Go语言入门——基础语法篇(二)
文章目录
- 基础语法
- 注释
- 变量
- 变量声明
- 初始化
- 多变量赋值
- 常量
- 枚举
- 数据类型
- 字符
- 字符串
- 数组
- 切片
- 从数组创建切片
- 直接创建切片
- 切片的操作
- 字典/映射
- 分支与循环
- if 分支
- switch 分支
- goto 跳转
- 循环
- 函数
- 定义函数
- 函数的不定参
- 匿名函数与闭包
- 闭包
- 函数做为参数传递
- Go语言函数使用小结
- 包
- 自定义包
- 包的几种导入方式
- 包的初始化函数
- Go语言的入口
- 欢迎关注我的公众号:编程之路从0到1
基础语法
Go的语句是可以省略;结束符的,且每行尽可能只写一句代码,这是Go语言的编程范式,因此应遵循规范,不要加分号。分号只在一种情况下是必须的,当一行写了多个代码语句,则每个语句必须使用分号分隔。
注释
Go语言有两种注释方式,基本来自于我们熟悉的C或Java中的注释方式
// 单行注释
/*
* 多行注释
*/
变量
Go与以往的C系列编程语言(Java、C#、C++等)最大的一个不同,就是其声明变量时,类型定义在变量名之后,对于C系列的程序员而言,开始的时候会非常别扭,与我们以往的编程习惯是反的,不过熟悉之后也就习惯成自然了。
就我个人感觉,我认为Go语言的语法是一个大杂烩,主要在C语言的基础上,吸收融合了Python、Java的某些语法特点,并做了一些创新,当然,也能看到一点JavaScript的影子。因此,拥有C、Java、Python技术背景的人,总能从Go中找到熟悉的感觉。以上三种编程语言中,掌握任意一种或两种,那么学习Go语言都会轻而易举,甚至可以说易如反掌。
变量声明
使用关键字var,并将类型放在变量名之后
var v1 int //整型变量
var v2 string //字符串变量
var v3 [10]int // 数组
var v4 []int // 切片
var v6 *int // 指针
var v7 map[string]int // map,key为string类型,value为int类型
// 声明结构体变量v5
var v5 struct {
f int
}
// 声明函数签名
var v8 func(a int) int
我们知道在C语言中,变量声明后必须初始化再使用,否则变量会带有随机的值。Go语言的编译器则会在声明变量时对变量做零值初始化,这一点正解决了C语言的缺陷
package main
import "fmt"
func main() {
var v1 int
var v2 string
var v3 [10]int
var v4 []int
fmt.Printf("%d,%s,%d,%p\n",v1,v2,v3,v4)
}
打印结果:
0,,[0 0 0 0 0 0 0 0 0 0],0x0
字符串的零值是一个空字符串"",而数组则是已经开辟了空间,且每个元素的值都是零值,指针的零值是则0,这里v4变量的类型是切片,实际上就是一个指针。
同时声明多个变量
// 不同类型
var (
v1 int
v2 string
)
// 相同类型
var i, j, k int
初始化
使用
:=操作符,可以做短变量声明。
var v1 int = 10 // 声明变量的同时初始化
var v2 = 10 // 让编译器自动推导类型
v3 := 10 // 省略关键字var和类型,让其自动推导类型
Go语言的语法吸收了很多动态语言的特点,例如我们在Python中声明变量,不需要使用任何关键字和类型定义,而在Go中也提供了类似的机制,这就是使用:= 操作符做短变量声明。如上例v3 := 10,编译器会根据所赋的值自动推导出v3变量的类型,这是Go中变量声明最简洁的表达语法。
多变量赋值
// 先声明,再赋值
var i, j, k int
i, j, k = 2, 3, 4
// 声明的同时赋值,注意使用":="操作符
l, m, n := 7, 8, 9
常量
使用const关键字声明常量,声明常量时也可以省略类型定义,如果想要明确具体类型,提高代码可读性,也可以显式指定类型
const Pi float64 = 3.14159265358979323846
const zero = 0.0 // 浮点常量
const (
size int64 = 1024
eof = -1 // 整型常量
)
// u = 0.0, v = 3.0,常量的多重赋值
const u, v float32 = 0, 3
// a = 3, b = 4, c = "foo", 无类型整型和字符串常量
const a, b, c = 3, 4, "foo"
