AlphaStar的游戏——星际争霸2 AI综述
两天前,DeepMind直播展示了他们星际2AI的最新进展。AI名叫Alphastar,它在与两位职业选手的比赛录像中获得了全胜,其中一位还是世界前10的顶尖神族选手Mana。在与Mana最后一场万众瞩目的现场直播比赛中,Mana捍卫了星际2职业选手的尊严,取得胜利扳回一局。
面对这些,让人禁不住脱口而出的还是那句话:“没想到这么快”。星际2远比围棋复杂,DeepMind、facebook、阿里和腾讯等众多公司与科研单位也因而把研究星际2作为迈向通用人工智能的一把钥匙。我一直有关注星际2的比赛,很清楚以serral为首的目前顶尖职业选手变态到了何种地步。DeepMind上一篇相关论文还在研究受限环境下的小游戏,让我觉得挑战职业选手还得等好几年,真没预料到这一天来的如此突然。
本文将按以下结构进行展开:游戏要素,常用战术,职业选手,比赛进程,此前研究,问题解决,工程,算法,泛化预期。只关心技术的读者可以直接跳到后面几节。
游戏要素
《星际争霸2》是一款RTS(即时战略)游戏,说白了就是造农民采矿、造建筑、造兵、攀科技,最后派兵拆光对手的建筑。与围棋相比,虽然都属于零和博弈,但还多了不完全信息、输入输出状态空间更庞大、存在海量先验信息、游戏预测困难的问题。星际2的基本要素可分为:
- 经济:有晶体和气矿两种资源,资源有限会采完,通过造更多的农民、在矿物旁开更多的分基地来提高采集率。
- 生产力:有资源了就可以造建筑,建筑可用于生产部队、提高最大人口(上限200)、提升科技和构筑防御。
- 部队:有资源和产兵建筑了就可以生产作战单位,单位分为空中和陆地,有的还能释放技能;单位存在相互克制,但可以依靠微操(精细控制)来消除甚至逆转克制关系。
- 科技:提升科技可以解锁更高级的单位,以及提升各类单位的能力;随着部队规模越来越大,研发科技的收益也会越来越高。
- 侦查:地图上没有己方单位的地方不可见,也无法得知对手的建筑正在生产研发些什么;所以要通过单位侦查、占领瞭望塔和使用侦查技能来了解对手的现状。
- 地图:星际2有诸多比赛地图,根据地图的大小、出生点距离、路口形状等,也存在着不同的种族和战术优势,所以一局比赛的打法势必要根据地图来调整的。
常用战术
星际2在10年来的发展中已经进化出了海量的战术,可以把它们大致划分为这几类:
- 快攻:牺牲经济和科技的发展,尽可能在初期就全力建造部队击败对手;为了加快速度,经常需要把产兵建筑偷偷造在对手的基地附近,还可以派出部分甚至所有农民来协助进攻。
- Timing一波:预测对手的兵力薄弱期,通过固定的运营策略,在这些时间点集结出尽可能强大的兵力发动总攻,并且往往伴随着关键科技的恰巧升级完成。
- 压制:派出部队前压,占对手的一些便宜或者把对手压在家里无法开矿,而自己则趁机扩张。
- 骚扰:派出高机动单位、空中单位或者运输局运载部队,尽量避开敌方主力而去击杀对方的农民,从而打击他的经济。
- 控图:处于均势时,在战线上四处游走,进行充分的侦查,了解敌方主力位置和构成,等待时机进攻或者骚扰。
- 偷经济:认为敌方不会细致侦查时,偷偷在较远的位置开出分矿,铤而走险来获得经济优势。
- 偷科技:牺牲兵力或者经济,从而提早研发关键科技,来获得进攻Timing的提前
- 大后期:前中期侧重于防守和扩张,并构筑大量防守建筑来稳定战线,最终在良好的经济和科技支撑下,造出大量高级部队来蚕食消灭对手。这样一局比赛往往要很久,比如“城市化”战术甚至有打过7个多小时的...
