sqoop
一 Sqoop介绍及架构
Sqoop是一个用于hadoop数据和结构化数据之间转换的工具。全称SQL-TO-HADOOP.它可以把hadoop数据,包括hive和hbase存储的数据转化为结构化数据也就是数据库的数据,也可以把关系型数据库数据转化为hadoop数据

这些转换操作全是通过Hadoop的MapTask来完成的,并不会涉及到Reduce操作。这是因为我们只是进行数据的拷贝,并不会对数据进行处理或者计算,没有什么特殊的处理,所以在map阶段就可以输出数据。
二 sqoop的安装
2.1 mv/opt/app/sqoop/conf/sqoop-env-template.sh sqoop-env.sh
#Setpath to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/app/hadoop
#Setpath to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/app/hadoop
#setthe path to where bin/hbase is available
#export HBASE_HOME=
#Setthe path to where bin/hive is available
export HIVE_HOME=/opt/app/hive
2.2 添加mysql驱动包到lib目录
三 sqoop命令详解
3.1codegen 将关系型数据库表映射成java class以及javajar包
sqoopcodegen \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--tableemp \
--bindir/opt/code
3.2 create-hive-table创建hive表
sqoopcreate-hive-table \
--connect
--username
--password
--table
--create-hive-table\ #如果表已经存在,则JOB失败
--hive-database
--hive-overwrite\ #如果存在表数据,则覆盖
--hive-table
3.3 eval:执行一个sql语句,并在控制台打印出来
sqoopeval \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
-e"SELECT * FROM emp"
3.4 export
3.4.1 从HDFS导出数据到关系型数据库
语法:
sqoop export \
--columnscol1,col2,...... 导出到表哪几列
--direct:使用direct导出,速度更快
--export-dir
-m
--table
解析输入参数:
--input-enclosed-by
--input-escaped-by
--input-fields-terminated-by
--input-lines-terminated-by
输出格式化参数:
--enclosed-by
--escaped-by
--fields-terminated-by
--lines-terminated-by
--mysql-delimiters:使用mysql默认的分隔符,fields:, lines: \n escaped-by: \
#如果在hive表中该字段是字符串且为NULL,然后理解成为NULL而不是\N
--input-null-string
#如果在hive表中该字段是非字符串类型且为NULL,然后理解成为NULL而不是\N
--input-null-non-string
sqoopexport \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--drivercom.mysql.jdbc.Driver \
--export-dir/user/hive/warehouse/hadoop.db/m_d \
--columns"id,country,city,phone" \
--tabledirector \
--num-mappers2 \
--direct\
--input-fields-terminated-by',' \
--input-null-string'\\N' \
--input-null-non-string'\\N'
3.4.2Hive数据导入到RMDBS表
这个其实跟HDFS数据导入到RMDBS表一样,因为数据就是存储在HDFS上的
3.5import HDFS从RMDBS导入数据
import语法:
sqoop import \
--connect
--username
--password
--target-dir
--table
--as-textfile# 导入为文本文件
--as-avrodatafile#导入为avro文件
--as-sequencefile#导入为序列化文件
--as-parquetfile#导入为parquet文件
--columns
--delete-target-dir如果目标目录存在则删除
-m设置多少个mapper并发
-e|--query执行查询的sql语句
--WHERE可以进一步对查询语句过滤
-z|--compress启用压缩
--compression-codec:指定压缩类型,默认gzip
--null-string
--null-non-string
增量导入
--check-column(col) : 对哪一列进行检查,决定那些行被导入