// 常量定义的右值可以是一个编译期运算的常量表达式
const mask = 1 << 3
枚举
枚举指一系列相关的常量,比如下面关于一个星期中每天的定义。同Go语言的其他符号一样,以大写字母开头的常量在包外可见
// Go语言中实际上是用整型常量替代枚举
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
我们可以观察一下结果
func main() {
fmt.Printf("%d,%d,%d,%d\n",Sunday,Monday,Tuesday,Wednesday)
}
打印结果:
0,1,2,3
其值是从0开始的自然数列
数据类型
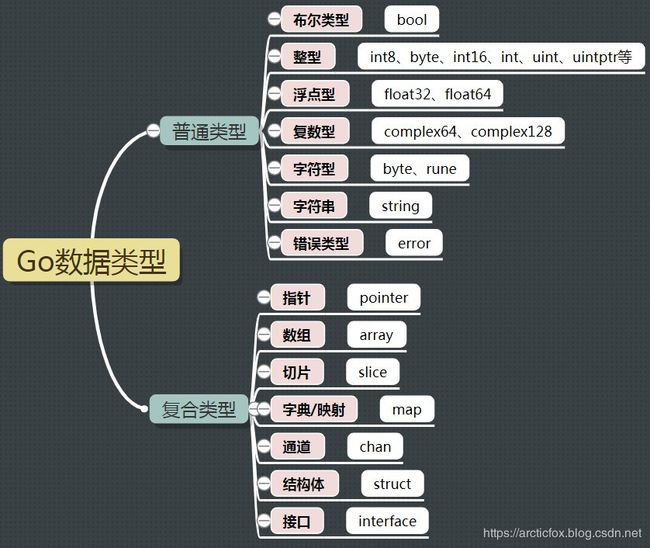
字符
Go语言中有两种字符类型,分别是byte和rune。byte类型就相当于C语言中的char,表示的是单字节字符,如ASCII码,如果是中文这种,单字节是无法表示的,就需要多个字节一起来表示。而rune类型则是专门用来表示Unicode字符的,它相当于C语言中的所谓宽字符,即wchar,单个rune就能表示一个中文。具体区别在以下字符串一小结说明。
字符串
Go语言的作者也是UTF-8编码的发明者,毫无疑问,Go语言的源代码默认的编码方式就是UTF-8,如同Python3与Python2的区别一样,我们可以在源代码中直接书写中文字面量。
// 声明并初始化字符串变量
var str1 string = "这是中文"
var str2 string = "are you ok?"
// 字符串拼接
str3 := str1 + str2
Go语言吸收了Python中字符串切片的语法,使得对字符串的截取操作变得异常赏心悦目
var str1 string = "believe in whatever my love has said to me"
// 要特别注意,字符串切片返回的依然是string类型
fmt.Println(str1[0:5])
切片的具体语法请参看后面切片小节,需要注意的是,不要对中文字符串直接切片操作,会返回乱码。这是因为Go语言默认编码是UTF-8,这是一种多字节编码,通常它使用3个byte来表示一个中文,而字符串切片切的就是byte,中文直接切片破坏了每三个byte一组的完整性。如需对中文字符串切片,必须先强制转换为[]rune类型
func main() {
var str1 string = "你看这碗又大又圆,你看这面又长又宽"
runeStr := []rune(str1)
// 转换为[]rune类型后才能切片操作,s
// 且操作后还需再次转为string类型才能打印
fmt.Println(string(runeStr[0:5]))
}
Go语言中还支持一种反引号括起来的字符串,该字符串可以包含多行和特殊字符,双引号括起来的字符串遇特殊字符需转义,用反引号则不需要
func main() {
str1 := `golang
java`
var str2 string = `string\n\t\r`
fmt.Println(str1)
fmt.Println(str2)
}
实际上就等同于Python中的三引号括起来的字符串,这是一种原始字符串,它会包含字面量中的格式,即换行和特殊字符。
数组
数组是一个具有
相同数据类型的元素组成的固定长度的有序集合。数组中包含的每个数据称为数组元素,包含的元素个数称为数组长度。
在Go语言中,数组是值类型,长度是类型的组成部分,也就是说[10]int和[20]int是完全不同的两种数组类型。
package main
import "fmt"
func main() {
// 数组声明
var a [5]int
fmt.Println("emp:", a)
// 使用数组索引(下标)操作元素
a[4] = 100
fmt.Println("set:", a)
fmt.Println("get:", a[4])
// 使用内置的len函数获取数组的长度
fmt.Println("len:", len(a))
// 声明并初始化一个数组的写法
b := [5]int{1, 2, 3, 4, 5}
fmt.Println("dcl:", b)
// 数组的元素是一个数组,声明二维数组
var twoArr [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
twoArr[i][j] = i + j
}
}
fmt.Println("2d: ", twoArr)
}
输出结果
emp: [0 0 0 0 0]
set: [0 0 0 0 100]
get: 100
len: 5
