- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
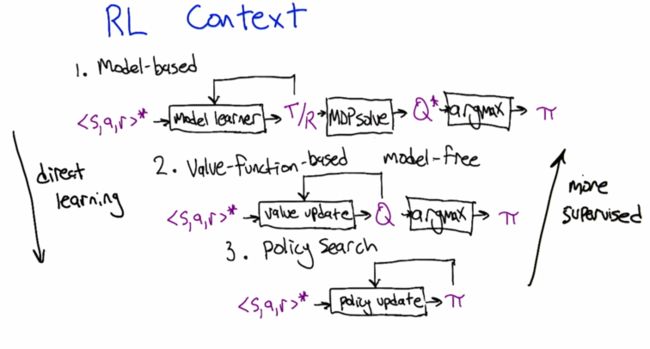
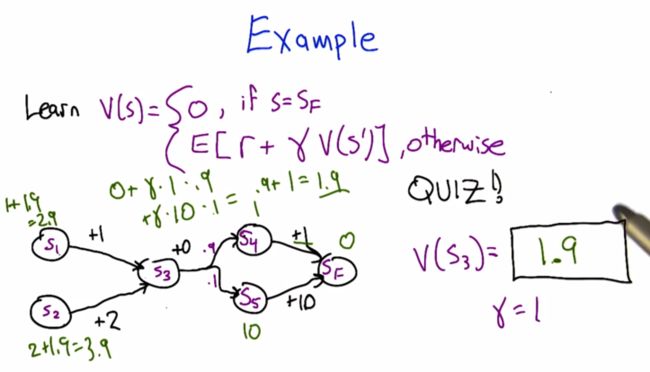
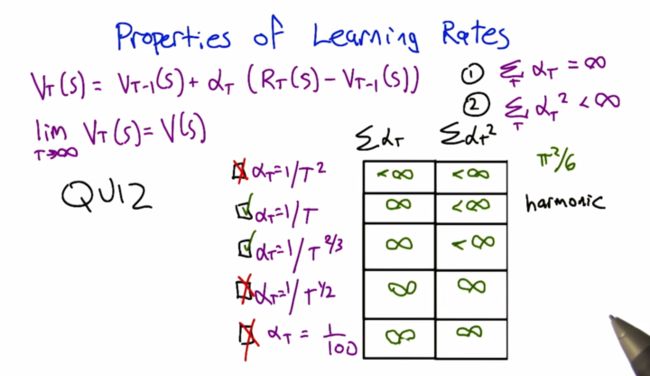
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说
造命者说
底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说我叫吴起,生于公元前440年的战国初期,正是群雄并起、天下纷争不断的时候。后人说我是军事家、政治家、改革家,是兵家代表人物。评价我一生历仕鲁、魏、楚三国,通晓兵家、法家、儒家三家思想,在内政军事上都有极高的成就。周安王二十一年(公元前381年),因变法得罪守旧贵族,被人乱箭射死。我出生在卫国一个“家累万金”的富有家庭,从年轻时候起就不甘平凡
- 30天风格练习-DAY2
黄希夷
Day2(重义)在一个周日/一周的最后一天,我来到位于市中心/市区繁华地带的一家购物中心/商场,中心内人很多/熙熙攘攘。我注意到/看见一个独行/孤身一人的年轻女孩/,留着一头引人注目/长过腰际的头发,上身穿一件暗红色/比正红色更深的衣服/穿在身体上的东西。走下扶梯的时候,她摔倒了/跌向地面,在她正要站起来/让身体离开地面的时候,过长/超过一般人长度的头发被支撑身体/躯干的手掌压/按在下面,她赶紧用
- 第四天旅游线路预览——从换乘中心到喀纳斯湖
陟彼高冈yu
基于Googleearthstudio的旅游规划和预览旅游
第四天:从贾登峪到喀纳斯风景区入口,晚上住宿贾登峪;换乘中心有4路车,喀纳斯①号车,去喀纳斯湖,路程时长约5分钟;将上面的的行程安排进行动态展示,具体步骤见”Googleearthstudio进行动态轨迹显示制作过程“、“Googleearthstudio入门教程”和“Googleearthstudio进阶教程“相关内容,得到行程如下所示:Day4-2-480p
- 18-115 一切思考不能有效转化为行动,都TM是扯淡!
