机器学习实战学习笔记(十三)利用SVD简化数据
PS:该系列数据都可以在图灵社区(点击此链接)中随书下载中下载(如下)

1 SVD的应用
奇异值分解
优点:简化数据,去除噪声,提高算法的结果。
缺点:数据的转换可能难以理解。
适用数据类型:数值型数据。
1.1 隐形语义索引
最早的SVD应用之一就是信息检索。我们称利用SVD的方法为隐性语义索引(Latent Semantic Index, LSI) 或隐性语义分析(Latent Semantic Analysis,LSA)。
1.2 推荐系统
SVD的另一个应用是推荐系统。简单版本的推荐系统能够计算项或者人之间的相似度。更先进的方法则先利用SVD从数据中构建一个主题空间,然后再在该空间下计算其相似度。考虑下图给出的矩阵,它是由餐馆的菜和品菜师对这些菜的意见构成的。品菜师可以采用1到5之间的任意一个整数来对菜评级。如果品菜师没有尝过某道菜,则评级为0。

对上述矩阵进行SVD处理,会得到两个奇异值。我们可以把奇异值想象成一个新空间。与上图中给出矩阵的五维或者七维不同,我们最终的矩阵只有二维。这二维分别对应上右图给出的两个组,我们可以基于每个组的共同特征来命名这二维,比如我们得到美式BBQ和日式食品这二维。
2 矩阵分解
SVD将原始的数据集矩阵Data分解成三个矩阵 U U U、 ∑ \sum ∑和 V T V^T VT。如果原始矩阵Data是m行n列,那么 U U U、 ∑ \sum ∑和 V T V^T VT就分别是m行m列、m行n列和n行n列。上述过程可以写成如下一行(下标为矩阵维数):
Data m × n = U m × n ∑ m × n V n × n T \operatorname{Data}_{m \times n}=U_{m \times n} \sum_{m \times n} V_{n \times n}^{\mathrm{T}} Datam×n=Um×nm×n∑Vn×nT
上述分解中会构建出一个矩阵∑,该矩阵只有对角元素,其他元素均为0。另一个惯例就是,∑的对角元素是从大到小排列的。这些对角元素称为奇异值(Singular Value),它们对应了原始数据集矩阵Data的奇异值。奇异值就是矩阵 D a t a ∗ D a t a T Data * Data^T Data∗DataT特征值的平方根。
在科学和工程中,一直存在这样一个普遍事实:在某个奇异值的数目(r个)之后,其他的奇异值都置为0。这就意味着数据集中仅有r个重要特征,而其余特征都是噪声或冗余特征。
3 利用Python实现SVD
Numpy有一个称为linalg的线性代数工具箱:

注意Sigma以行向量array([10., 0.])返回,而非矩阵形式,这是由于Sigma矩阵除了对角元素其他均为0,因此这种仅返回对角元素的方式能够节省空间。
建立文件svdRec.py,编写如下代码并进行测试:
import numpy as np
def loadExData():
return [[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1]]

后面三个数值数量级太小了,所以不同机器可能结果稍有不同,数量级应该差不多。于是我们就可以将最后两个值去掉了。我们的原始数据集就可以用如下结果来近似:
Data m × n ≈ U m × 3 ∑ 3 × 3 V 3 × n T \operatorname{Data}_{m \times n} \approx U_{m \times 3} \sum_{3 \times 3} V_{3 \times n}^{T} Datam×n≈Um×33×3∑V3×nT
上述近似计算的示意图:
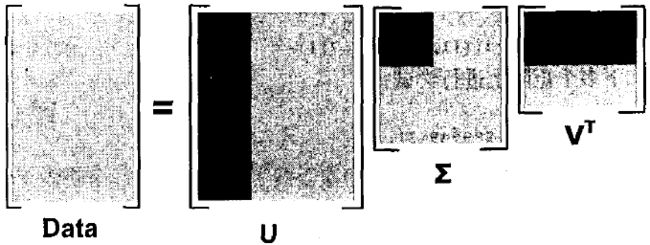
矩阵Data被分解,浅灰色区域是原始数据,深灰色区域是矩阵近似计算仅需要的数据。
接下来就可以重构原始矩阵:
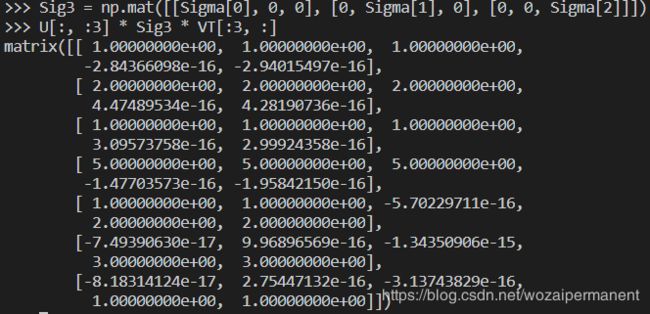
我们是如何知道仅需保留前3个奇异值的呢?确定要保留的奇异值的数目有很多启发式的策略,其中一个典型的做法就是保留矩阵中90%的能量信息。为了计算总能量信息,我们将所有的奇异值求其平方和。于是可以将奇异值的平方和累加到总值的90%为止。另一个启发式策略就是,当矩阵上有上万的奇异值时,那么就保留前面的2000或3000个。尽管后一种方法不太优雅,但是在实际中更容易实施。之所以说它不够优雅,就是因为在任何数据集上都不能保证前3000个奇异值就能够包含90%的能量信息。但在通常情况下,使用者往往都对数据有足够的了解,从而就能够做出类似的假设了。
4 基于协同过滤的推荐引擎
协同过滤(collaborative filtering): 通过将用户和其他用户的数据进行对比来实现推荐。
4.1 相似度计算
下图给出由一些用户及其对前面给出的部分菜肴的评级信息所组成的矩阵。