dcl: [1 2 3 4 5]
2d: [[0 1 2] [1 2 3]]
需要注意,数组作为参数传递时,是值传递,这一点与C语言有很多不同,所谓值传递即传递的是原始数组的一份复制品,操作复制品,不会改变原始数组,除非是传入数组的指针。
package main
import "fmt"
func modify(array [5]int) {
array[0] = 10 // 修改数组的第一个元素
fmt.Println("In modify(), array values:", array)
}
func main() {
// 定义并初始化一个数组
array := [5]int{1,2,3,4,5}
// 将数组作为函数参数传递
modify(array)
fmt.Println("In main(), array values:", array)
}
打印结果:
In modify(), array values: [10 2 3 4 5]
In main(), array values: [1 2 3 4 5]
切片
数组的长度在定义之后无法再次修改,且数组是值类型,每次传递都将产生一份副本,这些是数组的缺陷,而切片正好弥补了数组的这些不足之处。
实际上,Go所谓的切片,就是一个动态数组,类似与Java、Python中的List,可以自动增长。
从数组创建切片
package main
import "fmt"
func main() {
// 定义一个数组
var myArray [10]int = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 基于数组创建一个数组切片
var mySlice []int = myArray[:5]
fmt.Println("Elements of myArray: ")
for _, v := range myArray {
fmt.Print(v, " ")
}
fmt.Println("\nElements of mySlice: ")
for _, v := range mySlice {
fmt.Print(v, " ")
}
fmt.Println()
}
输出结果:
Elements of myArray:
1 2 3 4 5 6 7 8 9 10
Elements of mySlice:
1 2 3 4 5
切片与数组的区分
大家是不是像我一样,数组、切片,傻傻的分不清楚?其实我们仔细观察一下,数组和切片有一个明显的不同
var myArray [10]int
var mySlice []int
看到了吧,数组的中括号中有数字指明数组长度,而切片是没有指定数字的。这一点又和C语言不同,Go语言中,声明数组是不能省略数组中括号中的内容的,如果省略,则声明的是切片,不是数组。大家别被C语言的语法给弄迷糊了,该分清还是得分清。
Go语言可以使用myArray[first:last]这样的方式来基于数组生成一个数组切片,当[]中的first或者last为0时,可以省略。其中索引是从0开始的,且包含first索引对应的元素,不包含last索引对应的元素。更灵活的用法如下
// 基于myArray的所有元素创建数组切片
mySlice = myArray[:]
// 基于myArray的前5个元素创建数组切片
mySlice = myArray[:5]
// 基于从第5个元素开始的所有元素创建数组切片
mySlice = myArray[5:]
// 基于从第2个元素到第5个元素之间的所有元素创建数组切片
mySlice = myArray[1:5]
有过Python经验的小伙伴是不是非常熟悉,这就和Python的切片语法如出一辙。
直接创建切片
使用内置函数make()可以更灵活地创建数组切片。
// 创建一个初始元素个数为5的数组切片,元素初始值为0
mySlice1 := make([]int, 5)
// 创建一个初始元素个数为5的数组切片,元素初始值为0,
// 并预留10个元素的存储空间
mySlice2 := make([]int, 5, 10)
// 直接创建并初始化包含5个元素的数组切片
mySlice3 := []int{1, 2, 3, 4, 5}
数组切片就像一个指向数组的指针,实际上它拥有自己的数据结构,而不仅仅是指针。
数组切片的数据结构抽象为以下3个变量
- 一个指向原生数组的指针
- 数组切片中的元素个数
- 数组切片已分配的存储空间
实际上看过我的 C语言专栏 的朋友,应该非常熟悉了,这不就是 数据结构 那一篇的基于数组的线性表实现吗,看过的小伙伴应该已经自己实现过了,现在再来看Go语言切片,是不是So easy 呢?
