内存计算-SPARK
by 清华大学
为什么并行计算?
- 计算量大
- 单进程算得不够快,多CPU算
- 内存需求大
- 单机内存不够大
- 内存随机访问比硬盘随机访问快100,000倍
- I/O 量大
- 单个硬盘读写太慢,多个硬盘读写
并行计算的挑战
- 编程困难
- 并行性识别与表达,难写
- 同步语句,难写对
- 性能调优难,难写快 (并行计算目标就是提升性能,性能调优难)
-负载平衡
- 局部性 (高速缓存cache,使用cache可以快10倍左右)
- 容错难
并行计算中的局部性
矩阵相乘,按列访问会造成cache失效
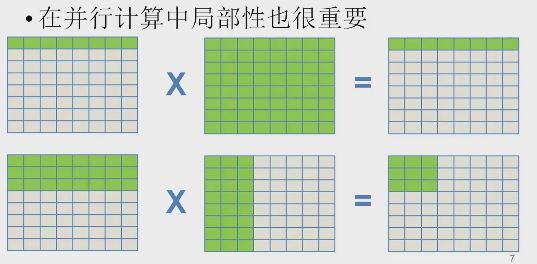
分块算法,得到更高的局部性
高可用性
大数据处理系统通常是由大量不可靠服务器组成的,如果处理1个10天的大数据处理任务时在第8天机器坏掉怎么办?
重新计算不一定能解决问题
传统的容错方法不适用
- 锁步法(性能会有较大影响),多版本编程(多个人来编程,对比结果,软件容错)
检查点设置与恢复(保存程序状态,从保存状态位置继续执行,IO量大)
大数据处理并行系统
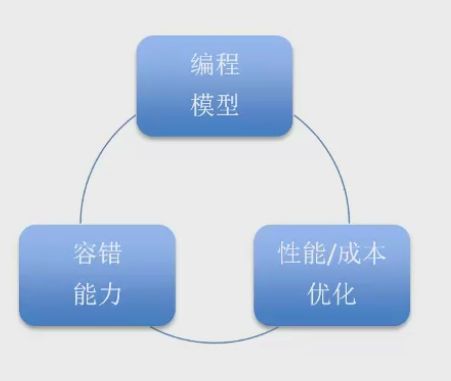
内存计算需求
Map Reduce成功之处
- 用户只需要编写串行程序
- 自动并行化和分布式执行
- 自动容错
- 自动负载平衡
用户对系统提出了更高的要求
- 更复杂的多阶段任务
- 交互式查询
Map Reduce 的局限性
- 表达能力有限
- 只有Map 和Reduce两种操作
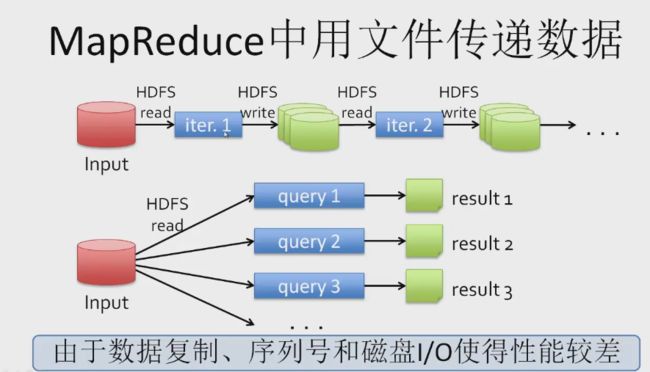
- 复杂任务通常需要迭代的 MapReduce
- 需要将中间结构保存在硬盘上
- 大量I/O操作造成性能急剧下降
- 引入的I/O操作多,只能做离线分析,很难支持数据的交互式查询
MapReduce 文件传递数据
如果能用内存保存数据?
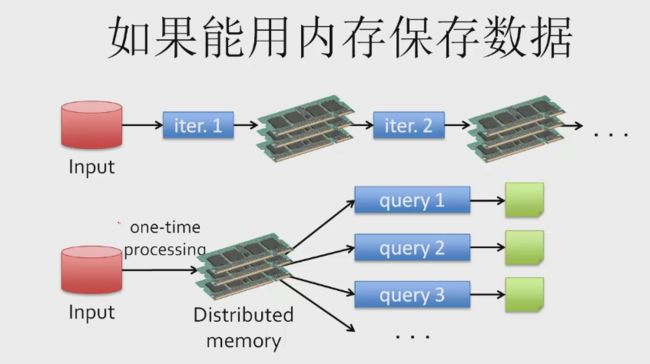
比采用硬盘方案快10-100倍
In Memory Computing
内存计算的可行性
问题:
- 内存是否足够大能够装下所需要的数据?
- 内存有多贵?与硬盘相比性价比如何?
- 数据保存在硬盘上,可以保证数据的可用性,放在内存里如何容错?
- 如何高效表示内存里的数据?
input -> iter1 -> memory -> iter2 -> memory
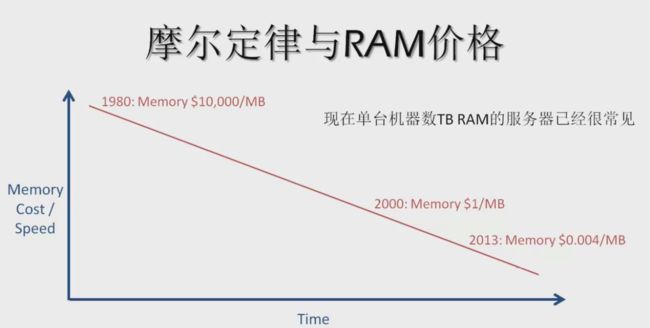
单位芯片上集成的晶体管数量随着时间(每两年)可以成倍增长
各个内存层次的延迟
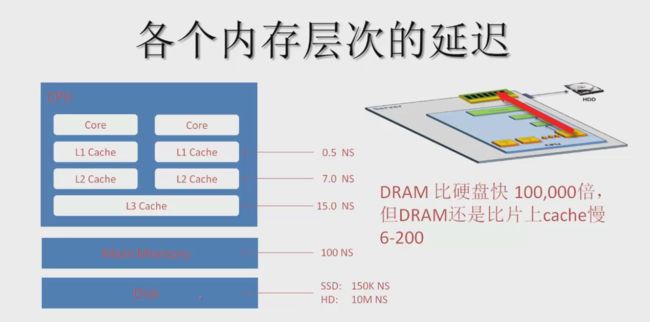
DRAM比硬盘快100,000倍,但是DRAM比片上cache慢6-200倍
内存计算的实例:SPARK
SPARK设计理念:着重效率和容错
如何抽象多台机器的内存?
- 分布式共享内存(DSM)
- 统一地址空间
- 很难容错
- 分布式键-值存储(Piccolo,RAMCloud)
- 允许细粒度访问
- 可以修改数据(mutable)
- 容错开销大
DSM和键值对的容错机制
- 副本或Log
- 对数据密集应用来说开销很大
- 比内存写要慢10-100倍
解决方案
- RDD(Resilient Distributed Datasets)
- 基于数据集合,而不是单个数据
- 由确定性的粗粒度操作产生(map,filter,join等)
- 数据一旦产生,就不能修改(immutable)
- 如果要修改数据,要通过数据集的变换来产生新的数据集
高效容错方法
- 数据一旦是确定性的产生,并且产生后不会变化
- 就可以通过“重复计算”的方法恢复数据
- 只要记住rdd生成过程就可以了,这样一次log可以用于很多数据,在不出错的时候几乎没有开销