- 换家:在正面对抗能力不如对手时,充分发挥游击战的思想,避开敌方部队的锋芒,在对方进攻时绕到他家中进行互拆,这个战术最能体现出星际2的复杂性和选手的应变能力。

职业选手
星际2的很多选手从几岁开始就打星际1,加起来已经打了十几年的星际,星际争霸的战术和微操可能已融入他们的“血液”之中。下面选取了星际1和星际2的一些职业选手,有些并不是最顶尖的,但也通过自己的独特风格推动了星际的战术演进:
- Serral:虫族,芬兰选手,目前世界第一,超出其他顶尖选手一两个档次,几乎没有弱点。
- Byun:人族,韩国选手,人称“武圣”,以两船兵战术和超强的操作而知名。已退役。Sos:神族,韩国选手,人称“狗哥”,精通各种快攻战术并且经常成功。
- Jim:神族,中国选手,擅长地堡快攻,防不胜防。
- Mma:人族,韩国选手,“多线小王子”,一到逆风就能越打越精彩,依靠极快节奏的多线运输机空投让对手无法兼顾,经常打出神奇翻盘。已退役。
- Marineking:人族,韩国选手,曾用Boxer的ID名,因而被称为“山寨Boxer”,简称“山包”;他执着于依靠人类的机枪兵,把他们用的出神入化,引领了星际2的人族微操。已退役。
- Flash:人族,韩国选手,人称“教主”、“毁灭了星际1的男人”。Flash统治了星际1,并最终转型到星际2,也取得了不错的成绩。已退役。
- Boxer:人族,韩国选手。他在星际1中开发出了诸多微操,让人们了解到微操对于即时战略游戏的重要性,极大的增强了星际的魅力,也让韩国人族从此成为“第四种族”。已退役。
比赛进程
10场录像,1场直播,比分最终是10:1,每一局使用的AlphaStar版本都不同。当时DeepMind播出了10场其中的5局,但对阵Mana未播出的第五局也非常精彩。AlphaStar在Mana二矿附近修建了vr、vs和四个电池,依靠大量建筑前置快攻拿下比赛,仿佛让人看到了“狗哥”的身影:
- 兵种组合:正如上面所说,AlphaStar兵种组合非常单一,主要依靠“追猎者”。“追猎者”对空对地,速度很快,升级后还有“闪烁”技能,操作空间很大,非常适合游击战。AlphaStar充分发挥了“追猎者”的机动性,会把没血的“追猎者”及时往后拉;并且偏向于进攻战术,从而给了“追猎者”移动的空间。但“追猎者”的弱点是攻击力不高,因此大规模交战时难以作为主战部队。在与Mana的第四局比赛录像中,AlphaStar通过三面包夹缓解了这一点,但在最后一局直播比赛中还是无法被大量的“不朽者”击败了。其次,AlphaStar也经常使用“凤凰”,这是速度极快的空中单位,只能对空,但可以使用魔法把地面单位抬到空中。AlphaStar对凤凰的微操超越了所有职业选手,并且在会战中优先抬“哨兵”也让人眼前一亮。此外,在对战TLO的第三局中,AlphaStar大量使用了“自爆球”,但失误也很多,并且目前的版本“自爆球”已经被削弱了。
- 战术选择:AlphaStar偏向于前期进攻,经常使用两个“追猎者”或者两个“使徒”进行前压,之后要么持续施压打穿对手,要么尽快开二矿建造大量“凤凰”进攻。此外还进行了三次野兵营快攻,全部得手。两次野BG打4BG战术,一次野VR和电池。所以从人类的角度看,AlphaStar是一个依靠快攻和微操来取胜的前期型选手。
