cs231n:assignment2——Q4: ConvNet on CIFAR-10
视频里 Andrej Karpathy上课的时候说,这次的作业meaty but educational,确实很meaty,作业一般是由.ipynb文件和.py文件组成,这次因为每个.ipynb文件涉及到的.py文件较多,且互相之间有交叉,所以每篇博客只贴出一个.ipynb或者一个.py文件.(因为之前的作业由于是一个.ipynb文件对应一个.py文件,所以就整合到一篇博客里)
还是那句话,有错误希望帮我指出来,多多指教,谢谢
ConvolutionalNetworks.ipynb内容:
- Convolutional Networks
- Convolution Naive forward pass
- Aside Image processing via convolutions
- Convolution Naive backward pass
- Max pooling Naive forward
- Max pooling Naive backward
- Fast layers
- Convolutional sandwich layers
- Three-layer ConvNet
- Sanity check loss
- Gradient check
- Overfit small data
- Train the net
- Visualize Filters
- Spatial Batch Normalization
- Spatial batch normalization forward
- Spatial batch normalization backward
- Experiment
-
- Things you should try
- Tips for training
- Going above and beyond
- What we expect
-
- Extra Credit Description
Convolutional Networks
So far we have worked with deep fully-connected networks, using them to explore different optimization strategies and network architectures. Fully-connected networks are a good testbed for experimentation because they are very computationally efficient, but in practice all state-of-the-art results use convolutional networks instead.
First you will implement several layer types that are used in convolutional networks. You will then use these layers to train a convolutional network on the CIFAR-10 dataset.
# As usual, a bit of setup
import numpy as np
import matplotlib.pyplot as plt
from cs231n.classifiers.cnn import *
from cs231n.data_utils import get_CIFAR10_data
from cs231n.gradient_check import eval_numerical_gradient_array, eval_numerical_gradient
from cs231n.layers import *
from cs231n.fast_layers import *
from cs231n.solver import Solver
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading external modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
def rel_error(x, y):
""" returns relative error """
return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))# Load the (preprocessed) CIFAR10 data.
data = get_CIFAR10_data()
for k, v in data.iteritems():
print '%s: ' % k, v.shapeX_val: (1000, 3, 32, 32)
X_train: (49000, 3, 32, 32)
X_test: (1000, 3, 32, 32)
y_val: (1000,)
y_train: (49000,)
y_test: (1000,)
Convolution: Naive forward pass
The core of a convolutional network is the convolution operation. In the file cs231n/layers.py, implement the forward pass for the convolution layer in the function conv_forward_naive.
You don’t have to worry too much about efficiency at this point; just write the code in whatever way you find most clear.
You can test your implementation by running the following:
x_shape = (2, 3, 4, 4)
w_shape = (3, 3, 4, 4)
x = np.linspace(-0.1, 0.5, num=np.prod(x_shape)).reshape(x_shape)
w = np.linspace(-0.2, 0.3, num=np.prod(w_shape)).reshape(w_shape)
b = np.linspace(-0.1, 0.2, num=3)
conv_param = {'stride': 2, 'pad': 1}
out, _ = conv_forward_naive(x, w, b, conv_param)
correct_out = np.array([[[[-0.08759809, -0.10987781],
[-0.18387192, -0.2109216 ]],
[[ 0.21027089, 0.21661097],
[ 0.22847626, 0.23004637]],
[[ 0.50813986, 0.54309974],
[ 0.64082444, 0.67101435]]],
[[[-0.98053589, -1.03143541],
[-1.19128892, -1.24695841]],
[[ 0.69108355, 0.66880383],
[ 0.59480972, 0.56776003]],
[[ 2.36270298, 2.36904306],
[ 2.38090835, 2.38247847]]]])
# Compare your output to ours; difference should be around 1e-8
print 'Testing conv_forward_naive'
print 'difference: ', rel_error(out, correct_out)Testing conv_forward_naive
difference: 2.21214764175e-08
Aside: Image processing via convolutions
As fun way to both check your implementation and gain a better understanding of the type of operation that convolutional layers can perform, we will set up an input containing two images and manually set up filters that perform common image processing operations (grayscale conversion and edge detection). The convolution forward pass will apply these operations to each of the input images. We can then visualize the results as a sanity check.
from scipy.misc import imread, imresize
kitten, puppy = imread('kitten.jpg'), imread('puppy.jpg')
# kitten is wide, and puppy is already square
d = kitten.shape[1] - kitten.shape[0]
kitten_cropped = kitten[:, d/2:-d/2, :]
img_size = 200 # Make this smaller if it runs too slow
x = np.zeros((2, 3, img_size, img_size))
x[0, :, :, :] = imresize(puppy, (img_size, img_size)).transpose((2, 0, 1))
x[1, :, :, :] = imresize(kitten_cropped, (img_size, img_size)).transpose((2, 0, 1))
# Set up a convolutional weights holding 2 filters, each 3x3
w = np.zeros((2, 3, 3, 3))