--incremental(mode):append|lastmodified定义增量判断类型,是新增的算增量还是最近修改的算增量
--last-value
格式输出参数:
--enclosed-by
--escaped-by
--fields-terminated-by
--lines-terminated-by
--mysql-delimiters:使用mysql默认的分隔符,fields:, lines: \n escaped-by: \
解析输入参数:
--input-enclosed-by
--input-escaped-by
--input-fields-terminated-by
--input-lines-terminated-by
导入RMDBS数据到Hive 参数:
--create-hive-table:如果目标表存在,则失败
--hive-database
--hive-import表示将数据导入hive表
--hive-overwrite:hive表存在数据则覆盖
--hive-partition-key
--hive-partition-value
--hive-table
3.5.1 从关系型数据库导入:
sqoop import \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--target-dir/user/hive/warehouse/hadoop.db/t_emp \
--tableemp \
--as-textfile\
--delete-target-dir\
--fields-terminated-by',' \
--lines-terminated-by'\n' \
--null-string'NULL' \
--null-non-string0
在hive创建表:
CREATETABLE IF NOT EXISTS t_emp(
empnoINT,
enameSTRING,
jobSTRING,
mgrINT,
hiredateSTRING,
salFLOAT,
commFLOAT,
deptnoINT,
dnameSTRING,
locSTRING
)
ROWFORMAT DELIMITED FIELDS TERMINATED BY ',';
导入从MySQL导入到HDFS数据到Hive表
LOAD DATA INPATH '/user/hive/warehouse/hadoop.db/t_emp' INTO TABLE t_emp;
SELECT* FROM t_emp;

3.5.2 从关系型数据库导入数据到HDFS, 选择列
sqoop import \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--columns"empno,ename,dname,loc" \
--target-dir/user/hive/warehouse/hadoop.db/column_emp \
--tableemp \
--as-textfile\
--delete-target-dir\
--fields-terminated-by',' \
--lines-terminated-by'\n' \
--null-string'NULL' \
--null-non-string0
CREATETABLE IF NOT EXISTS column_emp(
empnoINT,
enameSTRING,
dnameSTRING,
locSTRING
)
ROWFORMAT DELIMITED FIELDS TERMINATED BY ','
LOADDATA INPATH '/user/hive/warehouse/hadoop.db/column_emp' INTO TABLE column_emp;
SELECT* FROM column_emp;

3.5.3 从关系型数据库导入数据到HDFS, 使用avro文件
sqoopimport \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--columns"empno,ename,dname,loc" \
--target-dir/user/hive/warehouse/hadoop.db/column_emp \
--tableemp \
--as-avrodatafile\
--delete-target-dir\
--fields-terminated-by',' \
--lines-terminated-by'\n' \
--null-string'NULL' \
--null-non-string0
在hive创建表:
CREATETABLE IF NOT EXISTS column_emp(
empnoINT,
enameSTRING,
dnameSTRING,
locSTRING
)
ROWFORMAT DELIMITED FIELDS TERMINATED BY ','
STOREDAS avro;
导入hdfs数据到hive表column_emp:
LOADDATA INPATH '/user/hive/warehouse/hadoop.db/column_emp' INTO TABLE column_emp;
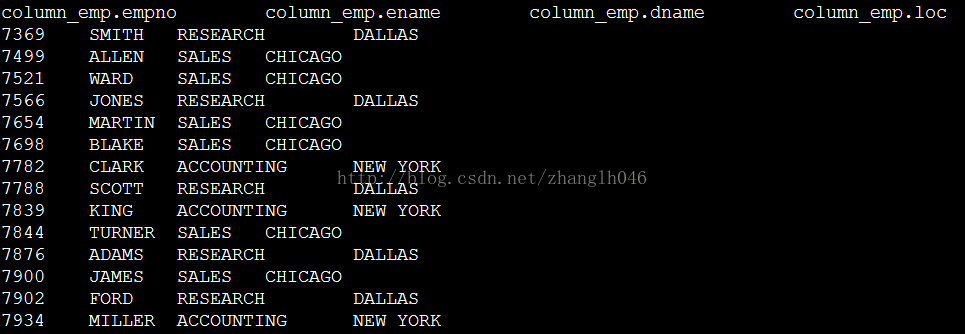
注意:
1sqoop 本身不支持RMDBS 导入数据到HDFS以ORCFile或者RCFile格式存储,只支持textfile,sequencefile,avro,parquet格式。
那如果这种情况怎么办呢?