- 骚扰应对:在10局比赛录像中,AlphaStar对骚扰应对的都还不错,好几次虽然没堵口让对方的“使徒”进来杀了好些农民,但由于AlphaStar农民本来就造的比较多,所以对经济也影响不大。但直播的比赛中,AlphaStar面对Mana空投不朽的骚扰显得无能为力,被长时间牵制住非常被动,导致最终输掉了比赛。
此前研究
在星际2之前,星际1就已经有很多AI,不过多为脚本,会人为设定很多战术和细节,泛化能力很弱。包括不久前18年11月的AIIDE星际争霸AI大赛,冠军赛达(SAIDA)甚至是一个完全不会学习、只会基于规则机械行动的bot。究其原因,深度强化学习对理论、工程、计算量的要求都很高,没多少团队能玩的起。16年DeepMind宣布进军星际2,17年联合暴雪推出了开发框架SC2LE;而整个18年,我了解到的研究进展有南京大学、加州大学伯克利分校、腾讯AI Lab和DeepMind,其中南大认为腾讯抄袭了他们的研究并抢先发布:
- DeepMind:使用了关系型深度学习,在几个受限场景下的小游戏中取得了最佳得分。
- 南大/伯克利/腾讯:使用了宏观-微观分层处理架构,把一个中层命令的执行逻辑用脚本提前写好,比如确定要造人口建筑的话,用脚本确定造在哪,派哪个农民去造;从而大大简化输出,减少计算量,专注在宏观决策。限制地图和种族,能击败星际2的内置脚本AI。在此基础上,南大训练了一个很粗糙的战斗网络来选择F2A的位置,腾讯则训练了一个更精细的微操网络。但有微操网络的TStarBot2反而打不过没有微操的TStarBot1,因为TStarBot1的战术是虫族快攻,所谓“板砖破武术”。
问题解决
在DeepMind宣布进军星际2之初,就有很多人包括我预测了AI会遭遇到的诸多问题,现在可以来回顾下AlphaStar是如何解决它们的:
- 海量计算:星际2游戏的复杂性无需多说,并且由于先验信息、数学推理能力、游戏模拟能力的缺失,仅通过强化学习来试错效率是非常低的。为此,AlphaStar仍然是从大量模仿人类的录像开始,并且在自我对弈时使用了上千块TPU来训练(有钱任性)。
- 长期策略:玩家当前研发的一项科技,可能需要几分钟后才研发完成,又要几分钟后才慢慢收回成本;甚至有些“膀胱”战术(城市化、泉水钩),从游戏一开始就在为大后期做铺垫。为此,AlphaStar使用LSTM网络捕捉长程信息,并且假定过去的各个指令对目前影响是相互独立的来简化计算。
- 宏观决策:这一局采取什么战术,面对突变的局面进行怎样的调整是非常宏观的东西。AlphaStar对于每一局比赛都上了不同的版本,从而有不同的战术,同一个版本可能只会一种固定打法。
- 先验信息:AlphaStar没有先验信息,而是靠海量的录像和自我对局来记住一些结论。
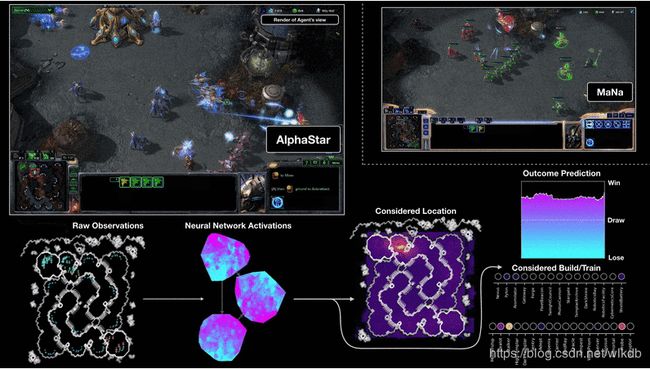
- 形势预测:AlphaStar没有类似AlphaGo快速走子的模拟网络,应该是通过当前时间点的总资源采集量、总兵力、所歼灭敌方单位、当前收入、当前兵力等来判断当前敌我实力对比。
- 战争迷雾:取得足够信息是获胜的基础,AlphaStar学会了通过农民在地图上四处游走进行侦查,并且很喜欢制造侦查单位observer。并且倾向于采取压迫性打法,能很好的掌控局面获取信息。