# The first filter converts the image to grayscale.
# Set up the red, green, and blue channels of the filter.
w[0, 0, :, :] = [[0, 0, 0], [0, 0.3, 0], [0, 0, 0]]
w[0, 1, :, :] = [[0, 0, 0], [0, 0.6, 0], [0, 0, 0]]
w[0, 2, :, :] = [[0, 0, 0], [0, 0.1, 0], [0, 0, 0]]
# Second filter detects horizontal edges in the blue channel.
w[1, 2, :, :] = [[1, 2, 1], [0, 0, 0], [-1, -2, -1]]
# Vector of biases. We don't need any bias for the grayscale
# filter, but for the edge detection filter we want to add 128
# to each output so that nothing is negative.
b = np.array([0, 128])
# Compute the result of convolving each input in x with each filter in w,
# offsetting by b, and storing the results in out.
out, _ = conv_forward_naive(x, w, b, {'stride': 1, 'pad': 1})
def imshow_noax(img, normalize=True):
""" Tiny helper to show images as uint8 and remove axis labels """
if normalize:
img_max, img_min = np.max(img), np.min(img)
img = 255.0 * (img - img_min) / (img_max - img_min)
plt.imshow(img.astype('uint8'))
plt.gca().axis('off')
# Show the original images and the results of the conv operation
plt.subplot(2, 3, 1)
imshow_noax(puppy, normalize=False)
plt.title('Original image')
plt.subplot(2, 3, 2)
imshow_noax(out[0, 0])
plt.title('Grayscale')
plt.subplot(2, 3, 3)
imshow_noax(out[0, 1])
plt.title('Edges')
plt.subplot(2, 3, 4)
imshow_noax(kitten_cropped, normalize=False)
plt.subplot(2, 3, 5)
imshow_noax(out[1, 0])
plt.subplot(2, 3, 6)
imshow_noax(out[1, 1])
plt.show()
Convolution: Naive backward pass
Implement the backward pass for the convolution operation in the function conv_backward_naive in the file cs231n/layers.py. Again, you don’t need to worry too much about computational efficiency.
When you are done, run the following to check your backward pass with a numeric gradient check.
x = np.random.randn(4, 3, 5, 5)
w = np.random.randn(2, 3, 3, 3)
b = np.random.randn(2,)
dout = np.random.randn(4, 2, 5, 5)
conv_param = {'stride': 1, 'pad': 1}
dx_num = eval_numerical_gradient_array(lambda x: conv_forward_naive(x, w, b, conv_param)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: conv_forward_naive(x, w, b, conv_param)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: conv_forward_naive(x, w, b, conv_param)[0], b, dout)
out, cache = conv_forward_naive(x, w, b, conv_param)
dx, dw, db = conv_backward_naive(dout, cache)
# Your errors should be around 1e-9'
print 'Testing conv_backward_naive function'
print 'dx error: ', rel_error(dx, dx_num)
print 'dw error: ', rel_error(dw, dw_num)
print 'db error: ', rel_error(db, db_num)Testing conv_backward_naive function
dx error: 1.14027414431e-09
dw error: 2.30256641538e-10
db error: 3.20966816447e-12
Max pooling: Naive forward
Implement the forward pass for the max-pooling operation in the function max_pool_forward_naive in the file cs231n/layers.py. Again, don’t worry too much about computational efficiency.
Check your implementation by running the following:
x_shape = (2, 3, 4, 4)
x = np.linspace(-0.3, 0.4, num=np.prod(x_shape)).reshape(x_shape)
pool_param = {'pool_width': 2, 'pool_height': 2, 'stride': 2}
out, _ = max_pool_forward_naive(x, pool_param)
correct_out = np.array([[[[-0.26315789, -0.24842105],
[-0.20421053, -0.18947368]],
[[-0.14526316, -0.13052632],
[-0.08631579, -0.07157895]],
[[-0.02736842, -0.01263158],
[ 0.03157895, 0.04631579]]],
[[[ 0.09052632, 0.10526316],
[ 0.14947368, 0.16421053]],
[[ 0.20842105, 0.22315789],
[ 0.26736842, 0.28210526]],
[[ 0.32631579, 0.34105263],
[ 0.38526316, 0.4 ]]]])
print correct_out.shape
# Compare your output with ours. Difference should be around 1e-8.
print 'Testing max_pool_forward_naive function:'
print 'difference: ', rel_error(out, correct_out)(2, 3, 2, 2)
Testing max_pool_forward_naive function:
difference: 4.16666651573e-08
Max pooling: Naive backward
Implement the backward pass for the max-pooling operation in the function max_pool_backward_naive in the file cs231n/layers.py. You don’t need to worry about computational efficiency.
Check your implementation with numeric gradient checking by running the following:
x = np.random.randn(3, 2, 8, 8)
dout = np.random.randn(3, 2, 4, 4)
pool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}
dx_num = eval_numerical_gradient_array(lambda x: max_pool_forward_naive(x, pool_param)[0], x, dout)
out, cache = max_pool_forward_naive(x, pool_param)
dx = max_pool_backward_naive(dout, cache)
# Your error should be around 1e-12
print 'Testing max_pool_backward_naive function:'
print 'dx error: ', rel_error(dx, dx_num)Testing max_pool_backward_naive function:
dx error: 3.27563382511e-12
Fast layers
Making convolution and pooling layers fast can be challenging. To spare you the pain, we’ve provided fast implementations of the forward and backward passes for convolution and pooling layers in the file cs231n/fast_layers.py.
The fast convolution implementation depends on a Cython extension; to compile it you need to run the following from the cs231n directory:
python setup.py build_ext --inplaceThe API for the fast versions of the convolution and pooling layers is exactly the same as the naive versions that you implemented above: the forward pass receives data, weights, and parameters and produces outputs and a cache object; the backward pass recieves upstream derivatives and the cache object and produces gradients with respect to the data and weights.
NOTE: The fast implementation for pooling will only perform optimally if the pooling regions are non-overlapping and tile the input. If these conditions are not met then the fast pooling implementation will not be much faster than the naive implementation.