成长时间线
7月25号写了一篇关于为什么会断更如此严重的反思,然而,之后日更仅仅维持了一周,又出现了这次更严重的现象。从8月2号到昨天8月6号,5天!又是5天没有更文!虽然这次断更时间和上次一样,那为什么说这次更严重?因为上次之后就分析了问题的原因,以及应该如何解决,按理说应该会好转,然而,没过几天严重断更的现象再次出现,想想,经过反思,问题依然没有解决与改变,这让我有些担忧。到底是哪里出了问题,难道我就真的
- 蘩漪:新女性?利己主义者
赮_红雨
蘩漪是曹禺《雷雨》笔下的女性形象。对于她的喜爱,曹禺在之前的访谈中,就已经表达得很清楚了,蘩漪是他所倾心的女子的“代替者”。在这个女性身上有着曹禺最精心的描写,但同时她的身上又存在着一些时代的问题。图片发自App首先,繁漪是追求自由和幸福的新女性形象。她是精神悲剧的核心人物,她对周朴园的反抗,具有典型意义。她是位资产阶级家庭出身的小姐,受过五四新思潮的影响,她任性、傲慢,追求人格独立、个性自由和爱
- 读《人世间》有感
一0一
这个寒假,就如同朋友圈中的一段话:一闭眼,一睁眼假期还有5天,在一闭眼一睁眼假期还有12天;再一闭眼一睁眼假期还有20天;不敢睡,不敢睡啊……受疫情影响,这个假期变得漫长又煎熬,我也无时无刻不关注着疫情的变化。当然这样的一个假期,我还真得要感谢周翔,因为他有个爱看书的习惯,所以家里有不少他看过的书,可以让我随意挑选,因此也让我的假期不至于那么无所事事。这次我选了一本梁晓声的《人世间》,作为一名语文
- 运城寻访重逢石头纪实【严建设老照片395 集】 我简直能把你想透, 当我走进运城的时候。 我已急得热汗直流, 访问了十九个老头, 把晋南的小城转了三周。 虽然是悠久的思旧, 我仍然是牛样的执...
严建设
运城寻访重逢石头纪实【严建设老照片395集】我简直能把你想透,当我走进运城的时候。我已急得热汗直流,访问了十九个老头,把晋南的小城转了三周。虽然是悠久的思旧,我仍然是牛样的执拗。说什么变换的世情,泛起了过去的逝流,你就是真正的故友。踏破铁鞋的淡愁,已化为不废功夫的范畴,是就像远在天涯近在咫尺,就像是梦乡的邂逅,我紧紧地攥着你的手。你已长成了高高的个头,俊逸的容颜却很清瘦,你那样顽皮的童音,已变到老
- 东南林氏之九牧林候选父系
祖缘树TheYtree
渊源介绍东晋初年晋安林始祖林禄公入闽,传十世隋右丞林茂,由晋安迁居莆田北螺村。又五世而至林万宠,唐开元间任高平太守,生三子:韬、披、昌。韬公之孙攒,唐德宗立双阙以旌表其孝,时号"阙下林家"。昌公字茂吉,乃万宠公第三子,官兵部司马,配宋氏,生一子名萍。萍于唐贞元间明经及第,官沣洲司马(后追赠中宪大夫)。唐太和年间归隐后,迁居仙游游洋,世称“游洋林”;其后裔居游洋后迁移漳州漳浦路下,由路下林第四房平和
- ARM中断处理过程
落汤老狗
嵌入式linux
一、前言本文主要以ARM体系结构下的中断处理为例,讲述整个中断处理过程中的硬件行为和软件动作。具体整个处理过程分成三个步骤来描述:1、第二章描述了中断处理的准备过程2、第三章描述了当发生中的时候,ARM硬件的行为3、第四章描述了ARM的中断进入过程4、第五章描述了ARM的中断退出过程本文涉及的代码来自3.14内核。另外,本文注意描述ARM指令集的内容,有些sourcecode为了简短一些,删除了T
- 阶段总结反思
轻争
马上就要进入10月份了,今天做一下前段时间的总结和反思。前段时间,日更、英语、健身、护肤坚持的比较好。阅读、书法坚持的不好。1.中间被迫停更半个多月,其余时间一直在坚持日更挑战。偶尔也有不想写的时候,就做一下摘抄。因为阅读(输入)没跟上来,所以写作(输出)质量有待进一步加强。2.英语做到了一周至少学习5天,每次不少于30分钟,但是小班课没有跟上更新速度,下一步要争取利用零碎时间补听小班课。3.减肥
- 展现思维导图魅力,不断挖掘人生宝藏
思维导图讲师Mandy
第13期最强思维导图训练营已经结束一周了,但是我依旧是感觉所有学员还在努力的学习,这些学员中有教师、学生、白领、公务员、宝妈等等,只要你努力,只要你想改变自己,任何行业,任何岗位都可以参与进来,28天足以让你见成效,在这28天中,我们的学员不仅仅是收获了一枚毕业证,最重要的是让自己的思维方式得到升级,今天的你为自己投资,明天的你就会感谢你今天的付出,我们来听一听来自13期最强思维导图训练营优秀学员