方法一:先将数据以textfile格式存储到HDFS,临时表读取数据,然后再创建ORC的表存入
方法二:使用HCatalog,还没有深入研究过HCatalog
sqoopimport
--connectjdbc:postgresql://foobar:5432/my_db
--driverorg.postgresql.Driver
--connection-managerorg.apache.sqoop.manager.GenericJdbcManager
--usernamefoo
--password-filehdfs:///user/foobar/foo.txt
--tablefact
--hcatalog-home/usr/hdp/current/hive-webhcat
--hcatalog-databasemy_hcat_db
--hcatalog-tablefact
--create-hcatalog-table
--hcatalog-storage-stanza'stored as orc tblproperties ("orc.compress"="SNAPPY")'
注意二: 如果想使用parquet存储文件,我们必须使用hive-table
因为sqoop 导入RMDBS数据以parquet格式存储,使用KiteSDK去写parquet文件,所以我们直接导入hive比较好
另外parquet只支持snappy压缩,GZIP它是不支持的。
3.5.4 导入数据到hive表
sqoopimport \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--hive-import\
--create-hive-table\
--tableemployee \
--hive-overwrite\
--fields-terminated-by"," \
--lines-terminated-by"\n" \
--hive-tablehadoop.employee
--hive-import: 表示导入导入到hive
--table:从关系型数据库哪一张表导入到hive,并且导入到的hdfs路径下不能包含这个名字,否则提示表已存在。原因在于他是先导入到hdfs的,在通过hive 的loaddata导入hive中去
--hive-overwrite:如果表已经存在,则覆盖数据,一般情况下,不会存在,如果有这个表,在导入的时候就会报错
--hive-table:导入到hive什么数据库的哪一张表,如果不指定数据库或者压根不指定这个参数,那么久会导入到default数据库下,默认表名和RMDBS的表名一样
3.5.5 增量导入
--check-column
--incremental
sqoop支持2种方式的增量导入:
第一种:append根据lastvalue然后进行追加导入
第二种:lastmodified根据上次的修改时间,增量导入
--last-value
但是需要注意,如果增量导入。我们不能删除之前的目录,即不能使用--delete-target-dir。
首先确保RMDBS里的表和hive的表数据一致,方便我们观察:
然后在RMDBS里面添加几条数据
INSERTINTO employee VALUES (7935,'NICKY','Endeca',7698,'2014-12-1',5500,800,50,'DELIVERY','CHENGDU');
INSERTINTO employee VALUES (7936,'ALLEN','BUSINESS',7698,
'2013-1-15',4500,200,50,'DELIVERY','CHENGDU');
INSERTINTO employee VALUES (7937,'Britney','TESTER',7698,'2016-2-1',4000,100,50,'DELIVERY','CHENGDU');
第一种方式:append 类型增量导入
sqoopimport \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--hive-import\
--tableemployee \
--hive-tablehadoop.employee \
--check-columnempno \
--incrementalappend \
--last-value7934 \
--fields-terminated-by"\t" \
--lines-terminated-by"\n"
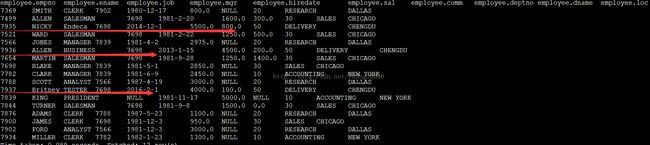
第二种方式:lastmodified增量导入
这种导入方式就需要有一列是lastmodified来更新每一次操作的时间,然后sqoop再根据这一列来进行检查判断是否是新增数据
我们这一次只是对HDFS文件进行增量导入,不去导入hive里了
INSERTINTO book VALUES(14,'RabbitMQEssential', 'Gabriele Santomaggio', '2016-11-6', 'MQ',44.34);
./sqoopimport \
--connectjdbc:mysql://hadoop09-linux:3306/sqoop \
--usernameroot \
--password123456 \
--tablebook \
--check-columnpub_time \
--incrementallastmodified \
--last-value'2016-11-1' \
--target-dir/user/hadoop/book \
--direct\
--append\
-m1 \
--fields-terminated-by'\t'
3.5.6导入所有表
使用如下命令导入所有表。sqoop会一次导入每张表,以避免对数据库服务器造成额外的负担。
sqoopimport-all-tables \
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamesqoop \
--passwordsqoop
在metastore中保存密码
很不幸,每次使用sqoopjob执行任务都需要手动输入密码。
解决方式有两种:
第一种方式,使用password-file(“导入”一章中有介绍);
第二种方式,在sqoop-site.xml中添加如下属性即可(添加后第一次仍然需要输入密码 )。
客户端之间共享metastore
sqoopjob
--createvisits \
--meta-connect\
jdbc:hsqldb:hsql://metastore.example.com:16000/sqoop\
--\
import\
--tablevisits
...
