散列表(三):冲突处理的方法之开地址法(线性探测再散列的实现)
二、开地址法
基本思想:当关键码key的哈希地址H0 = hash(key)出现冲突时,以H0为基础,产生另一个哈希地址H1 ,如果H1仍然冲突,再以H0
为基础,产生另一个哈希地址H2 ,…,直到找出一个不冲突的哈希地址Hi ,将相应元素存入其中。这种方法有一个通用的再散列函
数形式:
其中H0 为hash(key) ,m为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下四种:
线性探测再散列
二次探测再散列
伪随机探测再散列
双散列法
(一)、线性探测再散列

假设给出一组表项,它们的关键码为 Burke, Ekers, Broad, Blum, Attlee, Alton, Hecht, Ederly。采用的散列函数是:取其第一个字母在
字母表中的位置。
hash (x) = ord (x) - ord (‘A’)
这样,可得
hash (Burke) = 1hash (Ekers) = 4
hash (Broad) = 1hash (Blum) = 1
hash (Attlee) = 0hash (Hecht) = 7
hash (Alton) = 0hash (Ederly) = 4
又设散列表为HT[26],m = 26。采用线性探查法处理溢出,则上述关键码在散列表中散列位置如图所示。红色括号内的数字表示找
到空桶时的探测次数。比如轮到放置Blum 的时候,探测位置1,被占据,接着向下探测位置2还是不行,最后放置在位置3,总的探
测次数是3。

堆积现象
散列地址不同的结点争夺同一个后继散列地址的现象称为堆积(Clustering),比如ALton 本来位置是0,直到探测了6次才找到合适位
置5。这将造成不是同义词的结点也处在同一个探测序列中,从而增加了探测序列长度,即增加了查找时间。若散列函数不好、或装
填因子a 过大,都会使堆积现象加剧。
下面给出具体的实现代码,大体跟前面讲过的链地址法差异不大,只是利用的结构不同,如下:
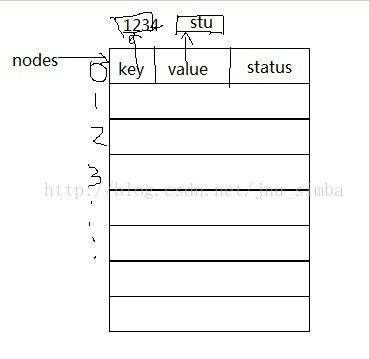
status 保存状态,有EMPTY, DELETED, ACTIVE,删除的时候只是逻辑删除,即将状态置为DELETED,当插入新的key 时,只要不
是ACTIVE 的位置都是可以放入,如果是DELETED位置,需要将原来元素先释放free掉,再插入。
common.h:
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#ifndef_COMMON_H_
#define_COMMON_H_ #include #include #include #include #include #defineERR_EXIT(m)\ do\ {\ perror(m);\ exit(EXIT_FAILURE);\ }\ while( 0) #endif |
hash.h:
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#ifndef_HASH_H_
#define_HASH_H_ typedef structhashhash_t; typedef unsigned int(*hashfunc_t)( unsigned int, void*); hash_t*hash_alloc( unsigned intbuckets,hashfunc_thash_func); voidhash_free(hash_t*hash); void*hash_lookup_entry(hash_t*hash, void*key, unsigned intkey_size); voidhash_add_entry(hash_t*hash, void*key, unsigned intkey_size, void*value, unsigned intvalue_size); voidhash_free_entry(hash_t*hash, void*key, unsigned intkey_size); #endif /*_HASH_H_*/ |
hash.c:
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
#include
"hash.h"
#include "common.h" #include typedef enumentry_status { EMPTY, ACTIVE, DELETED }entry_status_t; typedef structhash_node { enumentry_statusstatus; void*key; void*value; }hash_node_t; structhash { unsigned intbuckets; hashfunc_thash_func; hash_node_t*nodes; }; unsigned inthash_get_bucket(hash_t*hash, void*key); hash_node_t*hash_get_node_by_key(hash_t*hash, void*key, unsigned intkey_size); hash_t*hash_alloc( unsigned intbuckets,hashfunc_thash_func) { hash_t*hash=(hash_t*)malloc( sizeof(hash_t)); //assert(hash!=NULL); hash->buckets=buckets; hash->hash_func=hash_func; intsize=buckets* sizeof(hash_node_t); hash->nodes=(hash_node_t*)malloc(size); memset(hash->nodes, 0,size); printf( "Thehashtablehasallocate.\n"); returnhash; } voidhash_free(hash_t*hash) { unsigned intbuckets=hash->buckets; inti; for(i= 0;i if(hash->nodes[i].status!=EMPTY) { free(hash->nodes[i].key); free(hash->nodes[i].value); } } free(hash->nodes); printf( "Thehashtablehasfree.