mybatis的源码解析(一)
Mybatis的源码解析(一)
- 写在前面的话
- 学习方法
- 正文
- JDBC的执行过程
- JDBC三种执行器
- 1.statement简单执行器
- 2.preparedStatement预处理执行器
- 3.存储过程处理器CallableStatement
- mybatis执行过程
- Executor执行器体系
- SimpleExecutor 简单执行器
- ReuseExecutor 重用执行器
- BatchExecutor 批处理执行器
- CachingExecutor
- Mybaits生成CachingExecutor执行流程
- Executor执行过程
- 本篇结尾
写在前面的话
随着越来越多的Java工程师涌入开发的行列,以往的只是简单会用已经越来越容易被这个行业所淘汰,尤其是只能靠着开发赚取这一微薄的薪水。在公司往复开发平凡的业务SQL接口等,这些都将非常容易被淘汰,而摆脱此困境只能更加需要深入的学习,形成自己的体系和认知,以便跳出这个风口,不做平凡职业者,向顶端看齐,让我们一起学习一起努力进步,只有这样,薪水才会随着年限的增加而增加。
学习方法
学习这件事情很奇妙,有时候静下心来好好学居然也会上瘾。但偶尔间断了几天不学,似乎又不想要继续学了,除了最开始的兴奋,只剩下乏力和枯燥。然后感觉经常记忆只是放了一个锚:知道问题可以在哪儿解决,而不是自己去整理解决方法,遇到问题都是搜索完以后又忘却,下次遇到又继续去搜索。这样往往复复什么都没学到,后来我总结了一些方法,我也正尝试着使用这些方法(个人方法,不喜可跳过),希望自己以后遇到问题时也会回来回顾和修改之前的一些想法:
- 做笔记并学会总结 ,当学习到一个新知识时,我当场可能会截图,或者留下一个笔记,但并没有做好总结,以至于我面试时感觉自己好像什么都会,又感觉什么都不会,没有有亮点的技术也没留下像样的文稿和资料。当你学会并开始做笔记时就好像把学到的知识在脑海里过了一遍,可以深刻并在这里留下了一个锚,以便于以后更方便寻找或者向下挖掘。
- 讲给别人听,当你学完了一个新知识,你可以试着讲给别人听,如果别人也能在你复述的情况下能听懂,那么你对新知识的理解和全局观又进了一步,并且能深刻记住这些知识。
- 从点到线到面 学习,有些学习例如源码,我原以为我会从一个大的框架开始解读源码,我发现我错得很离谱,那些大而广的知识只适合和外行吹牛,而对你真正使用的时候帮助不是很大,而且解读源码将会非常头痛,让人更容易放弃深入学习。
正文
源码解读是对自己学习的一个检验,希望自己能学到的同时也能帮助更多的人理解相应的知识,然后反哺自己学习的短板。那我们开始学习吧!
JDBC的执行过程
我们知道,mybatis执行最终还是还是在使用jdbc的执行,同时当做复习,我们应该也知道jdbc的执行过程:

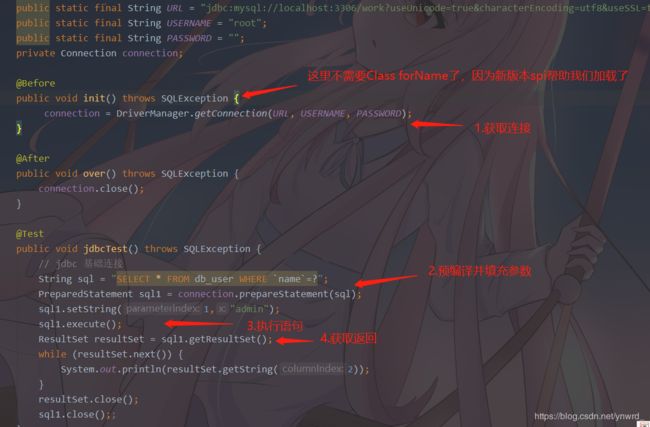
我们使用jdbc时一共执行的五步:
1.获取connection
2.预编译.prepareStatment
3.execute执行结果
4.获取返回值
5.close连接
JDBC三种执行器