You can compare the performance of the naive and fast versions of these layers by running the following:
from cs231n.fast_layers import conv_forward_fast, conv_backward_fast
from time import time
x = np.random.randn(100, 3, 31, 31)
w = np.random.randn(25, 3, 3, 3)
b = np.random.randn(25,)
dout = np.random.randn(100, 25, 16, 16)
conv_param = {'stride': 2, 'pad': 1}
t0 = time()
out_naive, cache_naive = conv_forward_naive(x, w, b, conv_param)
t1 = time()
out_fast, cache_fast = conv_forward_fast(x, w, b, conv_param)
t2 = time()
print 'Testing conv_forward_fast:'
print 'Naive: %fs' % (t1 - t0)
print 'Fast: %fs' % (t2 - t1)
print 'Speedup: %fx' % ((t1 - t0) / (t2 - t1))
print 'Difference: ', rel_error(out_naive, out_fast)
t0 = time()
dx_naive, dw_naive, db_naive = conv_backward_naive(dout, cache_naive)
t1 = time()
dx_fast, dw_fast, db_fast = conv_backward_fast(dout, cache_fast)
t2 = time()
print '\nTesting conv_backward_fast:'
print 'Naive: %fs' % (t1 - t0)
print 'Fast: %fs' % (t2 - t1)
print 'Speedup: %fx' % ((t1 - t0) / (t2 - t1))
print 'dx difference: ', rel_error(dx_naive, dx_fast)
print 'dw difference: ', rel_error(dw_naive, dw_fast)
print 'db difference: ', rel_error(db_naive, db_fast)Testing conv_forward_fast:
Naive: 23.932088s
Fast: 0.015995s
Speedup: 1496.220665x
Difference: 2.1149165916e-11
Testing conv_backward_fast:
Naive: 23.537247s
Fast: 0.010192s
Speedup: 2309.349201x
dx difference: 5.65990987256e-12
dw difference: 1.43212406176e-12
db difference: 0.0
from cs231n.fast_layers import max_pool_forward_fast, max_pool_backward_fast
x = np.random.randn(100, 3, 32, 32)
dout = np.random.randn(100, 3, 16, 16)
pool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}
t0 = time()
out_naive, cache_naive = max_pool_forward_naive(x, pool_param)
t1 = time()
out_fast, cache_fast = max_pool_forward_fast(x, pool_param)
t2 = time()
print 'Testing pool_forward_fast:'
print 'Naive: %fs' % (t1 - t0)
print 'fast: %fs' % (t2 - t1)
print 'speedup: %fx' % ((t1 - t0) / (t2 - t1))
print 'difference: ', rel_error(out_naive, out_fast)
t0 = time()
dx_naive = max_pool_backward_naive(dout, cache_naive)
t1 = time()
dx_fast = max_pool_backward_fast(dout, cache_fast)
t2 = time()
print '\nTesting pool_backward_fast:'
print 'Naive: %fs' % (t1 - t0)
print 'speedup: %fx' % ((t1 - t0) / (t2 - t1))
print 'dx difference: ', rel_error(dx_naive, dx_fast)Testing pool_forward_fast:
Naive: 1.115254s
fast: 0.002008s
speedup: 555.416172x
difference: 0.0
Testing pool_backward_fast:
Naive: 0.476396s
speedup: 39.999800x
dx difference: 0.0
Convolutional “sandwich” layers
Previously we introduced the concept of “sandwich” layers that combine multiple operations into commonly used patterns. In the file cs231n/layer_utils.py you will find sandwich layers that implement a few commonly used patterns for convolutional networks.
from cs231n.layer_utils import *
x = np.random.randn(2, 3, 16, 16)
w = np.random.randn(3, 3, 3, 3)
b = np.random.randn(3,)
dout = np.random.randn(2, 3, 8, 8)
conv_param = {'stride': 1, 'pad': 1}
pool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}
bn_param = {'mode': 'train'}
gamma = np.ones(w.shape[0])
beta = np.zeros(w.shape[0])
###check conv_relu_pool_forward
out, cache = conv_relu_pool_forward(x, w, b, conv_param, pool_param)
dx, dw, db = conv_relu_pool_backward(dout, cache)
dx_num = eval_numerical_gradient_array(lambda x: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], b, dout)
print 'Testing conv_relu_pool'
print 'dx error: ', rel_error(dx_num, dx)
print 'dw error: ', rel_error(dw_num, dw)
print 'db error: ', rel_error(db_num, db)
## check conv_bn_relu_pool_forward
## 加了spacial batch normalization以后, db不知道为什么误差这么大,可能是因为b的维数较少所以计算中有很大一部分是加和,
## 所以积累每一元素上的小误差,也可能是在第一层网络,反向传播到第一层的时候误差就会累计的比较大
out, cache = conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)
dx, dw, db, dgamma, dbeta = conv_bn_relu_pool_backward(dout, cache)
dx_num = eval_numerical_gradient_array(lambda x: conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)[0], b, dout)
dgamma_num = eval_numerical_gradient_array(lambda gamma: conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)[0], gamma, dout)
dbeta_num = eval_numerical_gradient_array(lambda beta: conv_bn_relu_pool_forward(x, w, b, gamma, beta, conv_param, pool_param, bn_param)[0], beta, dout)
print
print 'Testing conv_relu_pool'
print 'dx error: ', rel_error(dx_num, dx)
print 'dw error: ', rel_error(dw_num, dw)
print 'db error: ', rel_error(db_num, db)
print 'dgamma error: ', rel_error(dgamma_num, dgamma)
print 'dbeta error: ', rel_error(dbeta_num, dbeta)
Testing conv_relu_pool
dx error: 1.07784659804e-08
dw error: 3.73875622936e-09
db error: 8.74414919539e-11
Testing conv_relu_pool
dx error: 1.54664016081e-06
dw error: 1.96618403155e-09
db error: 0.0185469286087
dgamma error: 9.44011367278e-12
dbeta error: 1.32364005526e-11
from cs231n.layer_utils import conv_relu_forward, conv_relu_backward
x = np.random.randn(2, 3, 8, 8)
w = np.random.randn(3, 3, 3, 3)
b = np.random.randn(3,)
dout = np.random.randn(2, 3, 8, 8)
conv_param = {'stride': 1, 'pad': 1}
out, cache = conv_relu_forward(x, w, b, conv_param)
dx, dw, db = conv_relu_backward(dout, cache)
dx_num = eval_numerical_gradient_array(lambda x: conv_relu_forward(x, w, b, conv_param)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: conv_relu_forward(x, w, b, conv_param)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: conv_relu_forward(x, w, b, conv_param)[0], b, dout)
print 'Testing conv_relu:'
print 'dx error: ', rel_error(dx_num, dx)
print 'dw error: ', rel_error(dw_num, dw)
print 'db error: ', rel_error(db_num, db)Testing conv_relu:
dx error: 2.54502598987e-09
dw error: 4.53460011947e-10
db error: 6.7945865355e-09
Three-layer ConvNet
Now that you have implemented all the necessary layers, we can put them together into a simple convolutional network.