大数据处理并行系统
用编程模型上的限制获取好的容错能力和高性能
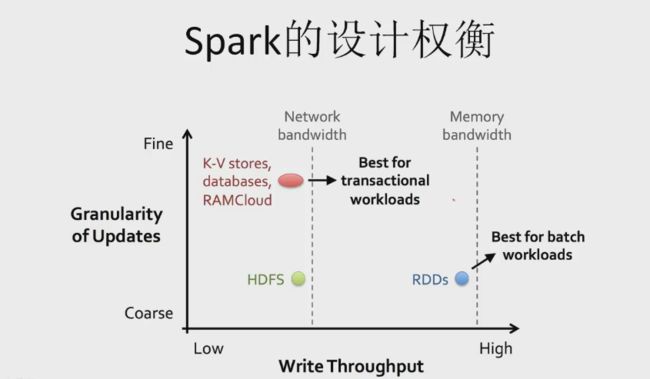
K-V 对,细粒度修改; HDFS 只能添加数据
RDD 高吞吐率,不允许做细粒度修改,换取好的容错能力和好的性能
SPARK 编程接口
- 基于Scala 语言
- 类似Java的一种函数语言
- 可以在Scala控制台上交互式地使用Spark
- 现在也支持Java 和Python
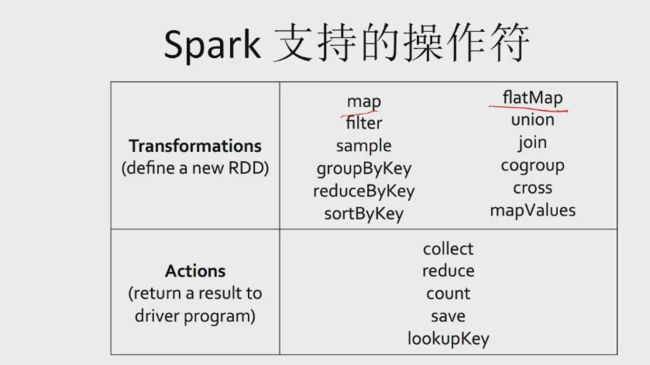
- 基于RDD的操作
- Transformation: 从现有RDD产生新的RDD
- map, reduce, filter, groupBy, sort, distinct, sample …
- Action: 从RDD返回一个值
- count, collect, first ,foreach …
SPARK 编程实例–LOG挖掘
将数据从文件系统中调入内存,然后进行交互式的查询

lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
messages = errors.map(_.split('\t')(2))
cachedMsgs = messages.cache()
cachedMsgs.filter(_.contains("foo")).count // 包含foo的信息的数目
cachedMsgs.filter(_.contains("bar")).count

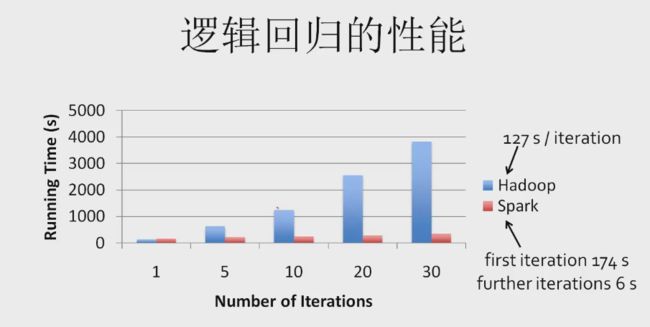

SPARK 实现技术
延迟估值(Lazy Evaluation)
val lines = sc.textFile("data.txt") //transformation
val lineLengths = lines.map(s => s.length) //transformation
val totalLength = lineLengths.reduce((a,b) => a+b) //action, trigger computation- 前面两行都不会触发计算(Transformation)
- 最后一行的reduce会引发计算,生成DAG