- 地图信息:AlphaStar无法适应不同的地图,目前只会打“汇龙岛”,对于其它地图需要重新训练模型,但底层的信息提取网络应该可以复用。
- 对手种族:星际2里三个种族差异巨大,AlphaStar目前只会对抗神族。而且人族的防守更好骚扰能力更强,虫族的战术更多变快攻更强,可能会带来一些新的问题。
- 战术欺骗:兵者诡道,战争中的欺骗是一个很高级的策略,AlphaStar在比赛中并未展现出来。
- 隐形单位:在没有反隐单位时,少量隐形部队就能决定战局。AlphaStar在比赛中很喜欢造反隐单位observer,从而没有被“黑暗圣堂武士”击垮,但还未遭遇隐形单位快攻战术的考验。
- 兵种搭配:由于单位克制的存在,一般需要根据对手的部队组成来调整自己的搭配。AlphaStar的神族主要靠“追猎者”,其次是“凤凰”,这两个单位的机动性非常强,且对空对地都有作战能力,简单而富有操作空间。对抗Mana时,AlphaStar甚至依靠“追猎者”的三面包夹游击战击败了Mana的“不朽者”大军,逆转了兵种克制关系。当然,如此单一的兵种搭配,在未来仍然是很容易被针对的。
- 战术应变:AlphaStar在比赛中比较顺风顺水,也没见到什么战术调整。
- 特殊单位:有些魔法单位的一个技能可以瞬间改变战局,因此,对于某些单位的魔法值、潜在位置甚至没有没生产都要做出缜密判断。比赛中Mana的哨兵几次优秀的立场魔法,还是给AlphaStar带来了很大损失。
- 换家残局:象棋的残局难解,星际2也一样,有时甚至会两边会互换基地从头发展。换家会极大的增加比赛的复杂性不确定性,这11局比赛未曾出现,相信未来的比赛中AlphaStar也会尽量避免这种情况。
- 逆风策略:局面不利时的应对,最能体现出一个选手的真正实力。AlphaStar只在最后一局直播比赛中遭遇了劣势,但更快被一波推平没来及做什么,期待未来能看到AlphaStar在逆风时的变化。

工程
很多介绍和论文中对工程问题都论述的不多,但我也在pysc2上进行过星际2AI开发,了解有些工程上的小细节必须要明确:
- 输入处理:之前DeepMind发布的开发框架pysc2,输入信息和人类获得的基本一样,只有大地图当前画面、小地图画面、资源人口数和所选单位的信息,非常公平。但另一方面,AI还得像人一样从原始地图信息上进行视觉识别和整合,非常繁琐。所以后来南大、腾讯和DeepMind都选择直接从api中得到己方所有单位信息,这一点其实相当于轻微作弊。
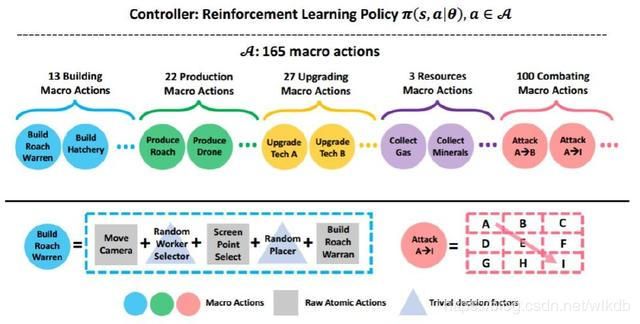
- 指令位置:星际2需要输出的指令类型其实并不算多,关键是很多指令还得带上地图坐标参数。比如下一个框选指令,就需要指定框的左上角右下角二维坐标,而坐标的可选范围就很大了。SC2LE的大地图默认分辨率是84*84,那么两个坐标的组合数就是84^4有上千万种。为了减少计算量,势必要把选择坐标、选取区域转化为可以用全连接卷积神经网络(FCN)来求解的子问题。
- 指令打包:当你在游戏中做出一个决策时,经常需要使用好几个指令来配合完成。比如决定建造一个建筑时,可能的指令流程是——切屏、选择农民、切屏、选择合适的位置进行建造、为农民设定建造完成后的去向(虫族不需要)。所以建立起指令间的关联,让相关的指令能打包执行必不可少。
-

算法