- C++菜鸟教程 - 从入门到精通 第二节
DreamByte
c++
一.上节课的补充(数据类型)1.前言继上节课,我们主要讲解了输入,输出和运算符,我们现在来补充一下数据类型的知识上节课遗漏了这个知识点,非常的抱歉顺便说一下,博主要上高中了,更新会慢,2-4周更新一次对了,正好赶上中秋节,小编跟大家说一句:中秋节快乐!2.int类型上节课,我们其实只用了int类型int类型,是整数类型,它们存贮的是整数,不能存小数(浮点数)定义变量的方式很简单inta;//定义一
- 第四天旅游线路预览——从贾登峪到喀纳斯景区入口(贾登峪游客服务中心)
陟彼高冈yu
基于Googleearthstudio的旅游规划和预览旅游
第四天:从贾登峪到喀纳斯风景区入口,晚上住宿贾登峪;从贾登峪到喀纳斯景区入口(贾登峪游客服务中心):搭乘贾登峪①路车,路过三湾到达景区换乘中心,路程时长约40分钟;1)早上8:00起床,吃完早饭,8:30出发;2)从贾登峪到喀纳斯风景区,需要搭乘一站公交车,为免费公交车,路程4.3公里,车程约9分钟8:40左右到达喀纳斯景区入口(贾登峪游客服务中心);3)乘坐贾登峪①路车,路过三湾到达景区换乘中心
- 《在战“疫”中成长致敬生活》观后感
梅子刘的刀
(作者:周晨)今天上午,我看了“我是接班人”网络大课堂《在战役中成长致敬生活》。有很多人拿出自己攒下的钱,默默地捐给了武汉,有几千块钱的、有几万块钱的,也有十几万块钱的。连小朋友也把自己的压岁钱捐给了武汉。有名环卫工人把自己五年的积蓄全部捐给了武汉。有名外卖小哥为医护人员买鞋子送吃的。还有已经治愈出院的新型肺炎病人捐了400毫升的血浆。还有位叫大树的叔叔,虽然他没有钱,但是他地里有蔬菜,捐了几大卡
- 2019-10-24
柒月的可可
今日上班无事,人又懒怠动,不知道如何打发这个下午,终于打开了。我大概是把当日记来写的。重庆的天气骤然凉了。早上出门的时候,满地都是落叶,脚踩上去,却是刚下过雨,叶子已润掉,走不出声响。白天在办公室不见天日,对温度也无甚感觉,晚上一个人回到家,屋子里窗户都开着,被冷风吹了一天,一迈进屋,便觉冷气森然。将近二十度的天气,竟要裹着毯子才觉温暖。再过一周,就到十一月。扛过十一月,就可以开暖气了。然而我真的
- 南美洲的奇特艺术品【神秘档案馆·第三期】
清风小和尚
本期回答问题:1.复活节岛石像是谁建造的?2.复活节岛石像的建造方法与目的?3.纳斯卡线条的设计意义?南美洲是南亚美利加洲的简称,位于西半球的南部,东濒大西洋,西临太平洋,北滨加勒比海,南隔德雷克海峡与南极洲相望。对南美洲最简单的定位方法是:美国南面。南美洲是地球上第四大的大洲,有着种类繁多的物种和丰富的地形。在这片广袤的土地上,有两样奇特的艺术品---复活节岛摩艾石像与纳斯卡线条。摩艾石像(Mo
- 读书为什么这么难,听拆书帮赵周怎么说。
董小萌读书
赵周的《这样读书就够了》提炼了成年人读书难的三个问题。问题一:没时间、没精力这是压力与学习的矛盾问题二:看不懂、记不住这是搞错了学习主体其实,我们大多数人在学习主体是谁的问题一直都很模糊。问题三:看不下去这是学习目的不明确,说白了就是不知道为啥而看。也许你会觉得这话有点一竿子打死一片的劲头。不急着反驳,可以回忆一下,哪本书,哪类书,是你曾经读完了,并在脑海中至今还留下痕迹的?是的。成年人的读书,是
- 2023.5.10 周三 早7:38
努力逆流而上
榜样的力量前一段时间追一个《一生一世》的电视剧,脑残剧,但居中的周生辰,稳重。润玉一般的性格,坚持着10年如一日的自律习惯,养成的性格也是这样温文尔雅,虽然是剧中塑造,但我感觉现实中一定是有的,让我觉得人生就是这样的修行,自律不是强迫自己,是形成的习惯,坚持的习惯!结果五一回家,太无聊,看了韩剧的《继承者》让孩子也跟着一起看手机,昨天跑了步,但发现没有很快乐,不知道起的太晚还是怎么着,7点的大街上
- 我与《红楼梦》‖纪念曹雪芹出生307周年!归海逸舟是周成功子阳佳乐
归海逸舟是周成功子阳佳乐