4.1.1 欧式距离
手撕猪肉和烤牛肉的欧式距离:
( 4 − 4 ) 2 + ( 3 − 3 ) 2 + ( 2 − 1 ) 2 = 1 \sqrt{(4-4)^2+(3-3)^2+(2-1)^2}=1 (4−4)2+(3−3)2+(2−1)2=1
手撕猪肉和鳗鱼饭的欧式距离:
( 4 − 2 ) 2 + ( 3 − 5 ) 2 + ( 2 − 2 ) 2 = 2.83 \sqrt{(4-2)^2+(3-5)^2+(2-2)^2}=2.83 (4−2)2+(3−5)2+(2−2)2=2.83
手撕猪肉和烤牛肉的距离小于手撕猪肉和鳗鱼饭的距离,因此手撕猪肉与烤牛肉比与鳗鱼饭更为相似。我们希望相似度值在0到1之间变化,而且物品对越相似,它们的相似度值就越大。可以用 相 似 度 = 1 / ( 1 + 距 离 ) 相似度=1/(1+距离) 相似度=1/(1+距离)
4.1.2 皮尔逊相关系数
皮尔逊相关系数(Pearson correlation)。该方法相对于欧式距离的一个优势在于,它对用户评级的量级并不敏感。比如某个狂躁者对所有物品的评分都是5分,而另一个忧郁者对所有物品的评级都是1分,皮尔逊相关系数会认为这两个向量是相等的。皮尔逊相关系数的取值范围从-1到1我们通过0.5+0.5*corrcoef()这个函数计算,并且把取值范围归一化到0到1之间。
4.1.3 余弦相似度
余弦相似度(cosine similarity): 计算两个向量夹角的余弦值。如果夹角为90度,则相似度为0;如果两个向量的方向相同,则相似度为1.0。也将其归一化到0到1之间。余弦相似度定义:
cos θ = A ⋅ B ∥ A ∥ ∥ B ∥ \cos \theta=\frac{A \cdot B}{\|A\|\|B\|} cosθ=∥A∥∥B∥A⋅B
'''相似度计算'''
def ecludSim(inA, inB):
return 1.0 / (1.0 + np.linalg.norm(inA - inB))
def pearsSim(inA, inB):
'''皮尔逊相关系数'''
if len(inA) < 3:
return 1.0
return 0.5 + 0.5 * np.corrcoef(inA, inB, rowvar=0)[0][1]
def cosSim(inA, inB):
'''预先相似度'''
num = float(inA.T * inB)
denom = np.linalg.norm(inA) * np.linalg.norm(inB)
return 0.5 + 0.5 * (num / denom)
上面的相似度计算都是假设数据采用了列向量方式进行表示的,暗示着我们将利用物品的相似度计算方法。
4.2 基于物品的相似度还是基于用户的相似度?
我们计算了两个餐馆菜肴之间的距离,这称为基于物品(item-based) 的相似度。另一种计算用户距离的方法则称为基于用户(user-based) 的相似度。这取决于用户或者物品的数目,基于物品相似度计算的时间会随物品数量的增加而增加,基于用户的相似度计算的时间则会随用户数量的增加而增加。对于推荐引擎而言,用户数量往往大于物品的数量,所以倾向于使用基于物品相似度的计算方法。
4.3 推荐引擎的评价
如何对推荐引擎进行评价呢?此时,我们既没有预测的目标值,也没有用户来调査他们对预测的满意程度。这里我们就可以采用前面多次使用的交叉测试的方法。具体的做法就是,我们将某些已知的评分值去掉,然后对它们进行预测,最后计算预测值和真实值之间的差异。
通常用于推荐引擎评价的指标是称为最小均方根误差(RootMeanSquaredError,RMSE) 的指标,它首先计算均方误差的平均值然后取其平方根。如果评级在1星到5星这个范围内,而我们得到的RMSE为1.0,那么就意味着我们的预测值和用户给出的真实评价相差了一个星级。
5 餐馆菜肴推荐引擎
现在我们就开始构建一个推荐引擎,该推荐引擎关注的是餐馆食物的推荐。首先我们构建一个基本的推荐引擎,它能够寻找用户没有尝过的菜肴。然后,通过SVD来减少特征空间并提高推荐的效果。
5.1 推荐未尝过的菜肴
推荐系统的工作过程是:给定一个用户,系统会为此用户返回N个最好的推荐菜。为了实现这一点,则需要我们做到:
- 寻找用户没有评级的菜肴,即在用户- 物品矩阵中的0值;
- 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说,我们认为用户可能会对物品的打分(这就是相似度计算的初衷);
- 对这些物品的评分从高到低进行排序,返回前N个物品。
def loadExData1():
return [[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 2, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0]]
def svdEst(dataMat, user, simMeans, item):
'''基于SVD的评分估计'''
n = np.shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U, Sigma, VT = np.linalg.svd(dataMat)
#构建对角矩阵
Sig4 = np.mat(np.eye(4) * Sigma[: 4])
xformedItems = dataMat.T * U[:, : 4] * Sig4.I
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item:
continue
similarity = simMeans(xformedItems[item, :].T, xformedItems[j, :].T)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
return ratSimTotal / simTotal
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
'''推荐系统,产生最高N个推荐结果'''
#寻找未评级的物品
unratedItems = np.nonzero(dataMat[user, :].A == 0)[1]
if len(unratedItems) == 0:
return 'you rated everything'
itemScores = []
for item in unratedItems:
#寻找前N个未评级的物品
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[: N]

