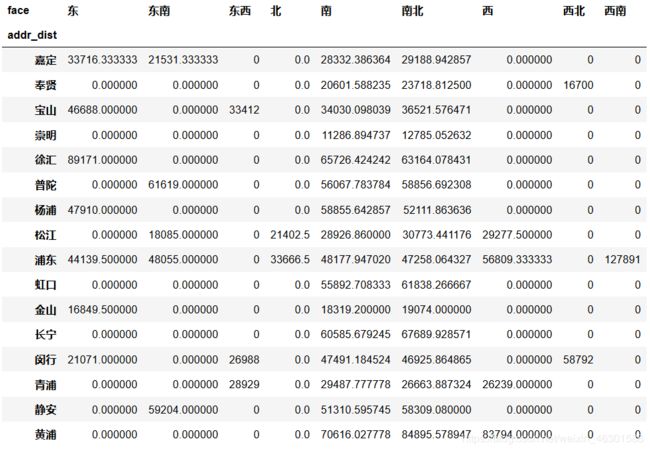
各区不同户型和朝向的房屋平均单价
house_df2.pivot_table(index = ['addr_dist'], columns = ['face','type'], values='price',fill_value=0)
4 数据可视化
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['simhei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
4.1 各区二手房价格可视化
mean_price_district = house_df.groupby('addr_dist')['price'].mean().sort_values(ascending=False)
mean_price_district.plot(kind='bar',color='b')
plt.ylim(10000,80000,10000)
plt.title("上海市各区二手房平均价格")
plt.xlabel("上海市行政区划")
plt.ylabel("房屋平均价格(元/平方米)")
plt.xticks(rotation = 360)
plt.rcParams['figure.dpi'] = 300
plt.savefig('picture/上海市各区二手房平均价格.jpg')

可以看出黄浦区均价最贵,其次是徐汇、长宁、虹口等,房价均价较高的前八名均属于上海中心城区(黄浦、徐汇、长宁、杨浦、虹口、普陀、静安以及浦东新区的外环内城区);奉贤、金山、崇明等周边城区的均价较低。
house_df.boxplot(column='price', by='addr_dist')
plt.title("上海市各区二手房价格箱形图")
plt.suptitle("")
plt.xlabel("上海市行政区划")
plt.ylabel("房屋单价(元/平方米)")
plt.savefig('picture/上海市各区二手房价格箱形图.jpg')
 上海中心城区具有较多上侧异常值,其中浦东最多,这与常识相符,如靠近知名商圈或豪宅小区的房价会特别贵。 相反,上海的周边城区异常值极少,房价分布区间相对较小。
上海中心城区具有较多上侧异常值,其中浦东最多,这与常识相符,如靠近知名商圈或豪宅小区的房价会特别贵。 相反,上海的周边城区异常值极少,房价分布区间相对较小。
4.2 各区二手房价格受面积影响情况可视化
def plot_scatter():
plt.figure(figsize=(10,8),dpi=256)
colors = ['red', 'red', 'red', 'red',
'blue', 'blue', 'blue', 'blue',
'green', 'green', 'green', 'green',
'gray', 'gray', 'gray', 'gray']
addr_dist = ['黄浦','徐汇','长宁','虹口',
'普陀','杨浦','静安','浦东',
'闵行', '宝山','松江','嘉定',
'青浦','奉贤', '金山', '崇明']
markers = ['o','s','v','x',
'o', 's', 'v', 'x',
'o', 's', 'v', 'x',
'o', 's', 'v', 'x']
print(addr_dist)
for i in range(16):
x = house_df.loc[house_df['addr_dist'] == addr_dist[i]]['area']
y = house_df.loc[house_df['addr_dist'] == addr_dist[i]]['price']
plt.scatter(x, y, c=colors[i], s=20, label=addr_dist[i], marker=markers[i])
plt.legend(loc=1,bbox_to_anchor=(1.138,1.0),fontsize=12)
plt.xlim(0,500)
plt.ylim(0,200000)
plt.title('上海各区二手房面积对房价的影响',fontsize=20)
plt.xlabel('房屋面积(平方米)',fontsize=16)
plt.ylabel('房屋单价(元/平方米)',fontsize=16)
plt.savefig('picture/上海各区二手房面积对房价的影响.jpg')
plot_scatter()