切片的操作
操作数组元素的所有方法都适用于数组切片,比如数组切片也可以按下标读写元素,用len()数获取元素个数,并支持使用range关键字来快速遍历所有元素。
-
遍历
for i := 0; i <len(mySlice); i++ { fmt.Println("mySlice[", i, "] =", mySlice[i]) } //range表达式有两个返回值,第一个是索引,第二个是元素值 for i, v := range mySlice { fmt.Println("mySlice[", i, "] =", v) } -
动态增减元素
可动态增减元素是数组切片比数组更为强大的地方。与数组相比,数组切片多了一个存储能力(capacity)的概念,即元素个数和分配的空间可以是两个不同的值,这就好比篮子里苹果的个数和篮子的大小一样。合理地设置存储能力的值,可以大幅降低数组切片内部重新分配内存和搬送内存块的频率,从而大大提高程序性能。
分别使用len()函数和cap()函数获得切片中元素的个数和切片存储能力的大小
package main
import "fmt"
func main() {
mySlice := make([]int, 5, 10)
fmt.Println("len(mySlice):", len(mySlice))
fmt.Println("cap(mySlice):", cap(mySlice))
}
输出结果:
len(mySlice): 5
cap(mySlice): 10
使用append()函数给切片添加元素。需要注意append()的第二个参数是一个不定参,可以按需求添加若干个元素。当追加的内容长度超过当前已分配的存储空间(即cap()的值),数组切片会自动扩容。
// 添加一个元素
mySlice = append(mySlice, 4)
// 一次添加三个元素
mySlice = append(mySlice, 1, 2, 3)
mySlice2 := []int{8, 9, 10}
// 给mySlice切片的后面追加另一个数组切片中的所有元素,
// 因为添加的是一个切片,所以三个点不可省略
mySlice = append(mySlice, mySlice2...)
字典/映射
所谓映射,也就是键值对数据结构。它是Python中的字典,Java中的HashMap,其他语言中也称为关联数组。Go的映射底层是通过Hash表实现的,因此查询性能高效。
func main() {
// 声明一个映射变量
var mapVar1 map[string] int
// 使用make函数创建映射
mapVar1 = make(map[string] int)
//初始化映射中的键值
mapVar1["age"] = 18
mapVar1["id"] = 11
// 使用自动推导声明并创建映射
mapVar2 := make(map[string] int)
// 声明、创建并初始化映射
mapVar3 := map[string] int{
"age":20,
"num":1001
}
// 映射的增删改查操作
// 1. 增加元素
mapVar2["resId"] = 126
// 2. 删除元素,需要指定键
delete(mapVar1, "age")
// 3. 修改元素
mapVar3["num"] = 12
// 4. 查询元素 会返回两个参数,第二个是布尔类型,表示查询的键是否存在
value, ok := mapVar1["id"]
if ok {
// 查询的键存在,成功查询到对应的值
}
fmt.Printf("%d,%d",mapVar2,mapVar3)
}
在Go语言中强制规定,声明的变量必须使用,否则无法通过编译。因此我们在上述代码最后加入fmt.Printf("%d,%d",mapVar2,mapVar3),使用一下两个变量,否则无法编译。
分支与循环
if 分支
在 Go 中条件语句不需要圆括号,但是需要加上花括号。另外Go语言里没有三目运算符,只能使用完整的if条件语句,这一点比较坑爹!