Open the file cs231n/cnn.py and complete the implementation of the ThreeLayerConvNet class. Run the following cells to help you debug:
Sanity check loss
After you build a new network, one of the first things you should do is sanity check the loss. When we use the softmax loss, we expect the loss for random weights (and no regularization) to be about log(C) for C classes. When we add regularization this should go up.
model = ThreeLayerConvNet()
N = 50
X = np.random.randn(N, 3, 32, 32)
y = np.random.randint(10, size=N)
loss, grads = model.loss(X, y)
print 'Initial loss (no regularization): ', loss
model.reg = 0.5
loss, grads = model.loss(X, y)
print 'Initial loss (with regularization): ', lossInitial loss (no regularization): 2.30258381546
Initial loss (with regularization): 2.50837260664
Gradient check
After the loss looks reasonable, use numeric gradient checking to make sure that your backward pass is correct. When you use numeric gradient checking you should use a small amount of artifical data and a small number of neurons at each layer.
num_inputs = 2
input_dim = (3, 16, 16)
reg = 0.0
num_classes = 10
X = np.random.randn(num_inputs, *input_dim)
y = np.random.randint(num_classes, size=num_inputs)
model = ThreeLayerConvNet(num_filters=3, filter_size=3,
input_dim=input_dim, hidden_dim=7,
dtype=np.float64)
loss, grads = model.loss(X, y)
for param_name in sorted(grads):
f = lambda _: model.loss(X, y)[0]
param_grad_num = eval_numerical_gradient(f, model.params[param_name], verbose=False, h=1e-6)
e = rel_error(param_grad_num, grads[param_name])
print '%s max relative error: %e' % (param_name, rel_error(param_grad_num, grads[param_name]))W1 max relative error: 9.833916e-04
W2 max relative error: 6.500223e-03
W3 max relative error: 2.111341e-04
b1 max relative error: 4.609401e-05
b2 max relative error: 4.915309e-08
b3 max relative error: 6.948804e-10
Overfit small data
A nice trick is to train your model with just a few training samples. You should be able to overfit small datasets, which will result in very high training accuracy and comparatively low validation accuracy.
num_train = 100
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
model = ThreeLayerConvNet(weight_scale=1e-2)
solver = Solver(model, small_data,
num_epochs=10, batch_size=50,
update_rule='adam',
optim_config={
'learning_rate': 1e-3,
},
verbose=True, print_every=1)
solver.train()(Iteration 1 / 20) loss: 2.327333
(Epoch 0 / 10) train acc: 0.210000; val_acc: 0.129000
(Iteration 2 / 20) loss: 2.920699
(Epoch 1 / 10) train acc: 0.180000; val_acc: 0.136000
(Iteration 3 / 20) loss: 2.843339
(Iteration 4 / 20) loss: 2.256272
(Epoch 2 / 10) train acc: 0.140000; val_acc: 0.080000
(Iteration 5 / 20) loss: 3.195308
(Iteration 6 / 20) loss: 2.364024
(Epoch 3 / 10) train acc: 0.360000; val_acc: 0.199000
(Iteration 7 / 20) loss: 2.414444
(Iteration 8 / 20) loss: 2.564107
(Epoch 4 / 10) train acc: 0.390000; val_acc: 0.199000
(Iteration 9 / 20) loss: 2.238707
(Iteration 10 / 20) loss: 1.846348
(Epoch 5 / 10) train acc: 0.290000; val_acc: 0.156000
(Iteration 11 / 20) loss: 1.713543
(Iteration 12 / 20) loss: 1.578357
(Epoch 6 / 10) train acc: 0.580000; val_acc: 0.207000
(Iteration 13 / 20) loss: 1.487418
(Iteration 14 / 20) loss: 1.152261
(Epoch 7 / 10) train acc: 0.660000; val_acc: 0.207000
(Iteration 15 / 20) loss: 1.103686
(Iteration 16 / 20) loss: 1.153359
(Epoch 8 / 10) train acc: 0.680000; val_acc: 0.173000
(Iteration 17 / 20) loss: 1.311634
(Iteration 18 / 20) loss: 0.984277