1.statement简单执行器
基本功能:执行静态的SQL
传输相关:批处理,设置加载的行数
@Test
public void statementBatchTest() throws SQLException {
String sql = "INSERT INTO `db_user` (`name`,`nickname`,`status`,`password`) VALUES ('toto','ynwrd',1,'md5');";
Statement statement = connection.createStatement();
// statement.setFetchSize(20);//一次可以读取多少行结果
long nowTime = System.currentTimeMillis();
for (int i = 0; i < 20; i++) {
// statement.execute(); //单条执行
statement.addBatch(sql); //添加进批量量,相当于填充进弹药
// statement.addBatch(); // 添加批处理参数
}
statement.executeBatch(); // 一次全部提交
System.out.println(System.currentTimeMillis() - nowTime); //批处理效率明显高于单条执行
statement.close();
}
2.preparedStatement预处理执行器
prepardStatement除了简单执行器的功能,还包括对参数进行预编译,可以有效的防止SQL注入
能注入的例子:
// sql注入测试
public int selectListByName(String name) throws SQLException {
//传入参数为 admin' or '1'='1 时就会有SQL注入的问题,能直接拉全库,
// 甚至改动参数能删除数据库或者拉下其它表的数据,造成不可预估的危险
String sql = "SELECT * FROM db_user WHERE `name`='" + name + "'";
System.out.println(sql);
Statement statement = connection.createStatement();
statement.executeQuery(sql);
ResultSet resultSet = statement.getResultSet();
int count=0;
while (resultSet.next()){
count++;
}
statement.close();
return count;
}
使用prepardStatement 处理器后有效防止注入的例子:
public int selectListByName2(String name) throws SQLException {
// 参数再怎么变也没用,有效防止sql注入
String sql = "SELECT * FROM db_user WHERE `name`=?";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setString(1,name);
System.out.println(statement);
statement.executeQuery();
ResultSet resultSet = statement.getResultSet();
int count=0;
while (resultSet.next()){
count++;
}
statement.close();
return count;
}
prepardStatement 批量提交的例子:
@Test
public void prepareBatchTest() throws SQLException {
String sql = "INSERT INTO `db_user` (`name`,`nickname`,`status`,`password`) VALUES ('toto','ynwrd',1,?);";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setFetchSize(20);//一次可以读取多少行结果
long nowTime = System.currentTimeMillis();
for (int i = 0; i < 20; i++) {
preparedStatement.setString(1, i+"号player");
// preparedStatement.execute(); //单条执行
preparedStatement.addBatch(); //添加批处理参数
// preparedStatement.addBatch(sql); // 添加进批量,如果要用这个则必须是静态SQL
}
preparedStatement.executeBatch(); // 一次全部提交
System.out.println(System.currentTimeMillis() - nowTime); //批处理效率明显高于单条执行
preparedStatement.close();
}
简单执行器和预编译执行器对比图例:

批量提交时图例:
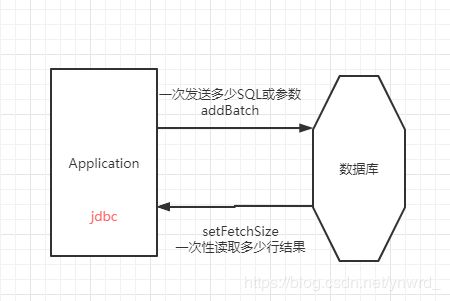
3.存储过程处理器CallableStatement
能设置出参,读取出参
mybatis执行过程
从现在开始说mybatis了,我认为步子要一步一步走,饭要一口一口的吃,由于mapper映射和出参设置那些都比较难,我们先看大框架,再从小螺丝一个一个拧。
sqlsession:sql会话,我们所有的mybatis都要通过它来调用,它拥有的功能包括基本的增删改查,还有辅助功能包括提交和关闭会话。
Executor:执行器,除了提供基本的改、查、缓存维护,还有辅助功能包括提交、关闭执行器、批处理刷新。
StatementHandler:声明处理器,执行器调用声明处理器并且做参数处理和结果处理。
后面在总结和描述中会用更加细粒度来解释这些词语,如果没有基础,你现在强行记会比较费力,我只是在带入后面需要说的部分
我们看一下sqlsession给我们的查询方法:

我们看到sqlsession中有很多名字的方法重用,这是一种门面模式
select(String,Object,RowBounds,ResultHandler)
String:statementId,即mapper中的方法的全路径+方法名:例如:com.toto.UserMapper#selectByid
Object: 传入的参数
RowBounds:分页类,可以用来做分页的类,默认值分页的大小是 Integer.MAX_VALUE
ResultHandler:结果集处理对象
注意:我们的会话一次可能会对应多条SQL,所以我们的会话不是线程安全的,一个会话只能由一个线程来控制,同时,我们的会话对应了一个执行器,所以我们的会话下的执行器和声明处理器都不能跨线程使用。一个会话对应一个执行器,一条sql对应一个声明处理器,对应比例是1:1:n(sql数量)。这些知识可能难以消化,但经过后面的学习会逐步理解整个流程。

根据这个体系,我们一个体系一个体系来讲,由于篇幅较长,本文只介绍执行器的体系
Executor执行器体系
//源代码路径:org.apache.ibatis.session.defaults.selectList
//门面模式最典型就是不管扩充了多少,最终都会用最多参数的那个类,本文以selectList来追溯源码
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
我们看到会话执行的查询最终使用的是executor执行器,同时它的构造方法也有传入执行器的类型,那我们应该选择哪种执行器呢?执行器中又有哪些故事呢?它们不同的特别又是什么呢?让我们带着问题进入执行器的探究。
@Test
public void sessionTest(){
//ExecutorType是一个枚举类,它有SIMPLE、REUSE、BATCH
SqlSession sqlSession = factory.openSession(ExecutorType.SIMPLE,true);
// 降低调用复杂性
List<Object> list = sqlSession.selectList("com.toto.UserMapper.selectByid", 1);
System.out.println(list.get(0));
}
然后我们Debug来跑程序,随后又发现了不同的执行器

当我们断点继续往下走,我们进了CachingExecutor,它好像没有真的执行器实现,仿佛只是依靠传入的executor来做事情:

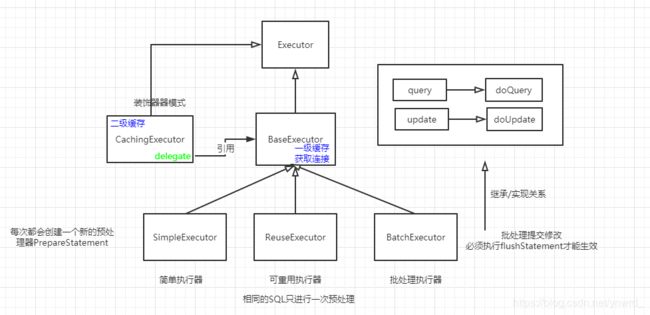
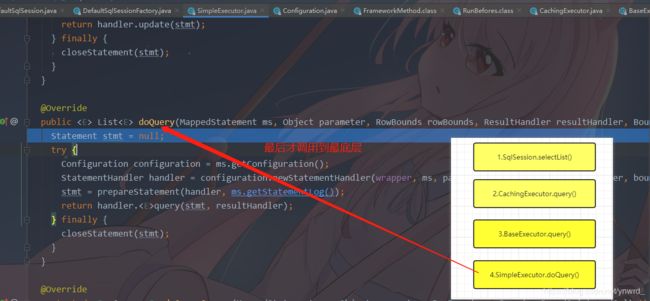
想起来了!这是一个装饰者模式:最轻简的实现方式,通过获取实例,来切面完成基础功能和追加的功能。后面我们再细讲这个装饰者模式,随后Debug继续深入,我们看到它又调用了一个query方法,也就是追加了一部分功能,这些功能后面我写二级缓存时会讲解到,然后使用delegate来继续调用query方法,然后我们深入到了BaseExecutor,原来SimpleExecutor继承了BaseExecutor,随后BaseExecutor转向后又调用了doQuery方法,最后才到我们的SinpleExecutor。总结一下,我们发现了一共5个执行器,我先画出来关系图,随后逐个讲解这些执行器能做哪些事情吧。。
//源码位置在org.apache.ibatis.executor的322行
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// doQuery方法是抽象方法,由SimpleExecutor、ReuseExecutor、BatchExecutor 来实现
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
SimpleExecutor 简单执行器
不缓存,有多少条SQL执行多少条
// 简单执行器测试
@Test
public void simpleTest() throws SQLException {
SimpleExecutor executor = new SimpleExecutor(configuration, jdbcTransaction);
ms = configuration.getMappedStatement("com.toto.UserMapper.selectByid");
List<Object> list = executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(10));
executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(10));
System.out.println(list.get(0));
}
Preparing: select * from db_user where id=?
Parameters: 1(Integer)
Columns: id, name, password, status, nickname, createTime
Row: 1, admin, admin, 1, ynwrd, 2016-08-07 14:07:10
Total: 1
Preparing: select * from db_user where id=?
Parameters: 1(Integer)
Columns: id, name, password, status, nickname, createTime
Row: 1, admin, admin, 1, ynwrd, 2016-08-07 14:07:10
Total: 1
根据日志显示运行了两次doQuery打印了两遍日志
ReuseExecutor 重用执行器
同样的SQL(不管是不是同一个statementId,只要SQL一样,那么就会重用),并且缓存周期是这个会话
// 重用执行器
@Test
public void ReuseTest() throws SQLException {
ReuseExecutor executor = new ReuseExecutor(configuration, jdbcTransaction);
List<Object> list = executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(10));
// 相同的SQL 会缓存对应的 PrepareStatement 它的缓存周期:这个会话
executor.doQuery(ms, 10, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(10));
System.out.println(list.get(0));
}
Preparing: select * from db_user where id=?
Parameters: 1(Integer)
Columns: id, name, password, status, nickname, createTime
Row: 1, admin, admin, 1, ynwrd, 2016-08-07 14:07:10
Total: 1
Parameters: 10(Integer)
Total: 0
根据日志显示运行了两次doQuery只打印了一遍SQL的日志,但两次参数都打印了。
BatchExecutor 批处理执行器
批处理执行器一般用在修改SQL的场景时使用,将对SQL进行一次性打包插入,使用这个性能比SimpleExecutor性能要高一些的,但一定要执行doFlushStatements才能生效