package main
import "fmt"
func main() {
// 基本分支
if 7%2 == 0 {
fmt.Println("7 is even")
} else {
fmt.Println("7 is odd")
}
// 只有if条件
if 8%4 == 0 {
fmt.Println("8 is divisible by 4")
}
// if条件可以包含一个初始化表达式,
// 这个表达式中的变量是该条件判断结构中的局部变量
if num := 9; num < 0 {
fmt.Println(num, "is negative")
} else if num < 10 {
fmt.Println(num, "has 1 digit")
} else {
fmt.Println(num, "has multiple digits")
}
}
switch 分支
Go语言中的switch比C和Java都要强大得多,甚至可以完全替代if逻辑分支
package main
import "fmt"
import "time"
func main() {
// 基本使用,类似C与Java,但不需要break去结束,也可以省略default
i := 2
fmt.Print("write ", i, " as ")
switch i {
case 1:
fmt.Println("one")
case 2:
fmt.Println("two")
case 3:
fmt.Println("three")
}
// 使用逗号在case中分开多个条件。最后可以添加default语句,
// 当上面的case都没有满足的时候执行default逻辑块
switch time.Now().Weekday() {
case time.Saturday, time.Sunday:
fmt.Println("it's the weekend")
default:
fmt.Println("it's a weekday")
}
// 当switch后面没有跟表达式的时候,功能和if/else相同
// 且case后面的表达式不一定是常量,可以是逻辑表达式
t := time.Now()
switch {
case t.Hour() < 12:
fmt.Println("it's before noon")
default:
fmt.Println("it's after noon")
}
// 可以用来比较类型而非值,用来发现一个接口值的类型
switch t := i.(type) {
case bool:
fmt.Println("I'm a bool")
case int:
fmt.Println("I'm an int")
default:
fmt.Printf("Don't know type %T\n", t)
}
}
goto 跳转
Go语言继承了C中的goto语法,在C语言中,常常被告诫不要使用goto语法,甚至被一些教材视为洪水猛兽。实际上,如果goto语法被合理运用,可以大大简化语法表达,不过仍然建议要慎用goto语法,千万不可滥用
goto关键字需要与一个标签结合起来使用,表示跳转到指定的标签处
func main() {
var i int = -1
fmt.Println("------ 1 -----")
if i < 0{
goto end
}else{
goto lab1
}
fmt.Println("------ 2 -----")
lab1:
fmt.Println("------ 3 -----")
end:
fmt.Println("------ end -----")
}
如上例,条件满足时,直接跳转到end标签处,打印结果
------ 1 -----
------ end -----
goto语法主要用于多层循环嵌套时,直接跳出所有的循环,或者做返回值的异常处理,根据不同的返回值,直接跳转到对应的异常处理代码,跳过中间的大段代码。
循环
for是 Go 中唯一的循环结构。for循环有三个基本使用方式
package main
import "fmt"
func main() {
//单个循环条件,类似于C、Java中的while循环
i := 1
for i <= 3 {
fmt.Println(i)
i = i + 1
}
//经典for循环
for j := 7; j <= 9; j++ {
fmt.Println(j)
}
//死循环
for {
fmt.Println("loop")
break
}
for n := 0; n <= 5; n++ {
if n%2 == 0 {
// 循环控制,可以使用continue或break
continue
}
fmt.Println(n)
}
}
for循环配合range函数,可实现对map的遍历
maps := make(map(string)string)
for k,v := range maps{
fmt.Printf("key=%s,value=%s\n",k,v)
}
函数
定义函数
函数的定义格式为:
关键字func + 函数名 + 参数列表 + 返回值类型 + 函数体 + 返回语句