有向无环图
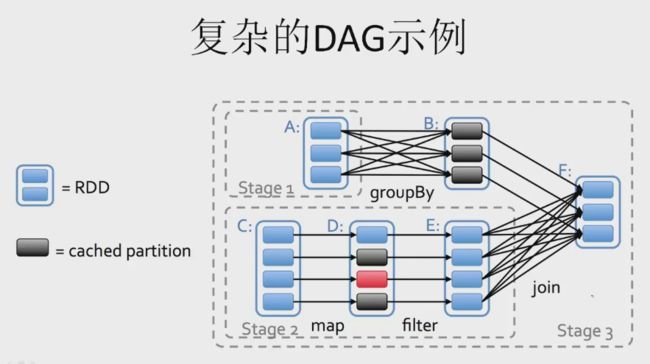


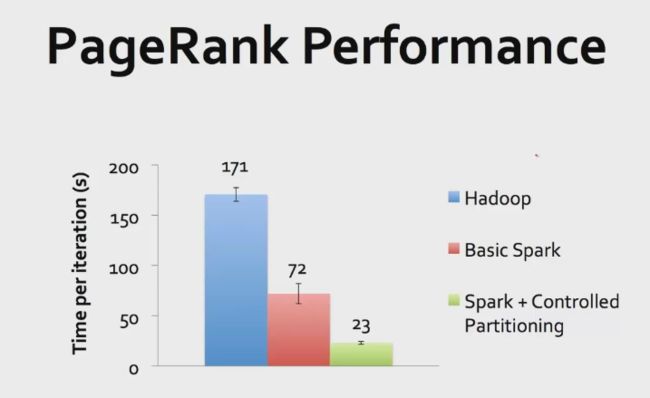
RDD性能的提高
对需要重用的RDD使用Persist和Cache提高性能


SPARK 应用和生态环境
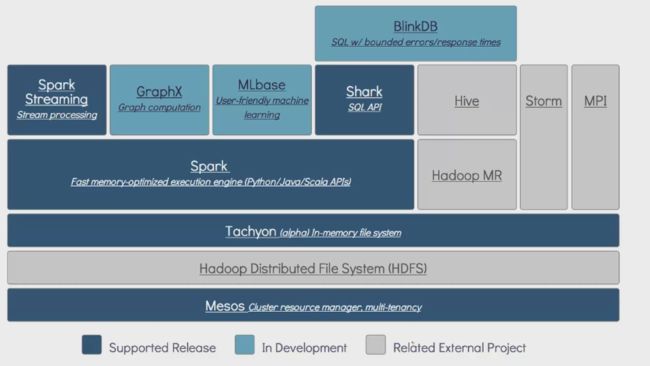




SPARK 局限性
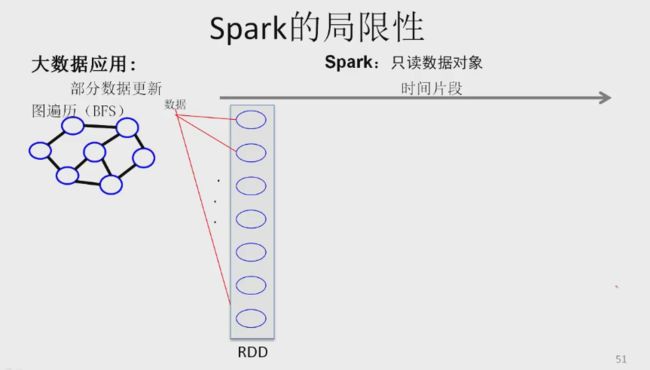
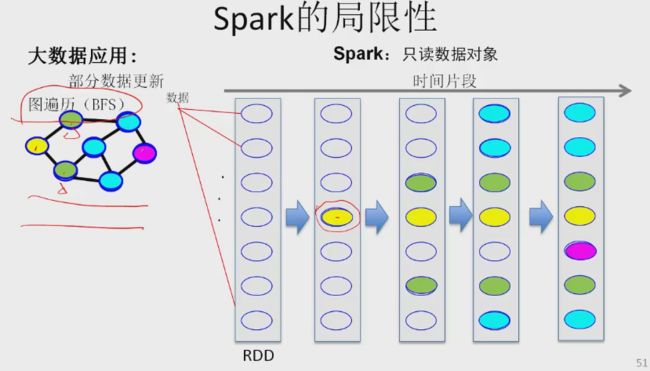
只能复制一份,标记少数节点。操作为网络操作、内存拷贝操作、IO操作(由于数据是只读的)-> 效率低,大量内存拷贝。
每次细粒度的数据更新,由于spark基于粗粒度RDD只读的数据对象模型,需要RDD变换,即有大量数据的复制,导致处理效率不高