这表明了用户2对物品2的预测评分值为2.5,对物品1的预测评分值为2.02,利用其它相似度进行那个推荐:

5.2 利用SVD提高推荐的效果
实际的数据集会比我们用于展示recommend()函数功能那个myMat矩阵稀疏得多。下图给出一个更真实的矩阵:

def loadExData2():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]

计算有多少个奇异值能达到总能量的90%:

由上图结果可知,我们可以将一个11维的矩阵转换成一个3维的矩阵。对转换后的三维空间构造出一个相似度计算函数,利用SVD将所有菜肴映射到一个低维空间,在低维空间,利用前面相同的相似度计算方法来进行推荐。这就是上面代码中的svdEst()函数,对其进行测试如下:

5.3 构建推荐引擎面临的挑战
推荐引擎面临一个问题就是如何在缺乏数据时给出好的推荐。这称为冷启动(cold-start) 问题,处理起来十分困难。
冷启动问题的解决方案,就是将推荐看成是搜索问题。在内部表现上,不同的解决办法虽然有所不同,但是对用户而言却都是透明的。为了将推荐看成是搜索问题,我们可能要使用所需要推荐物品的属性。在餐馆菜肴的例子中,我们可以通过各种标签来标记菜肴,比如素食、美式BBQ、价格很贵等。同时,我们也可以将这些属性作为相似度计算所需要的数据,这被称为基于内容(content-based) 的推荐。可能,基于内容的推荐并不如我们前面介绍的基于协同过滤的推荐效果好,但我们拥有它,这就是个良好的开始。
6 基于SVD的图像压缩
我们使用更少的像素表示之前手写数字图像:
def printMat(inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i, k]) > thresh:
print(1, end=' ')
else:
print(0, end=' ')
print(' ')
def imgCompress(numSV=3, thresh=0.8):
myl = []
for line in open('0_5.txt').readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = np.mat(myl)
print("****original matrix******")
printMat(myMat, thresh)
U, Sigma, VT = np.linalg.svd(myMat)
sigRecon = np.mat(np.zeros((numSV, numSV)))
for k in range(numSV):
sigRecon[k, k] = Sigma[k]
reconMat = U[:, : numSV] * sigRecon * VT[: numSV, :]
print("****reconstructed matrix using ", numSV, " singular values******")
printMat(reconMat, thresh)
imgCompress()函数实现了图像的压缩。它允许基于任意给定的奇异值数目来重构图像。该函数构建了一个列表,然后打开文本文件,并从文件中以数值方式读入字符。在矩阵调人之后,我们就可以在屏幕上输出该矩阵了。接下来就开始对原始图像进行SVD分解并重构图像。在程序中,通过将Sigma重新构成SigRecon来实现这一点。Sigma是一个对角矩阵,因此需要建立一个全0矩阵,然后将前面的那些奇异值填充到对角线上。最后,通过截断的 U U U和 V T V^T VT矩阵,用SigRecon得到重构后的矩阵,该矩阵通过prinMat()函数输出。

可以看到只需要两个奇异值就能相当精确地对图像实现重构。
7 小结
SVD是一种强大的降维工具,我们可以利用SVD来逼近矩阵并从中提取重要特征。通过保留矩阵80%~90%的能量,就可以得到重要的特征并去掉噪声。SVD已经运用到了多个应用中,其中一个成功的应用案例就是推荐引擎。
推荐引擎将物品推荐给用户,协同过滤则是一种基于用户喜好或行为数据的推荐的实现方法。协同过滤的核心是相似度计算方法;有很多相似度计算方法都可以用于计算物品或用户之间的相似度。通过在低维空间下计算相似度,SVD提高了推荐系引擎的效果。