当函数没有返回值时,则省略返回值声明
package main
import "fmt"
// 返回值类型需写在参数列表与函数体花括号之间
func plus(a int, b int) int {
return a + b
}
// 相同类型参数,可以简化,只需声明一次类型
func plusPlus(a, b, c int) int {
return a + b + c
}
func main() {
res := plus(1, 2)
fmt.Println("1+2 =", res)
res = plusPlus(1, 2, 3)
fmt.Println("1+2+3 =", res)
}
与C语言相比,Go语言函数的特点是可以返回多个值,这一点与Python函数的多值返回是一样的。
package main
import "fmt"
func vals() (int, int) {
return 3, 7
}
func main() {
a, b := vals()
fmt.Println(a)
fmt.Println(b)
// 使用"_"操作符,可以丢弃多返回值中不需要的返回值
_, c := vals()
fmt.Println(c)
}
Go语言吸收了Python的语法特点,在多返回值中,可以使用_操作符丢弃不需要的。
函数的不定参
所谓不定参,是指函数传入的参数个数是不确定的。最典型的不定参函数是Printf,我们可以传入任意数量的参数。
// 定义一个接收不定参的函数
func fun1(args ...int) {
// 使用for循环获取不定参数
for _, arg := range args {
fmt.Println(arg)
}
}
func main() {
fun1(1,2,3,4,5)
fun1(18)
}
形如...int格式的类型是作为函数的不定参数类型存在的,它表明不定参数的类型都是int型,当函数中还有其他参数时,不定参必须放到参数列表的最后。
不定参的传递
如果我们外层的函数只是一个包装,不定参需要传递给内部的调用的函数,则可如下传递
func fun1(args ...int) {
for _, arg := range args {
fmt.Println(arg)
}
}
func fun2(args ...int){
// do something
// 传递不定参
fun1(args...)
}
匿名函数与闭包
所谓匿名函数,是指没有函数名的函数。在Go语言中,函数也是一种类型,函数也可以作为一种参数进行传递,从一个函数传入另一个函数,如同C语言中的函数指针或其他语言的函数式编程。与C语言不同的是,Go的匿名函数可以随时在另一个函数中定义
func main() {
// 定义一个匿名函数,并赋值给变量f1
f1 := func(a,b int)int{
return a + b
}
// 通过变量调用匿名函数
fmt.Println(f1(1,5))
}
与普通函数相比,匿名函数只是去除了名字,其他没有区别。除了匿名函数,实际上普通函数也可以赋值给一个变量用于传递
func fun1(args ...int) {
for _, arg := range args {
fmt.Println(arg)
}
}
func main() {
f1 := fun1;
f1(1,2,3)
}
闭包
通常人们直接将匿名函数理解为闭包,这样理解也不算错,但其实是不准确的,真正的闭包是指一个匿名函数引用了外部变量。匿名函数我们已经知道了,那什么叫对外部变量的引用呢?
// 定义一个计数器函数,它的返回值也是一个函数
func counter() (func()int) {
var i int = 0
// 匿名函数引用了一个外部变量i
return func()int{
i++
return i
}
}
func main() {
// 创建一个计数器
count := counter()
// 调用计数器,每次调用都会加1
fmt.Println(count())
fmt.Println(count())
fmt.Println(count())
}
打印结果:
1
2
3
以上counter函数中的匿名函数才是一个真正的闭包,因为它引用了相对于自己的外部变量i。闭包概念的关键就是对外部变量的引用,只要这个闭包还在使用,那么闭包所引用的外部变量就不会被释放。因此闭包的使用应当小心,滥用闭包易造成内存泄露。
函数做为参数传递
以上闭包的例子实际上已经演示了函数作为返回值传递,函数作为参数也大致相同,需要注意的是函数类型该如何声明。
// 定义一个函数,它的第一个形参也是一个函数
func f3(add func(int,int)int,a,b int)int{
return add(a,b)
}
func main() {
// 定义一个匿名函数,只要函数签名匹配,就能传递给形参
f := func(x,y int)int{
return x + y
}
result := f3(f,10,8)
fmt.Println(result)
}
一个函数的函数签名就是它的类型,以上代码看起来不是很清晰,而且函数签名写起来又很长不简洁,还容易错,这时候我们就需要借用type关键字,将函数签名定义为一种新的类型,这等同于C语言中的typedef