(Epoch 9 / 10) train acc: 0.780000; val_acc: 0.231000
(Iteration 19 / 20) loss: 0.987850
(Iteration 20 / 20) loss: 0.655680
(Epoch 10 / 10) train acc: 0.840000; val_acc: 0.264000
Plotting the loss, training accuracy, and validation accuracy should show clear overfitting:
plt.subplot(2, 1, 1)
plt.plot(solver.loss_history, 'o')
plt.xlabel('iteration')
plt.ylabel('loss')
plt.subplot(2, 1, 2)
plt.plot(solver.train_acc_history, '-o')
plt.plot(solver.val_acc_history, '-o')
plt.legend(['train', 'val'], loc='upper left')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()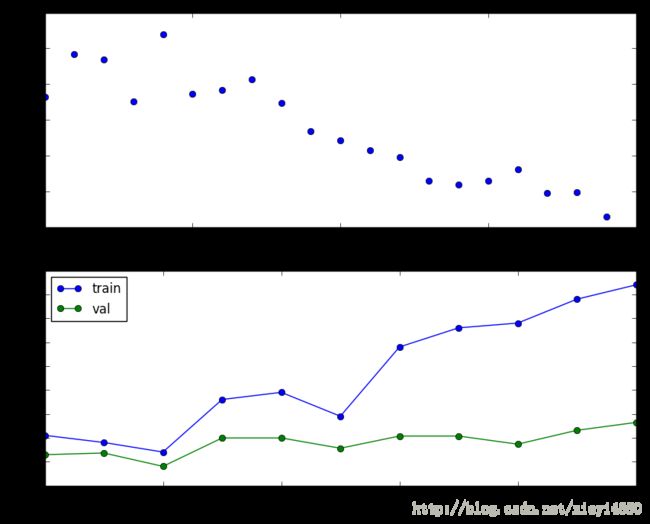
Train the net
By training the three-layer convolutional network for one epoch, you should achieve greater than 40% accuracy on the training set:
model = ThreeLayerConvNet(weight_scale=0.001, hidden_dim=500, reg=0.001)
solver = Solver(model, data,
num_epochs=1, batch_size=50,
update_rule='adam',
optim_config={
'learning_rate': 1e-3,
},
verbose=True, print_every=20)
solver.train()(Iteration 1 / 980) loss: 2.304576
(Epoch 0 / 1) train acc: 0.108000; val_acc: 0.098000
(Iteration 21 / 980) loss: 1.965750
(Iteration 41 / 980) loss: 1.979698
(Iteration 61 / 980) loss: 2.101320
(Iteration 81 / 980) loss: 1.901987
(Iteration 101 / 980) loss: 1.823573
(Iteration 121 / 980) loss: 1.559670
(Iteration 141 / 980) loss: 1.521758
(Iteration 161 / 980) loss: 1.614254
(Iteration 181 / 980) loss: 1.525828
(Iteration 201 / 980) loss: 1.801237
(Iteration 221 / 980) loss: 1.771171
(Iteration 241 / 980) loss: 1.935747
(Iteration 261 / 980) loss: 1.706197
(Iteration 281 / 980) loss: 1.771841
(Iteration 301 / 980) loss: 1.730827
(Iteration 321 / 980) loss: 1.766924
(Iteration 341 / 980) loss: 1.604705
(Iteration 361 / 980) loss: 1.689329
(Iteration 381 / 980) loss: 1.487211
(Iteration 401 / 980) loss: 1.652397
(Iteration 421 / 980) loss: 1.624637
(Iteration 441 / 980) loss: 1.774464
(Iteration 461 / 980) loss: 1.728469
(Iteration 481 / 980) loss: 1.990141
(Iteration 501 / 980) loss: 1.571801
(Iteration 521 / 980) loss: 1.592427
(Iteration 541 / 980) loss: 1.860452
(Iteration 561 / 980) loss: 1.967219
(Iteration 581 / 980) loss: 1.513192
(Iteration 601 / 980) loss: 1.872284
(Iteration 621 / 980) loss: 1.673944
(Iteration 641 / 980) loss: 1.810775
(Iteration 661 / 980) loss: 1.636547
(Iteration 681 / 980) loss: 1.489698
(Iteration 701 / 980) loss: 1.718354
(Iteration 721 / 980) loss: 1.916079
(Iteration 741 / 980) loss: 1.666237
(Iteration 761 / 980) loss: 1.716002
(Iteration 781 / 980) loss: 1.543222
(Iteration 801 / 980) loss: 1.491887
(Iteration 821 / 980) loss: 1.967372
(Iteration 841 / 980) loss: 1.685699
(Iteration 861 / 980) loss: 1.239976
(Iteration 881 / 980) loss: 1.609454
(Iteration 901 / 980) loss: 1.513272
(Iteration 921 / 980) loss: 1.752893
(Iteration 941 / 980) loss: 1.586221
(Iteration 961 / 980) loss: 1.616744
(Epoch 1 / 1) train acc: 0.476000; val_acc: 0.490000
Visualize Filters
You can visualize the first-layer convolutional filters from the trained network by running the following:
from cs231n.vis_utils import visualize_grid
grid = visualize_grid(model.params['W1'].transpose(0, 2, 3, 1))
plt.imshow(grid.astype('uint8'))
plt.axis('off')
plt.gcf().set_size_inches(5, 5)
plt.show()
Spatial Batch Normalization
We already saw that batch normalization is a very useful technique for training deep fully-connected networks. Batch normalization can also be used for convolutional networks, but we need to tweak it a bit; the modification will be called “spatial batch normalization.”