【今日作家推荐】中国古典小说之首《红楼梦》,其作者曹雪芹是文坛泰斗。约1715年5月28日,曹雪芹出生。所以,今天推荐的是中国人众所周知的作家——曹雪芹。曹雪芹在世界读者心目中也影响广大,可以与西方世界引以为豪的莎士比亚、歌德等媲美。1、我与《红楼梦》我一直想写一篇和《红楼梦》相关的文章,现在机会终于来了!《红楼梦》作为我国家喻户晓的文学名著,其影响是空前的。还在我很小的时候,姥姥经常讲《红楼梦》
- 2019考研 | 西交大软件工程
笔者阿蓉
本科背景:某北京211学校电子信息工程互联网开发工作两年录取结果:全日制软件工程学院分数:初试350+复试笔试80+面试85+总排名:100+从五月份开始脱产学习,我主要说一下专业课和复试还有我对非全的一些看法。【数学100+】张宇,张宇,张宇。跟着张宇学习,入门视频刷一遍,真题刷两遍,错题刷三遍。书刷N多遍。从视频开始学习,是最快的学习方法。5-7月份把主要是数学学好,8-9月份开始给自己每个周
- 张芝华49天共修 - 草稿
李娟AINI
祈禱、靜心、源代碼編程、觀想發願四根支柱,運用靈性能量的助力,讓夢想和渴望在最大向度中輕鬆實現。共修群指定书籍:1.能断金刚麦克格西2.新世界:灵性的觉醒埃克哈特·托尔3.爱是一切的答案芭芭拉迪安吉莉思4.完美的爱,不完美的关系约翰•威尔伍德5.爱的业力法则麦克格西6.漫画《金刚经》蔡志忠7.蔡志忠典藏国学漫画系列(套装共6册)作业:全部在共修群里完成,并请保存好自己的作业。l一周三次共修觉察作业
- 今日有感,坚持分享第913天,2019.07.13
ZAF峰回路转
本周是假日里最忙碌的一周,连续四天晚上的课程,让我感觉到身体明显透支。昨天晚上读书会结束回到家,已经是十点半之后啦,忽然感觉身体不舒服,勉强支撑着洗漱完毕,没等上床休息,强烈的不适感警告我该吃药啦!感谢老公半夜到医院給我抓了药,今天早上当我对老公表达谢意的时候,老公说,不用感谢,我不是一直都是这样做的吗?多少年啦,今天竟然还谢谢!老公说的没错,可是以前总感觉那是他应该做的,如今感觉到,身边有一个在
- 准备
胡珊珊乐平九小
尊敬的各位领导、各位同仁们:大家上午好!我是来自乐平九小的胡珊珊。今天很高兴能有机会给大家做“智慧作业”应用培训。说到“智慧作业”我感触颇多,我是在智慧作业中成长起来的,我也时常以自己是一名“智慧作业人”自居。早在2020年疫情期间,学校电教处周光杰主任在学校群里发出智慧作业抢题通知,我看了有些心动,一节微课相当于一次省级公开课,这对于我们普通老师是多么难得的机会啊。但想归想,我也不会用软件啊,再
- 阅读《认知觉醒》读书笔记
就看看书
本周阅读了周岭的《认知觉醒开启自我改变的原动力》,启发较多,故做读书笔记一则,留待学习。全书共八章,讲述了大脑、潜意识、元认知、专注力、学习力、行动力、情绪力及成本最低的成长之道。具体描述了大脑、焦虑、耐心、模糊、感性、元认知、自控力、专注力、情绪专注、学习专注、匹配、深度、关联、体系、打卡、反馈、休息、清晰、傻瓜、行动、心智宽带、单一视角、游戏心态、早起、冥想、阅读、写作、运动等相关知识点。大脑
- 圣诞节后的人气又回来了?好丽友、特斯拉们的生意却不好做| 每周热点汇总
饭Sir看天下
新的一年来了大家好,今天是2022年12月26日,星期一,农历十二月初四。这个月,相信我们很多人都遇到了身体不适的情况,饭Sir上周也因为发烧不得不停更了一周,这几天才刚刚恢复,好在这一切最后都能过去。疫情之外,一些好消息也逐渐到来,例如北京等多座大城市在年底的圣诞节期间又恢复了生机,一些迹象也在预示着久违的热闹春节要回来了。但另一方面,明年不确定的经济形势又带来一些不利的消息,不禁让人有些担心。
- 《跃迁》5/7-5组-橙子-张静12.16
静言物于
【便签5】【片段来源】《跃迁:成为高手的技术》第四章【R原文】一位客户咨询时抱怨:“这个我做不到。”我问他:“如果我请你现在出去裸奔,你能做到吗?”“这个我也做不到”“其实并不是做不到,而是不愿意做,或者不想承担裸奔的代价吧。你不是做不到,而是选择不去做。如果有一天你裸奔能救自己家人、孩子,也许就能做到了。”为什么要做这个区分?如果一个人经常和自己说“做不到”,他的能力范围会越来越小,会成为一个无