\n"); } void*hash_lookup_entry(hash_t*hash, void*key, unsigned intkey_size) { hash_node_t*node=hash_get_node_by_key(hash,key,key_size); if(node== NULL) { return NULL; } returnnode->value; } voidhash_add_entry(hash_t*hash, void*key, unsigned intkey_size, void*value, unsigned intvalue_size) { if(hash_lookup_entry(hash,key,key_size)) { fprintf(stderr, "duplicatehashkey\n"); return; } unsigned intbucket=hash_get_bucket(hash,key); unsigned inti=bucket; //找到的位置已经有人存活,向下探测 while(hash->nodes[i].status==ACTIVE) { i=(i+ 1)%hash->buckets; if(i==bucket) { //没找到,并且表满 return; } } hash->nodes[i].status=ACTIVE; if(hash->nodes[i].key) //释放原来被逻辑删除的项的内存 { free(hash->nodes[i].key); } hash->nodes[i].key=malloc(key_size); memcpy(hash->nodes[i].key,key,key_size); if(hash->nodes[i].value) //释放原来被逻辑删除的项的内存 { free(hash->nodes[i].value); } hash->nodes[i].value=malloc(value_size); memcpy(hash->nodes[i].value,value,value_size); } voidhash_free_entry(hash_t*hash, void*key, unsigned intkey_size) { hash_node_t*node=hash_get_node_by_key(hash,key,key_size); if(node== NULL) return; //逻辑删除,置标志位 node->status=DELETED; } unsigned inthash_get_bucket(hash_t*hash, void*key) { //返回哈希地址 unsigned intbucket=hash->hash_func(hash->buckets,key); if(bucket>=hash->buckets) { fprintf(stderr, "badbucketlookup\n"); exit(EXIT_FAILURE); } returnbucket; } hash_node_t*hash_get_node_by_key(hash_t*hash, void*key, unsigned intkey_size) { unsigned intbucket=hash_get_bucket(hash,key); unsigned inti=bucket; while(hash->nodes[i].status!=EMPTY&&memcmp(key,hash->nodes[i].key,key_size)!= 0) { i=(i+ 1)%hash->buckets; if(i==bucket) //探测了一圈 { //没找到,并且表满 return NULL; } } //比对正确,还得确认是否还存活 if(hash->nodes[i].status==ACTIVE) { return&(hash->nodes[i]); } //如果运行到这里,说明i为空位或已被删除 return NULL; } |
main.c:
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
#include
"hash.h"
#include "common.h" typedef structstu { charsno[ 5]; charname[ 32]; intage; }stu_t; typedef structstu2 { intsno; charname[ 32]; intage; }stu2_t; unsigned inthash_str( unsigned intbuckets, void*key) { char*sno=( char*)key; unsigned intindex= 0; while(*sno) { index=*sno+ 4*index; sno++; } returnindex%buckets; } unsigned inthash_int( unsigned intbuckets, void*key) { int*sno=( int*)key; return(*sno)%buckets; } intmain( void) { stu2_tstu_arr[]= { { 1234, "AAAA", 20}, { 4568, "BBBB", 23}, { 6729, "AAAA", 19} }; hash_t*hash=hash_alloc( 256,hash_int); intsize= sizeof(stu_arr)/ sizeof(stu_arr[ 0]); inti; for(i= 0;i hash_add_entry(hash,&(stu_arr[i].sno), sizeof(stu_arr[i].sno), &stu_arr[i], sizeof(stu_arr[i])); } intsno= 4568; stu2_t*s=(stu2_t*)hash_lookup_entry(hash,&sno, sizeof(sno)); if(s) { printf( "%d%s%d\n",s->sno,s->name,s->age); } else { printf( "notfound\n"); } sno= 1234; hash_free_entry(hash,&sno, sizeof(sno)); s=(stu2_t*)hash_lookup_entry(hash,&sno, sizeof(sno)); if(s) { printf( "%d%s%d\n",s->sno,s->name,s->age); } else { printf( "notfound\n"); } hash_free(hash); return 0; } |
simba@ubuntu:~/Documents/code/struct_algorithm/search/hash_table/linear_probing$ ./main
The hash table has allocate.
4568 BBBB 23
not found
The hash table has free.
与链地址法示例还有一点不同,就是key 使用的是int 类型,所以必须再实现一个hash_int 哈希函数,根据key 产生哈希地址。