Normally batch-normalization accepts inputs of shape (N, D) and produces outputs of shape (N, D), where we normalize across the minibatch dimension N. For data coming from convolutional layers, batch normalization needs to accept inputs of shape (N, C, H, W) and produce outputs of shape (N, C, H, W) where the N dimension gives the minibatch size and the (H, W) dimensions give the spatial size of the feature map.
If the feature map was produced using convolutions, then we expect the statistics of each feature channel to be relatively consistent both between different images and different locations within the same image. Therefore spatial batch normalization computes a mean and variance for each of the C feature channels by computing statistics over both the minibatch dimension N and the spatial dimensions H and W.
Spatial batch normalization: forward
In the file cs231n/layers.py, implement the forward pass for spatial batch normalization in the function spatial_batchnorm_forward. Check your implementation by running the following:
# Check the training-time forward pass by checking means and variances
# of features both before and after spatial batch normalization
N, C, H, W = 2, 3, 4, 5
x = 4 * np.random.randn(N, C, H, W) + 10
print 'Before spatial batch normalization:'
print ' Shape: ', x.shape
print ' Means: ', x.mean(axis=(0, 2, 3))
print ' Stds: ', x.std(axis=(0, 2, 3))
# Means should be close to zero and stds close to one
gamma, beta = np.ones(C), np.zeros(C)
bn_param = {'mode': 'train'}
out, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)
print 'After spatial batch normalization:'
print ' Shape: ', out.shape
print ' Means: ', out.mean(axis=(0, 2, 3))
print ' Stds: ', out.std(axis=(0, 2, 3))
# Means should be close to beta and stds close to gamma
gamma, beta = np.asarray([3, 4, 5]), np.asarray([6, 7, 8])
out, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)
print 'After spatial batch normalization (nontrivial gamma, beta):'
print ' Shape: ', out.shape
print ' Means: ', out.mean(axis=(0, 2, 3))
print ' Stds: ', out.std(axis=(0, 2, 3))Before spatial batch normalization:
Shape: (2, 3, 4, 5)
Means: [ 11.09151825 10.38671938 9.79044576]
Stds: [ 4.23766998 4.62486377 4.55046613]
After spatial batch normalization:
Shape: (2, 3, 4, 5)
Means: [ 1.16573418e-16 8.54871729e-16 1.99840144e-16]
Stds: [ 0.99999972 0.99999977 0.99999976]
After spatial batch normalization (nontrivial gamma, beta):
Shape: (2, 3, 4, 5)
Means: [ 6. 7. 8.]
Stds: [ 2.99999916 3.99999906 4.99999879]
i=0# Check the test-time forward pass by running the training-time
# forward pass many times to warm up the running averages, and then
# checking the means and variances of activations after a test-time
# forward pass.
N, C, H, W = 10, 4, 11, 12
bn_param = {'mode': 'train'}
gamma = np.ones(C)
beta = np.zeros(C)
for t in xrange(50):
x = 2.3 * np.random.randn(N, C, H, W) + 13
spatial_batchnorm_forward(x, gamma, beta, bn_param)
bn_param['mode'] = 'test'
x = 2.3 * np.random.randn(N, C, H, W) + 13
a_norm, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)
# Means should be close to zero and stds close to one, but will be
# noisier than training-time forward passes.
print 'After spatial batch normalization (test-time):'
print ' means: ', a_norm.mean(axis=(0, 2, 3))
print ' stds: ', a_norm.std(axis=(0, 2, 3))After spatial batch normalization (test-time):
means: [ 0.06975173 0.06009512 0.02887493 0.02397713]
stds: [ 1.00763471 0.99021634 0.99863325 0.97411123]
Spatial batch normalization: backward
In the file cs231n/layers.py, implement the backward pass for spatial batch normalization in the function spatial_batchnorm_backward. Run the following to check your implementation using a numeric gradient check:
N, C, H, W = 2, 3, 4, 5
x = 5 * np.random.randn(N, C, H, W) + 12
gamma = np.random.randn(C)
beta = np.random.randn(C)
dout = np.random.randn(N, C, H, W)
bn_param = {'mode': 'train'}
fx = lambda x: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]
fg = lambda a: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]
fb = lambda b: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]
dx_num = eval_numerical_gradient_array(fx, x, dout)
da_num = eval_numerical_gradient_array(fg, gamma, dout)
db_num = eval_numerical_gradient_array(fb, beta, dout)
_, cache = spatial_batchnorm_forward(x, gamma, beta, bn_param)
dx, dgamma, dbeta = spatial_batchnorm_backward(dout, cache)
print 'dx error: ', rel_error(dx_num, dx)
print 'dgamma error: ', rel_error(da_num, dgamma)
print 'dbeta error: ', rel_error(db_num, dbeta)dx error: 4.3762056051e-08
dgamma error: 4.25829344038e-11
dbeta error: 5.07865400281e-12
Experiment!
Experiment and try to get the best performance that you can on CIFAR-10 using a ConvNet. Here are some ideas to get you started:
Things you should try:
- Filter size: Above we used 7x7; this makes pretty pictures but smaller filters may be more efficient
- Number of filters: Above we used 32 filters. Do more or fewer do better?
- Batch normalization: Try adding spatial batch normalization after convolution layers and vanilla batch normalization after affine layers. Do your networks train faster?