// 将函数签名定义成一种新类型 Add
type Add func(int,int)int
// 声明形参时,直接使用这种新的类型,而不用写很长的函数签名
func f3(add Add,a,b int)int{
return add(a,b)
}
Go语言函数使用小结
- Go的函数没有重载功能。这很难说是利是弊,但这意味着相同命名空间内的函数不能同名,哪怕函数签名不同。
- Go函数的参数传递都是值传递。这一点与C、Java都有所不同。Java中的对象做函数参数是引用传递,而C语言中的数组做函数参数也是引用传递,所谓引用传递,可以理解为是传递的内存地址。值传递则直接是传递的内容。例如Go传递数组,直接是对数组拷贝一份,如果数组很大,这样做性能低下,因此,Go中需要我们手动传递指针。
包
为了适应现代的大型程序开发,现代高级编程语言都有包的概念,Go中的包与Python、Java中的包概念相似。简单说,包就是一个分组,或者说是一个文件夹,但它也是一个命名空间。之前在C语言专栏的文章中提过,C语言有一个重大缺陷,就是没有命名空间的概念,函数同名,会造成命名冲突。Go语言的包机制则不存在该问题。
自定义包
在当前目录下创建一个test目录,在该目录中创建t1.go源文件
// 使用package声明一个包名叫test
package test
// 函数名首字母必须大写,否则包外无法访问
func Add(a ,b int)int{
return a+b
}
func Sub(a ,b int)int{
return a-b
}
在hello.go中调用
package main
import "fmt"
import "hello/test"
func main() {
// 需使用包名调用包中函数
test.Add(1,2)
fmt.Printf("hello,world!\n")
}
文件结构
hello
│─go.mod
│─hello.go
│
└─test
t1.go
package用于命名包,import用于导入包。导入包时,注意路径,这里以当前工程的相对路径开始。当前工程文件夹是hello,"hello/test"则表示当前工程下的test文件夹。在命名包名时,应与包的文件夹名一致。
包的几种导入方式
// 一个一个导入
import "fmt"
import "hello/test"
// 在一个括号内导入,推荐
import (
"fmt"
"hello/test"
)
import (
"fmt"
// 导入包的同时给包起别名
tt "hello/test"
)
func main() {
// 使用别名调用,当包名过长时很有用
tt.Add(1,2)
}
有时候使用包名或包的别名去调用函数,都显得有点麻烦,实际上Go还提供了另一种导入方式,无需使用别名调用
import (
"fmt"
// 导入包时在前面加一个. 符号
. "hello/test"
)
func main() {
// 无需包名直接调用函数
Add(1,2)
fmt.Printf("hello,world!\n")
}
以上这种使用.导包的方式不推荐,极易造成导包冲突,当我导入很多包时,很可能会存在多个包中有同名函数的情况。起别名是比较推荐的导包方式,特别是导入同名包时,可以通过起别名来区别。
最后还有一种匿名导包方式
import (
"fmt"
// 导入包名的前面加下划线 _
_ "hello/test"
)
匿名导包表示只导入,不使用。有人肯定会奇怪了,不使用干嘛要导入呢?Go语言强制规定,导入的包必须使用,否则无法通过编译。有时候我们只需要加载一个包,但是不调用包中的函数,这时候不匿名导包的话,就不能编译了。
包的初始化函数
在Go语言中,每个包都有一个初始化函数init,该函数不需要我们手动调用,它只在包加载的时候调用。上面说的匿名导包也就是为了调用该函数做一些初始化工作。
修改上面的t1.go,实现一下init函数
package test
import "fmt"
func init(){
fmt.Println("test init run")
}
只在hello.go中匿名导包
package main
import (
// 导入包的同时给包起别名
_ "hello/test"
)
func main() {
}
打印结果:
test init run
Go语言的入口
Go语言也是以一个main函数作为入口函数,但是Go语言强制规定,main函数必须在main包中,因此我们的入口源文件必须声明为main包。
那么这里就有一个问题,在main包的初始化函数init和main函数谁先执行呢?
package main
import "fmt"
func init(){
fmt.Println("main init run")
}
func main() {
fmt.Println("main main run")
}
其实我们可以推测一下,init函数作为初始化函数,理论上应该比别的函数都早,哪怕是main函数。
看一下打印结果,事实证明了我们的猜想。
main init run
main main run
欢迎关注我的公众号:编程之路从0到1