四 sqoopjob & metastore
导入导出可能是一个重复性的工作,尤其是增量导入,可能每天都会进行,这是一件很烦的事情。而且对于增量导入,我们每一次执行都需要知道last-value是什么。
我们使用job之后,我们可以执行这个job并且会自动更新last-value,sqoop-job里面会每次记录这个incremental.last.valu。比如上一次incremental.last.value=1000,做完一次同步之后,下一次执行这个job,这个值就是新的最后一条记录的值
Metastore: 主要是用于配置sqoop共享元数据信息,这样多个用户或者远程用户也可以定义和执行job. 默认情况先,sqoop的job信息是存储在~/.sqoop目录下,如果配置了metastore那么就可以使用一个共享的metastore。
4.1 创建一个job
sqoop-job--create order_incr_job --import \
--connectjdbc:mysql://hadoop09-linux:3306/sqoop \
--usernameroot \
--password123456 \
--tablebook \
--check-columnpub_time \
--incrementallastmodified \
--last-value'2016-11-1' \
--target-dir/user/hadoop/book \
--direct\
--append\
-m1 \
--fields-terminated-by'\t'
4.2 删除一个job
sqoop-job--delete order_incr_job
4.3 执行一个job
sqoop-job--exec order_incr_job
4.4 查看job参数
Sqoop-job--show
Sqoopmetastore不是一个安全的资源,多个用户都能访问他的内容,因此sqoop不会存储密码在metastore里面。如果你创建一个job需要密码,你可以每次在执行的时候给他提供。
解决每次使用sqoopjob执行任务都需要手动输入密码,你可以在sqoop-site里面加上如下配置:
sqoop.metastore.client.record.password= true
案例:
sqoop-job--meta-connect jdbc:hsqldb:hsql://hadoop-all-02:16000/sqoop --create emp_job \
--\
import\
--connectjdbc:mysql://hadoop-all-01:3306/hadoop \
--usernamehive \
--passwordhive \
--hive-import\
--tableemployee \
--hive-tablehadoop.employee \
--check-columnempno \
--incrementalappend \
--last-value7937 \
--fields-terminated-by'\t' \
--lines-terminated-by'\n'
sqoop-job--meta-connect jdbc:hsqldb:hsql://hadoop-all-02:16000/sqoop --exec emp_job \
五 安全
保护密码
在sqoop命令中显式指定密码会是很不安全的操作,使用操作系统的列出正在执行的命令的方式可以很容易的获取到密码。有两种方式可以解决这个问题。
方式一:使用-P(大写)参数,在执行命令时再输入密码。
方式二:使用--password-file参数,即将密码存放在参数指定的文件中。
提高传输速度
不同于JDBC接口,direct模式下使用数据库提供的本地工具进行数据传输。在MySQL中使用mysqldump和mysqlimport。对于PostgreSQL,sqoop会使用pg_dump工具来导入数据。使用本地工具会极大提高性能,因为他们针对数据传输做了优化,以降低数据库服务器的负担。当然也有很多限制,比如并不是所有的数据库都提供本地工具。目前sqoop的direct模式只支持MySQL和PostgreSQL。
六merge
Sqoopmerge主要是用于将不同的目录下面数据结合在一起,并存放在指定目录
--new-data
--onto
--merge-key
--jar-file
--class-name
--target-dir