- 《流年一曲成殇》连载47
方冷颜
第四十七章青葱岁月宋曲殇躺在床上,看着寝室的灯已经熄灭了,在上铺的好处大概就是可以看到窗外的景。军训基地在郊区,所以自然环境特别的好,是没有受到污染的地区,晚上真的可以看到满天繁星。一轮弯月挂在天空,月光透过窗户,照在窗外的柏树上,那挺拔的柏树像守卫银河系的战士。宋晟波的舞,就像电影的回放,让她大吃一惊。生活中似乎充满着惊喜,发现,就是一种惊喜。付流年的歌究竟是什么?她好想找个有网络的地方搜一番。
- 孕妈必备:怀孕第一周孕妈和准爸爸需要知道的那些事儿
张女子育儿
对于新婚夫妻来说,怀孕第一周准妈妈和准爸爸都会感觉到既惊喜又有点不知所措吧!怀孕第一周孕妈有什么反应,怀孕第一周孕妈需要注意的事情有哪些呢?准爸爸又该如何照顾孕妇及其为孩子做些什么呢?今日小编就和大家说说怀孕第一周的诸多问题,让孕妈和准爸爸做好准备。怀孕第一周该如何计算呢?人们通常都说准妈妈要“怀胎10月”,但实际上按照阳历计算的话,胎儿在妈妈子宫内生活的时间是没有10个月的。准妈妈得知自己怀孕,
- 7月结束了
摸不着的小鱼
这日子快得让人看不见、摸不着,也是真的太快了点吧!一眨眼我已经辞去第二份工作两个多月了!在这两个月里真的是做了好多好多事,有自己小试牛刀的“创业”,也有辛酸在家带娃的三个周……时间带不走的永远看不见,时间能带走的都是我们所见所闻的东西……前一个月感觉都是在荒废时间吧,也没有找到自己的定位,一次又一次的更替和改变,我越发觉得自己不清楚自己所要的东西是什么了?后面一个多月的时间里就是磨练耐心了,全程带
- ASM系列六 利用TreeApi 添加和移除类成员
lijingyao8206
jvm动态代理ASM字节码技术TreeAPI
同生成的做法一样,添加和移除类成员只要去修改fields和methods中的元素即可。这里我们拿一个简单的类做例子,下面这个Task类,我们来移除isNeedRemove方法,并且添加一个int 类型的addedField属性。
package asm.core;
/**
* Created by yunshen.ljy on 2015/6/
- Springmvc-权限设计
bee1314
springWebjsp
万丈高楼平地起。
权限管理对于管理系统而言已经是标配中的标配了吧,对于我等俗人更是不能免俗。同时就目前的项目状况而言,我们还不需要那么高大上的开源的解决方案,如Spring Security,Shiro。小伙伴一致决定我们还是从基本的功能迭代起来吧。
目标:
1.实现权限的管理(CRUD)
2.实现部门管理 (CRUD)
3.实现人员的管理 (CRUD)
4.实现部门和权限
- 算法竞赛入门经典(第二版)第2章习题
CrazyMizzz
c算法
2.4.1 输出技巧
#include <stdio.h>
int
main()
{
int i, n;
scanf("%d", &n);
for (i = 1; i <= n; i++)
printf("%d\n", i);
return 0;
}
习题2-2 水仙花数(daffodil
- struts2中jsp自动跳转到Action
麦田的设计者
jspwebxmlstruts2自动跳转
1、在struts2的开发中,经常需要用户点击网页后就直接跳转到一个Action,执行Action里面的方法,利用mvc分层思想执行相应操作在界面上得到动态数据。毕竟用户不可能在地址栏里输入一个Action(不是专业人士)
2、<jsp:forward page="xxx.action" /> ,这个标签可以实现跳转,page的路径是相对地址,不同与jsp和j
- php 操作webservice实例
IT独行者
PHPwebservice
首先大家要简单了解了何谓webservice,接下来就做两个非常简单的例子,webservice还是逃不开server端与client端。我测试的环境为:apache2.2.11 php5.2.10做这个测试之前,要确认你的php配置文件中已经将soap扩展打开,即extension=php_soap.dll;
OK 现在我们来体验webservice
//server端 serve