在DeepMind官网最新出炉的一篇介绍中,提到了AlphaStar所使用的算法,很明显还是远远吊打腾讯和南大的:
- 群体强化学习(多智能体算法):可谓是AlphaStar的关键技术。在自我训练左右互博时,样本的丰富性非常重要。围棋上的AlphaGo通过一定的随机来提升丰富性,但星际2状态空间太大很难采用随机的方式,所以通过为不同的版本设定不同的目标(奖励函数)来做到。比如一个版本可能专注于快攻,一个版本专注于防快攻,一个版本没有特殊目标。这种方式让我感到对AI的训练,越来越像对人类的教育。面对一个巨复杂问题,我们不能确定哪种方式最好,索性让大家各选一个小目标相互竞争,最后能得到一组最优解。我感受到随着AI技术的深入,仿佛越来越接近哲学,让我们更能理解自己、理解文明、理解宇宙。
- 模仿学习:由于没有输入先验知识(单位血量、攻击力、建造顺序等),完全从头训练及其困难,因而只能先从大量的人类录像中学习并进行模仿;但模仿也不是件简单的事,更强的模型能加强所模仿到能力的泛化性。
- 时序神经网络:相比于人脸识别等技术使用的普通神经网络,时序神经网络在训练时会保存此前的结果,让过去的输入也能影响到现在的输出,它被广泛应用于自然语言处理当中。
- 关系网络(图卷积神经网络):关系网络是知识图谱中的常用技术,由于现实中很多信息不像图片信息那么规则(长*宽*像素),从而使用传统神经网络会很麻烦。而通过关系网络,我们可以直接把星际2中各种不规则的信息进行输入。
- 自回归模型:自回归模型从线性回归发展而来,假定一个变量X主要受过去的X影响而与其他变量无关。这是一个四两拨千斤的技巧,因为星际2中的操作确实有明显的自回归性,比如微操时的移动-攻击、人口房的建造等。

泛化预期
面对这样一个巨复杂任务的解决,AlphaStar的成功是历史性的。不夸张的说,能真正让人看到一丝通用人工智能的曙光,极大拓展了人工智能的应用范围:
- 传统时序任务:AlphaStar选取了一堆先进的时序模型组合起来,解决了长程依赖问题,有助于推动自然语言处理、天气预测等时序任务的发展。
- 金融:金融领域中充斥着博弈和不透明的信息,正是AlphaStar的勇武之地。使用AlphaStar有助于预测对手的策略,选取合适的应对。
- 战争:即时战略游戏本来就是对战争的模拟,AlphaStar能对战争提前做出海量的推演来明确各类策略的优劣。
- 公司经营:很多大公司都有战略规划部,进入哪些市场,采取什么商业模式,如何与对手竞争等都需要仔细考虑,AlphaStar可以来辅助决策。
- 通用人工智能:如果说之前的深度学习偏重于识别,离人工智能还有很大距离,那么AlphaStar偏重于决策,而且是接受非规范化数据、面对不完全信息、考虑长程依赖、处理大地图、进行深度博弈下的决策,有希望应用到非常广大的领域中。

AI与星际2职业选手对战的时代开始了,AlphaStar与TLO、Mana的对战还只是这场大戏的序幕。与两年前一样,也许人类仍终将被碾压,但这个过程究竟会多反复、坚持多久,仍然难以预料而令人期待。在半个多月后的 2 月 15 日,《星际争霸2》全球总冠军 Serral 将与 ReaktorNow 组织的《星际争霸2》AI 挑战赛的冠军展开一场人机大战,这或许是星际20年来的最大盛会,也将让serral、星际和暴雪青史留名,成为通用人工智能发展道路上的一个关键点...