// 批处理执行器
@Test
public void BatchTest() throws SQLException {
BatchExecutor executor = new BatchExecutor(configuration, jdbcTransaction);
MappedStatement setName = configuration
.getMappedStatement("com.toto.UserMapper.setNickName");
Map param = new HashMap();
param.put("arg0", 1);
param.put("arg1", "管理员大哥");
executor.doUpdate(setName, param); //修改的第一条sql
executor.doUpdate(setName, param);// 修改的第二条sql
executor.doFlushStatements(false);
}
==> Preparing: update db_user set nickname=? where id=?
==> Parameters: 管理员大哥(String), 1(Integer)
==> Parameters: 管理员大哥(String), 1(Integer)
能将数据批量新增或者修改,如果遇到需要批量新增或者修改时,可以使用这种执行器,效率将得到极大提升
CachingExecutor
注意:1.二级缓存只有提交后才能使用 2.Bean开启缓存需要实例化 3.需要开启二级缓存,如:@CacheNamespace
录了一个gif,使用commit后能获取到缓存的图片
代码流程:commit以后就提交到二级缓存上,就可以允许被其它会话使用。二级缓存我们后面再开篇幅详细讲解,因为缓存也存在很多级,东西比较多
代码示例:
@Test
public void cacheExecutorTest() throws SQLException {
// BaseExecutor
Executor executor = new SimpleExecutor(configuration,jdbcTransaction);
// 装饰器模式
Executor cachingExecutor=new CachingExecutor(executor);// 二级缓存相关逻辑 执行数据操作逻辑
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
cachingExecutor.commit(true);
// 提交之后才会更新
cachingExecutor.query(ms, 1, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
}
输出SQL时:
Preparing: select * from db_user where id=?
Parameters: 1(Integer)
Columns: id, name, password, status, nickname, createTime
Row: 1, admin, admin, 1, 管理员大哥, 2016-08-07 14:07:10
Total: 1
Committing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@130520d]
Cache Hit Ratio [com.toto.UserMapper]: 0.5
缓存命中率0.5,因为我们只跑了两次,还有一次存储缓存,一次命中缓存
Mybaits生成CachingExecutor执行流程
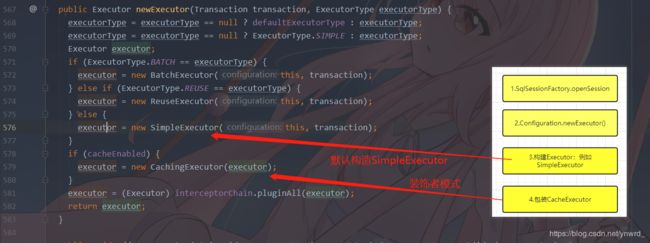
关于spring与mybatis的故事我们后面再聊,在这里我们先简单说一下我们生成的流程:
1.SqlSessionFactory.openSession
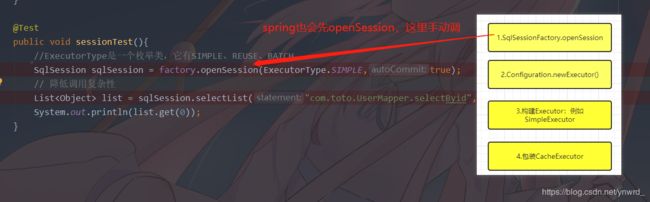
2.Configuration.newExecutor()
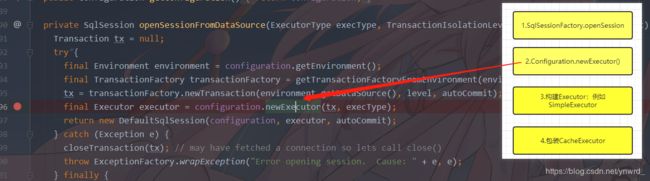
3.构建Executor:例如SimpleExecutor
4.包装CacheExecutor
Executor执行过程
我这里简单展示一下查询的执行过程,也将分为四步,debug跑
1.查询开始
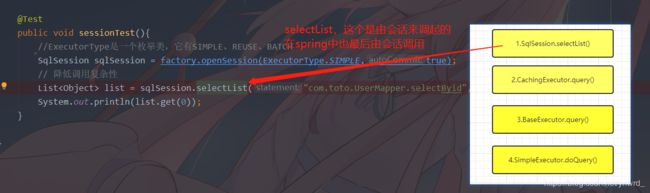
2.sqlSession有执行器的所有功能,因为它手上拿着执行器:

当没能触发二级缓存时(二级缓存应用程序不倒,缓存就不会被GC,除非调用清空方法,后续有讲解),就会往下继续调用:

3.BaseExecutor执行query方法,处理1级缓存和相关逻辑
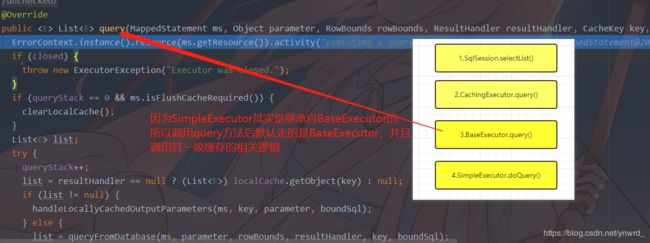
4.BaseExecutor执行到实际查询时:

本篇结尾
由于篇幅较长,第一篇解析就到这里,请期待更多后续,也希望大家多实践多总结,这样东西才能学到并掌握