- Windows下使用Vagrant安装linux系统
_wy_
windowsvagrant
准备工作:
下载安装 VirtualBox :https://www.virtualbox.org/
下载安装 Vagrant :http://www.vagrantup.com/
下载需要使用的 box :
官方提供的范例:http://files.vagrantup.com/precise32.box
还可以在 http://www.vagrantbox.es/
- 更改linux的文件拥有者及用户组(chown和chgrp)
无量
clinuxchgrpchown
本文(转)
http://blog.163.com/yanenshun@126/blog/static/128388169201203011157308/
http://ydlmlh.iteye.com/blog/1435157
一、基本使用:
使用chown命令可以修改文件或目录所属的用户:
命令
- linux下抓包工具
矮蛋蛋
linux
原文地址:
http://blog.chinaunix.net/uid-23670869-id-2610683.html
tcpdump -nn -vv -X udp port 8888
上面命令是抓取udp包、端口为8888
netstat -tln 命令是用来查看linux的端口使用情况
13 . 列出所有的网络连接
lsof -i
14. 列出所有tcp 网络连接信息
l
- 我觉得mybatis是垃圾!:“每一个用mybatis的男纸,你伤不起”
alafqq
mybatis
最近看了
每一个用mybatis的男纸,你伤不起
原文地址 :http://www.iteye.com/topic/1073938
发表一下个人看法。欢迎大神拍砖;
个人一直使用的是Ibatis框架,公司对其进行过小小的改良;
最近换了公司,要使用新的框架。听说mybatis不错;就对其进行了部分的研究;
发现多了一个mapper层;个人感觉就是个dao;
- 解决java数据交换之谜
百合不是茶
数据交换
交换两个数字的方法有以下三种 ,其中第一种最常用
/*
输出最小的一个数
*/
public class jiaohuan1 {
public static void main(String[] args) {
int a =4;
int b = 3;
if(a<b){
// 第一种交换方式
int tmep =
- 渐变显示
bijian1013
JavaScript
<style type="text/css">
#wxf {
FILTER: progid:DXImageTransform.Microsoft.Gradient(GradientType=0, StartColorStr=#ffffff, EndColorStr=#97FF98);
height: 25px;
}
</style>
- 探索JUnit4扩展:断言语法assertThat
bijian1013
java单元测试assertThat
一.概述
JUnit 设计的目的就是有效地抓住编程人员写代码的意图,然后快速检查他们的代码是否与他们的意图相匹配。 JUnit 发展至今,版本不停的翻新,但是所有版本都一致致力于解决一个问题,那就是如何发现编程人员的代码意图,并且如何使得编程人员更加容易地表达他们的代码意图。JUnit 4.4 也是为了如何能够
- 【Gson三】Gson解析{"data":{"IM":["MSN","QQ","Gtalk"]}}
bit1129
gson
如何把如下简单的JSON字符串反序列化为Java的POJO对象?
{"data":{"IM":["MSN","QQ","Gtalk"]}}
下面的POJO类Model无法完成正确的解析:
import com.google.gson.Gson;
- 【Kafka九】Kafka High Level API vs. Low Level API
bit1129
kafka
1. Kafka提供了两种Consumer API
High Level Consumer API