按照平均房价的顺序排列,红色为价格第一梯队,蓝色为价格第二梯队,绿色为价格第三梯队,灰色为价格第四梯队,每个梯度包含四个行政区划。从散点图中可以观察到第一梯队的红色散点相对偏向左上方,各个梯队相比于上一梯队整体向下偏移。
4.3 各区二手房价受朝向影响情况可视化
df = (house_df['face'].value_counts()).to_frame()
plt.figure(figsize=(15,15))
plt.pie(df['face'], labels=df.index.values, autopct='%.1f%%', pctdistance=0.9)
plt.title('上海市二手房朝向',fontsize=20)
plt.savefig('picture/上海市二手房朝向.jpg')
 朝向主要是南和南北朝向,接下来针对这两种朝向展开分析。
朝向主要是南和南北朝向,接下来针对这两种朝向展开分析。
house_df2 = house_df.rename(columns={'price': '房屋价格(元/平方米)', 'addr_dist': '上海市行政区划', 'face': '朝向'})
house_df2 = house_df2[house_df2['朝向'].isin(['南','南北'])]
g = sns.catplot(data=house_df2,x='朝向',y='房屋价格(元/平方米)',col='上海市行政区划',
kind='swarm',col_wrap=4,aspect=1.2)
plt.savefig('picture/上海市各区二手房朝向对房价影响.jpg')
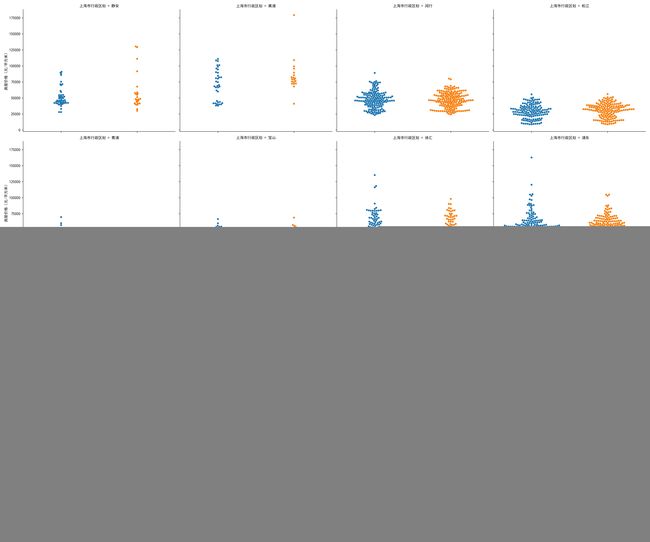 规律不是很明显,总体上,各区南朝向的房屋数量更多,最高价格更高。
规律不是很明显,总体上,各区南朝向的房屋数量更多,最高价格更高。
4.4 各区二手房价受户型影响情况可视化
df = (house_df['type'].value_counts())[:16].to_frame()
plt.figure(figsize=(15,15))
plt.pie(df['type'], labels=df.index.values, autopct='%.1f%%')
plt.title('上海市二手房户型',fontsize=20)
plt.savefig('picture/上海市二手房户型.jpg')

户型主要是1室1厅1卫、2室1厅1卫、2室2厅1卫、3室2厅1卫、3室2厅2卫,接下来针对这5种户型展开分析。
house_df2 = house_df.rename(columns = {'type':'户型','price': '房屋平均价格(元/平方米)','addr_dist': '城区'})
house_df2 = house_df2[house_df2['户型'].isin(['1室1厅1卫','2室1厅1卫','2室2厅1卫','3室2厅1卫','3室2厅2卫'])]
g = sns.catplot(kind="bar",data=house_df2, x='户型', y='房屋平均价格(元/平方米)', col='城区',
col_wrap=4, aspect=1.2, order = ['1室1厅1卫','2室1厅1卫','2室2厅1卫','3室2厅1卫','3室2厅2卫'])
plt.savefig('picture/上海市各区二手房户型对房价影响.jpg')

随着户型的增大,平均价格也基本增大;在部分区存在1室1厅1卫、2室2厅1卫这两种户型价格较高的现象。
个人练手项目,以上代码有参考来自CSDN的[Python数据分析实战篇:从数据搜集到数据可视化一步一步完成二手房价数据分析]以及[Python数据分析——上海市二手房价格分析](放链接审核不通过,说有广告,我也是醉了)。