- Network architecture: The network above has two layers of trainable parameters. Can you do better with a deeper network? You can implement alternative architectures in the file
cs231n/classifiers/convnet.py. Some good architectures to try include:
- [conv-relu-pool]xN - conv - relu - [affine]xM - [softmax or SVM]
- [conv-relu-pool]XN - [affine]XM - [softmax or SVM]
- [conv-relu-conv-relu-pool]xN - [affine]xM - [softmax or SVM]
Tips for training
For each network architecture that you try, you should tune the learning rate and regularization strength. When doing this there are a couple important things to keep in mind:
- If the parameters are working well, you should see improvement within a few hundred iterations
- Remember the course-to-fine approach for hyperparameter tuning: start by testing a large range of hyperparameters for just a few training iterations to find the combinations of parameters that are working at all.
- Once you have found some sets of parameters that seem to work, search more finely around these parameters. You may need to train for more epochs.
Going above and beyond
If you are feeling adventurous there are many other features you can implement to try and improve your performance. You are not required to implement any of these; however they would be good things to try for extra credit.
- Alternative update steps: For the assignment we implemented SGD+momentum, RMSprop, and Adam; you could try alternatives like AdaGrad or AdaDelta.
- Alternative activation functions such as leaky ReLU, parametric ReLU, or MaxOut.
- Model ensembles
- Data augmentation
If you do decide to implement something extra, clearly describe it in the “Extra Credit Description” cell below.
What we expect
At the very least, you should be able to train a ConvNet that gets at least 65% accuracy on the validation set. This is just a lower bound - if you are careful it should be possible to get accuracies much higher than that! Extra credit points will be awarded for particularly high-scoring models or unique approaches.
You should use the space below to experiment and train your network. The final cell in this notebook should contain the training, validation, and test set accuracies for your final trained network. In this notebook you should also write an explanation of what you did, any additional features that you implemented, and any visualizations or graphs that you make in the process of training and evaluating your network.
Have fun and happy training!
model = ConvNetArch_1([(2,7),(4,5)], [5,5], connect_conv=(4,3), use_batchnorm=True,
loss_fuction = 'softmax', weight_scale=5e-2, reg=0, dtype=np.float64)
###################### check shape of initial parameters: ######################
# for k, v in model.params.iteritems():
# print "%s" % k, model.params[k].shape
################################################################################
########################### Sanit check loss: ##################################
#### zengjia batch norm yihou,结果在2.7,2.8,2.9左右,应该是在2.3左右才对,不知道哪里出错了,
#### 可能是batch norm加太多了,每一层后面都有
N = 10
X = np.random.randn(N, 3, 32, 32)
y = np.random.randint(10, size=N)
loss, _ = model.loss(X, y)
print 'Initial loss (no regularization): ', loss
model.reg = 0.1
loss, _ = model.loss(X, y)
print 'Initial loss (with regularization): ', loss
################################################################################
######################### Sanity gradient check : ###############################
N = 2
### X的宽和高设为16,加快运算, 计算数值梯度的速度特别慢
X = np.random.randn(N, 3, 16, 16)
y = np.random.randint(10, size=N)
model = ConvNetArch_1([(2,3)], [5,5], input_dim=(3, 16, 16), connect_conv=(2,3), use_batchnorm=True,
loss_fuction = 'softmax', weight_scale=5e-2, reg=0, dtype=np.float64)
loss, grads = model.loss(X, y)
for param_name in sorted(grads):
f = lambda _: model.loss(X, y)[0]
param_grad_num = eval_numerical_gradient(f, model.params[param_name], verbose=False, h=1e-6)
#print param_grad_num
e = rel_error(param_grad_num, grads[param_name])
print '%s max relative error: %e' % (param_name, rel_error(param_grad_num, grads[param_name]))
########################################################
Initial loss (no regularization): 2.8666209542
Initial loss (with regularization): 3.12124148165
CCW max relative error: 3.688953e-06
CW1 max relative error: 2.849567e-06
FW1 max relative error: 8.171128e-03