Low Level Consumer API(Kafka诡异的称之为Simple Consumer API,实际上非常复杂)
在选用哪种Consumer API时,首先要弄清楚这两种API的工作原理,能做什么不能做什么,能做的话怎么做的以及用的时候,有哪些可能的问题
- 在nginx中集成lua脚本:添加自定义Http头,封IP等
ronin47
nginx lua
Lua是一个可以嵌入到Nginx配置文件中的动态脚本语言,从而可以在Nginx请求处理的任何阶段执行各种Lua代码。刚开始我们只是用Lua 把请求路由到后端服务器,但是它对我们架构的作用超出了我们的预期。下面就讲讲我们所做的工作。 强制搜索引擎只索引mixlr.com
Google把子域名当作完全独立的网站,我们不希望爬虫抓取子域名的页面,降低我们的Page rank。
location /{
- java-归并排序
bylijinnan
java
import java.util.Arrays;
public class MergeSort {
public static void main(String[] args) {
int[] a={20,1,3,8,5,9,4,25};
mergeSort(a,0,a.length-1);
System.out.println(Arrays.to
- Netty源码学习-CompositeChannelBuffer
bylijinnan
javanetty
CompositeChannelBuffer体现了Netty的“Transparent Zero Copy”
查看API(
http://docs.jboss.org/netty/3.2/api/org/jboss/netty/buffer/package-summary.html#package_description)
可以看到,所谓“Transparent Zero Copy”是通
- Android中给Activity添加返回键
hotsunshine
Activity
// this need android:minSdkVersion="11"
getActionBar().setDisplayHomeAsUpEnabled(true);
@Override
public boolean onOptionsItemSelected(MenuItem item) {
- 静态页面传参
ctrain
静态
$(document).ready(function () {
var request = {
QueryString :
function (val) {
var uri = window.location.search;
var re = new RegExp("" + val + "=([^&?]*)", &
- Windows中查找某个目录下的所有文件中包含某个字符串的命令
daizj
windows查找某个目录下的所有文件包含某个字符串
findstr可以完成这个工作。
[html]
view plain
copy
>findstr /s /i "string" *.*
上面的命令表示,当前目录以及当前目录的所有子目录下的所有文件中查找"string&qu
- 改善程序代码质量的一些技巧
dcj3sjt126com
编程PHP重构
有很多理由都能说明为什么我们应该写出清晰、可读性好的程序。最重要的一点,程序你只写一次,但以后会无数次的阅读。当你第二天回头来看你的代码 时,你就要开始阅读它了。当你把代码拿给其他人看时,他必须阅读你的代码。因此,在编写时多花一点时间,你会在阅读它时节省大量的时间。让我们看一些基本的编程技巧: 尽量保持方法简短 尽管很多人都遵
- SharedPreferences对数据的存储
dcj3sjt126com
SharedPreferences简介: &nbs
- linux复习笔记之bash shell (2) bash基础
eksliang
bashbash shell
转载请出自出处:
http://eksliang.iteye.com/blog/2104329
