darknet-convolution层
forward
void forward_convolutional_layer(convolutional_layer l, network_state state)
{
int out_h = convolutional_out_height(l);
int out_w = convolutional_out_width(l);
int i;
fill_cpu(l.outputs*l.batch, 0, l.output, 1); //填0
if(l.xnor){
binarize_weights(l.weights, l.n, l.c*l.size*l.size, l.binary_weights);
swap_binary(&l);
binarize_cpu(state.input, l.c*l.h*l.w*l.batch, l.binary_input);
state.input = l.binary_input;
}
int m = l.n;
int k = l.size*l.size*l.c;
int n = out_h*out_w;
float *a = l.weights;
float *b = state.workspace;
float *c = l.output;
for(i = 0; i < l.batch; ++i){
im2col_cpu(state.input, l.c, l.h, l.w,
l.size, l.stride, l.pad, b); //用当前层(c,h,w)和前一层输出做卷积,结果是2维向量(此处被展开成1维向量)
gemm(0,0,m,n,k,1,a,k,b,n,1,c,n); //计算当前层输出初始值(没有加偏置和激励)
c += n*m; //当前层输出一个样本对应的特征尺寸 n*m
state.input += l.c*l.h*l.w;
}
if(l.batch_normalize){
forward_batchnorm_layer(l, state);
}
add_bias(l.output, l.biases, l.batch, l.n, out_h*out_w);
activate_array(l.output, m*n*l.batch, l.activation);
if(l.binary || l.xnor) swap_binary(&l);
}
backward
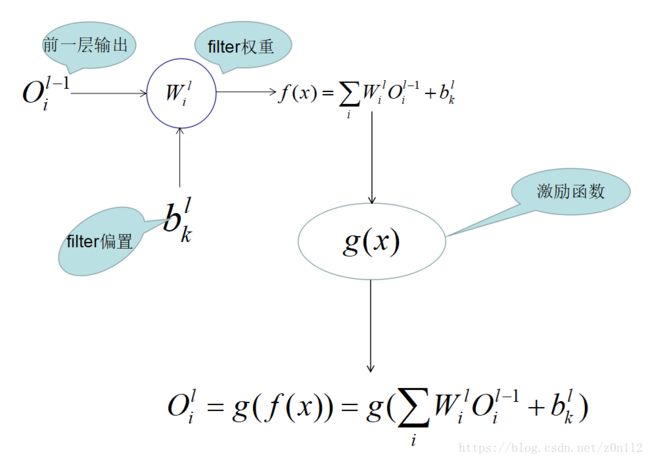
最终 l l 层的输出 Oli O i l 对偏置 blk b k l 求导就是激励函数的导数 ∂g(x) ∂ g ( x ) ;对
权重 Wli W i l 求导结果是 ∂g(x)×Ol−1i ∂ g ( x ) × O i l − 1
void backward_convolutional_layer(convolutional_layer l, network_state state)
{
int i;
int m = l.n; //当前层filter个数,从cfg中读取
int n = l.size*l.size*l.c; //当前层使用的卷积核尺寸,注意c是前一层输出通道数
int k = convolutional_out_height(l)*
convolutional_out_width(l); //当前层,一个通道下特征图尺寸
//l.delta中保存激励函数的导数
gradient_array(l.output, m*k*l.batch, l.activation, l.delta);
//l.bias_updates中保存每个通道的偏置的导数
backward_bias(l.bias_updates, l.delta, l.batch, l.n, k);
if(l.batch_normalize){
backward_batchnorm_layer(l, state);
}
for(i = 0; i < l.batch; ++i){
float *a = l.delta + i*m*k;
float *b = state.workspace; //临时内存
float *c = l.weight_updates; //权重更新(什么时候做了初始化?)
float *im = state.input+i*l.c*l.h*l.w; //前一层的输出
im2col_cpu(im, l.c, l.h, l.w,
l.size, l.stride, l.pad, b);
gemm(0,1,m,n,k,1,a,k,b,k,1,c,n); //计算权重的导数
if(state.delta){ //前一层有输出误差,把当前层的梯度向前传播
a = l.weights;
b = l.delta + i*m*k;
c = state.workspace;
gemm(1,0,n,k,m,1,a,n,b,k,0,c,k);
col2im_cpu(state.workspace, l.c, l.h, l.w, l.size, l.stride, l.pad, state.delta+i*l.c*l.h*l.w);
}
}
}gradient_array(l.output, m*k*l.batch, l.activation, l.delta); 完成 df(x)dx d f ( x ) d x 的计算,结果保存在l.delta中, 尺度等于当前层输入(n,h,w)
backward_bias(l.bias_updates, l.delta, l.batch, l.n, k);计算每个输出通道的偏置,结果保存在l.bias_updates中,尺寸等于输出通道数n