FW2 max relative error: 6.072839e-06
cb1 max relative error: 6.661434e-02
cbeta1 max relative error: 1.112161e-08
ccb max relative error: 4.440936e-01
ccbeta max relative error: 5.932733e-09
ccgamma max relative error: 7.900637e-09
cgamma1 max relative error: 3.363437e-09
fb1 max relative error: 3.552714e-07
fb2 max relative error: 7.993606e-07
fbeta1 max relative error: 6.106227e-08
fbeta2 max relative error: 5.441469e-10
fgamma1 max relative error: 3.206630e-09
fgamma2 max relative error: 9.478054e-10
### 程序运行太慢了,目前这个参数是试的第一组,效果还不错,第二轮迭代就达到50+%
### 跑了一晚上发现大约在第10次以后开始过拟合了,所以改为epoch=10,best_val_acc = 0.683,
### 之前epoch=20时,best_val_acc大概能到能到70%
### 在我电脑上,程序跑太慢,所以就没怎么调参数
### 考虑到这速度,下面这种结构就没有实现:
### [conv-relu-conv-relu-pool]xN - [affine]xM - [softmax or SVM]
### 目前可以实现下面两种结构:
### [conv-relu-pool]xN - conv - relu - [affine]xM - [softmax or SVM]
### [conv-relu-pool]XN - [affine]XM - [softmax or SVM]
model = ConvNetArch_1([(32,3),(64,3),(128,3)], [100], connect_conv=0, use_batchnorm=False,
loss_fuction = 'softmax', weight_scale=5e-2, reg=0, dtype=np.float64)
solver = Solver(model, data,
num_epochs=10, batch_size=100,
update_rule='adam',
optim_config={
'learning_rate': 1e-3
},
print_every=100,
lr_decay=0.95,
verbose=True)
solver.train()
print solver.best_val_acc(Iteration 1 / 4900) loss: 47.549210
(Epoch 0 / 10) train acc: 0.122000; val_acc: 0.124000
(Iteration 101 / 4900) loss: 1.889701
(Iteration 201 / 4900) loss: 1.628195
(Iteration 301 / 4900) loss: 1.503709
(Iteration 401 / 4900) loss: 1.284585
(Epoch 1 / 10) train acc: 0.497000; val_acc: 0.531000
(Iteration 501 / 4900) loss: 1.277860
(Iteration 601 / 4900) loss: 1.215424
(Iteration 701 / 4900) loss: 1.209591
(Iteration 801 / 4900) loss: 1.173904
(Iteration 901 / 4900) loss: 1.068132
(Epoch 2 / 10) train acc: 0.594000; val_acc: 0.580000
(Iteration 1001 / 4900) loss: 1.062385
(Iteration 1101 / 4900) loss: 1.080026
(Iteration 1201 / 4900) loss: 0.758866
(Iteration 1301 / 4900) loss: 0.818387
(Iteration 1401 / 4900) loss: 1.086589
(Epoch 3 / 10) train acc: 0.674000; val_acc: 0.616000
(Iteration 1501 / 4900) loss: 0.980248
(Iteration 1601 / 4900) loss: 0.964738
(Iteration 1701 / 4900) loss: 1.003369
(Iteration 1801 / 4900) loss: 0.974146
(Iteration 1901 / 4900) loss: 1.043093
(Epoch 4 / 10) train acc: 0.727000; val_acc: 0.645000
(Iteration 2001 / 4900) loss: 0.684164
(Iteration 2101 / 4900) loss: 0.899941
(Iteration 2201 / 4900) loss: 0.670452
(Iteration 2301 / 4900) loss: 0.715849
(Iteration 2401 / 4900) loss: 0.798524
(Epoch 5 / 10) train acc: 0.759000; val_acc: 0.661000
(Iteration 2501 / 4900) loss: 0.725618
(Iteration 2601 / 4900) loss: 0.702008
(Iteration 2701 / 4900) loss: 0.591424
(Iteration 2801 / 4900) loss: 0.943362
(Iteration 2901 / 4900) loss: 0.450685
(Epoch 6 / 10) train acc: 0.773000; val_acc: 0.674000
(Iteration 3001 / 4900) loss: 0.898413
(Iteration 3101 / 4900) loss: 0.627382
(Iteration 3201 / 4900) loss: 0.454569
(Iteration 3301 / 4900) loss: 0.446561
(Iteration 3401 / 4900) loss: 0.499366
(Epoch 7 / 10) train acc: 0.795000; val_acc: 0.667000
(Iteration 3501 / 4900) loss: 0.503052
(Iteration 3601 / 4900) loss: 0.408205
(Iteration 3701 / 4900) loss: 0.437030
(Iteration 3801 / 4900) loss: 0.510435
(Iteration 3901 / 4900) loss: 0.735819
(Epoch 8 / 10) train acc: 0.835000; val_acc: 0.678000
(Iteration 4001 / 4900) loss: 0.559391
(Iteration 4101 / 4900) loss: 0.451097
(Iteration 4201 / 4900) loss: 0.609639
(Iteration 4301 / 4900) loss: 0.549392
(Iteration 4401 / 4900) loss: 0.704371
(Epoch 9 / 10) train acc: 0.821000; val_acc: 0.682000
(Iteration 4501 / 4900) loss: 0.642858
(Iteration 4601 / 4900) loss: 0.502988
(Iteration 4701 / 4900) loss: 0.418752
(Iteration 4801 / 4900) loss: 0.306134
(Epoch 10 / 10) train acc: 0.842000; val_acc: 0.683000
0.683
print
plt.subplot(2, 1, 1)
plt.title('Training loss')
plt.plot(solver.loss_history, 'o')
plt.xlabel('Iteration')
plt.subplot(2, 1, 2)
plt.title('Accuracy')
plt.plot(solver.train_acc_history, '-o', label='train')
plt.plot(solver.val_acc_history, '-o', label='val')
plt.plot([0.5] * len(solver.val_acc_history), 'k--')
plt.xlabel('Epoch')
plt.legend(loc='lower right')
plt.gcf().set_size_inches(15, 12)
plt.show()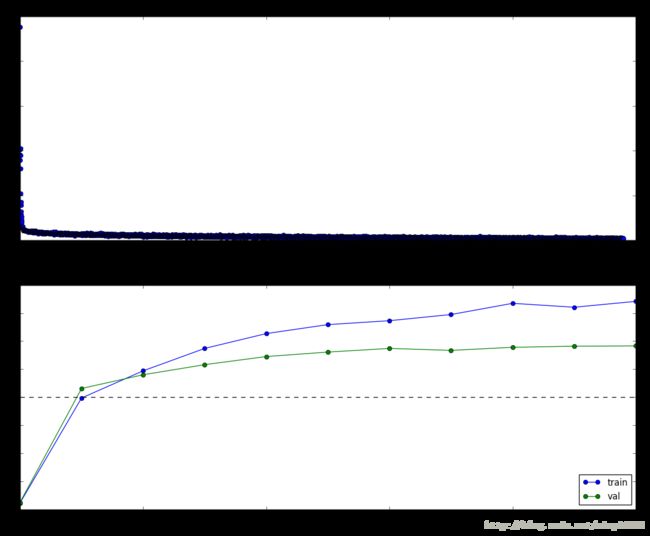
Extra Credit Description
If you implement any additional features for extra credit, clearly describe them here with pointers to any code in this or other files if applicable.