1.影响显示结果的语系变量(locale)
1.1locale这个命令就是查看当前系统支持多少种语系,命令使用如下:
[root@localhost shell]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
- Android零碎知识总结
gqdy365
android
1、CopyOnWriteArrayList add(E) 和remove(int index)都是对新的数组进行修改和新增。所以在多线程操作时不会出现java.util.ConcurrentModificationException错误。
所以最后得出结论:CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。发生修改时候做copy,新老版本分离,保证读的高
- HoverTree.Model.ArticleSelect类的作用
hvt
Web.netC#hovertreeasp.net
ArticleSelect类在命名空间HoverTree.Model中可以认为是文章查询条件类,用于存放查询文章时的条件,例如HvtId就是文章的id。HvtIsShow就是文章的显示属性,当为-1是,该条件不产生作用,当为0时,查询不公开显示的文章,当为1时查询公开显示的文章。HvtIsHome则为是否在首页显示。HoverTree系统源码完全开放,开发环境为Visual Studio 2013
- PHP 判断是否使用代理 PHP Proxy Detector
天梯梦
proxy
1. php 类
I found this class looking for something else actually but I remembered I needed some while ago something similar and I never found one. I'm sure it will help a lot of developers who try to
- apache的math库中的回归——regression(翻译)
lvdccyb
Mathapache
这个Math库,虽然不向weka那样专业的ML库,但是用户友好,易用。
多元线性回归,协方差和相关性(皮尔逊和斯皮尔曼),分布测试(假设检验,t,卡方,G),统计。
数学库中还包含,Cholesky,LU,SVD,QR,特征根分解,真不错。
基本覆盖了:线代,统计,矩阵,
最优化理论
曲线拟合
常微分方程
遗传算法(GA),
还有3维的运算。。。
- 基础数据结构和算法十三:Undirected Graphs (2)
sunwinner
Algorithm
Design pattern for graph processing.
Since we consider a large number of graph-processing algorithms, our initial design goal is to decouple our implementations from the graph representation
- 云计算平台最重要的五项技术
sumapp
云计算云平台智城云
云计算平台最重要的五项技术
1、云服务器
云服务器提供简单高效,处理能力可弹性伸缩的计算服务,支持国内领先的云计算技术和大规模分布存储技术,使您的系统更稳定、数据更安全、传输更快速、部署更灵活。
特性
机型丰富
通过高性能服务器虚拟化为云服务器,提供丰富配置类型虚拟机,极大简化数据存储、数据库搭建、web服务器搭建等工作;
仅需要几分钟,根据CP
- 《京东技术解密》有奖试读获奖名单公布
ITeye管理员
活动
ITeye携手博文视点举办的12月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。
12月试读活动回顾:
http://webmaster.iteye.com/blog/2164754
本次技术图书试读活动获奖名单及相应作品如下:
一等奖(两名)
Microhardest:http://microhardest.ite